Clear Sky Science · sv
Omvändt designade nanofotoniska neurala nätverksacceleratorer för ultrakompakt optisk beräkning
Varför det spelar roll att krympa datorer gjorda av ljus
Modern artificiell intelligens körs på omfattande elektronisk hårdvara som förbrukar enorma mängder energi och alstrar värme. Denna studie utforskar en mycket annorlunda väg: att använda små mönster av ljus på en kiselplatta, istället för strömmar av elektroner, för att utföra delar av neurala nätverksberäkningar. Författarna visar att genom att ”skulptera” ljus i nanoskala kan de bygga ultrakompakta optiska acceleratorer som känner igen handskrivna siffror och medicinska bilder samtidigt som de använder avsevärt mindre utrymme och i princip betydligt mindre energi än dagens elektronik.
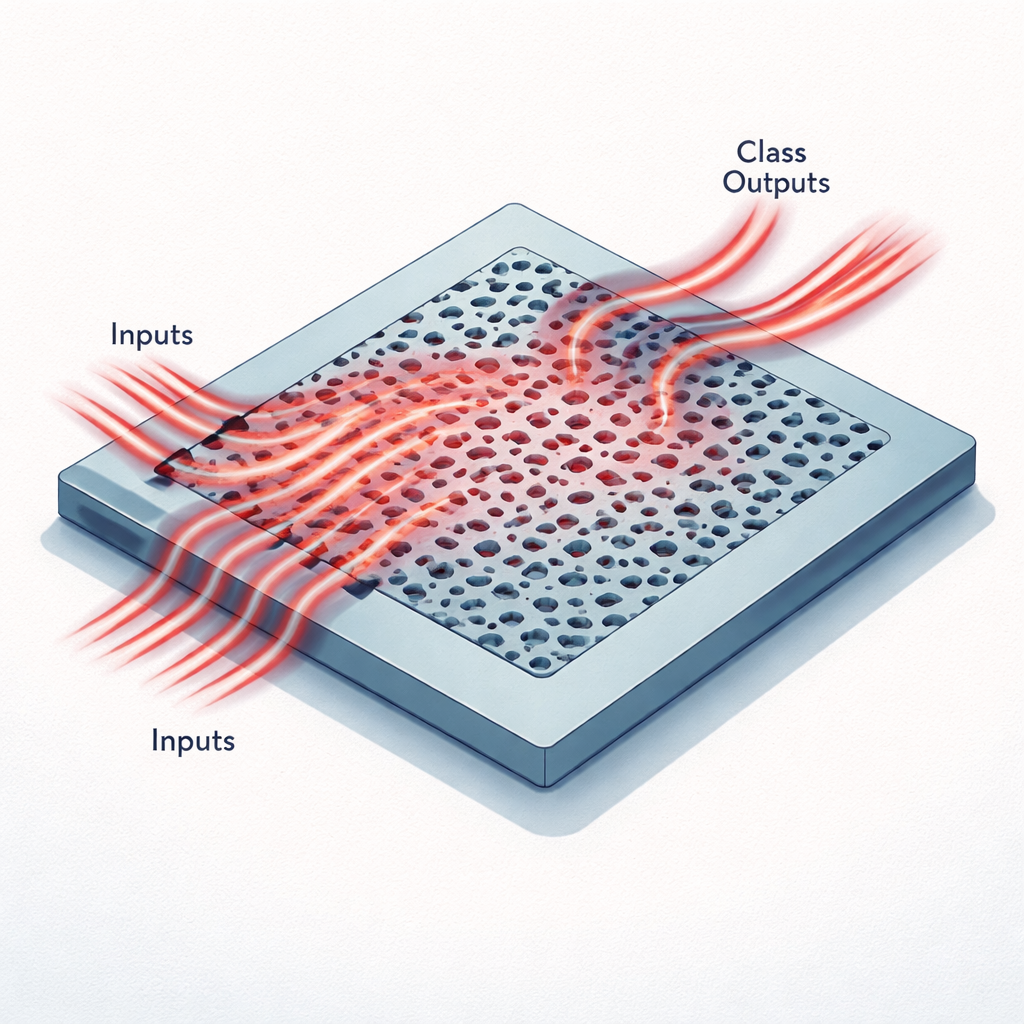
Små chip som tänker med ljus
I stället för ledningar och transistorer använder dessa acceleratorer ett plant stycke kisel mönstrat med hål och kanaler som är mindre än våglängden för infrarött ljus. Data från en bild komprimeras först till en liten uppsättning tal, som sedan kodas som ljusstyrkan hos ljus som går in i flera smala vågledare vid en enda telekomvåglängd. När detta ljus flödar in i det mönstrade området blir det spritt, interfererar med sig självt och styrs om mot ett fåtal utgångsvågledare. Varje utgång motsvarar en möjlig klass, till exempel en av tio siffror i MNIST-datasetet eller en av sex kategorier i en medicinsk bildsats kallad MedNIST. Mönstret av optisk effekt vid utgångarna spelar samma roll som det sista lagret i ett digitalt neuralt nätverk.
Låta algoritmer rita den optiska ritningen
Att designa en sådan struktur för hand vore nästan omöjligt, eftersom varje litet ”voxel” av material kan ändra hur ljuset rör sig. Forskarnas strategi är istället en omvänd‑designmetod: de börjar från ett slumpmässigt mönster av kisel och glas, simulerar hur ljus propagerar genom det i tre dimensioner och justerar sedan mönstret för att minska en förlustfunktion som mäter klassificeringsfel. De utnyttjar Maxwell‑ekvationernas linearitet—de lagar som styr ljus—för att göra denna träning effektiv. I stället för att simulera varje träningsbild separat simulerar de varje ingångskanal en gång och rekonstruerar sedan fälten för alla bilder som linjära kombinationer av dessa förberäknade fält. En matematisk teknik kallad adjunktmetoden ger därefter exakta gradienter som talar om för algoritmen hur varje voxel ska justeras för att förbättra prestandan.

Kompakta bildklassificerare på ett sandkorn
Med denna strategi designade teamet två nanofotoniska neurala nätverksacceleratorer på en standard plattform för kisel‑på‑isolator. Den ena, endast 20 gånger 20 mikrometer i yta, klassificerar handskrivna siffror från MNIST‑datasetet; den andra, 30 gånger 20 mikrometer, klassificerar medicinska bilder från MedNIST. I simuleringar uppnådde dessa små enheter noggrannheter på 97,8 % respektive 99,1 %. Fabrikerade versioner av samma designer, testade med riktiga lasrar och detektorer, nådde 89 % noggrannhet för MNIST och 90 % för MedNIST—anmärkningsvärda siffror med tanke på chippens ringa storlek. De optiska strukturerna packar ungefär 160 000 till 240 000 träningsbara parametrar i områden mindre än ett dammkorn, vilket motsvarar omkring 400 miljoner parametrar per kvadratmillimeter.
Byggda för hastighet, effektivitet och skalbarhet
Eftersom enheterna är passiva—det finns inga rörliga delar eller omprogrammerbara element under inferens—behöver de ingen kontinuerlig justering efter tillverkning. Neuralnätets ”vikter” är hårdkodade i nanostrukturens geometri, så beräkningen sker i ljusets hastighet med i princip minnesnära bearbetning: ljuset går in med kodad data och kommer ut redan blandat till klasspoäng. Träningsmetoden är också utformad för att vara skalbar. Varje optimeringssteg kräver endast ett fast antal fullfysiksimuleringar bestämt av antalet ingångar och utgångar, inte av datasetets storlek, och dessa simuleringar kan distribueras över flera grafikkort. Författarna beskriver dessutom hur flera sådana optiska kärnor kan staplas med fotodetektorer mellan dem, ungefär som lager i ett djupt neuralt nätverk, och hur multiplexering i våglängd eller tid kan öka genomströmningen.
Vad detta betyder för framtidens AI‑hårdvara
Enkelt uttryckt visar detta arbete att det är möjligt att ”odla” skräddarsydda delar av glas och kisel som beter sig som specialiserade neurala nätverkslager, allt inom en yta tillräckligt liten för att rymma hundratals eller tusentals av dem på ett enda chip. Medan fullständigt optiska datorer fortfarande ligger i framtiden kan dessa omvändt designade nanofotoniska acceleratorer avlasta några av de mest energikrävande delarna av AI‑arbetsbelastningar från elektroniska processorer. Om de kombineras med snabba modulatorer, detektorer och intelligent systemdesign pekar de mot kompakt, lågströms hårdvara där ljus—snarare än enbart elektricitet—utför mycket av det tunga lyftet inom maskininlärning.
Citering: Sved, J., Song, S., Li, L. et al. Inverse-designed nanophotonic neural network accelerators for ultra-compact optical computing. Nat Commun 17, 1059 (2026). https://doi.org/10.1038/s41467-026-68648-1
Nyckelord: fotonska neurala nätverk, nanofotonik, optisk beräkning, hårdvaruakceleratorer, omvänd design