Clear Sky Science · sv
Genomiskt språkmodell mildrar chimära artefakter i nanopore direkt-RNA-sekvensering
Varför det spelar roll att rensa upp RNA-reads
Våra celler läser ständigt genetiska instruktioner skrivna i RNA, och nya sekvenseringstekniker låter forskare numera observera denna process med en enastående detaljrikedom. Ett av de kraftfullaste verktygen, nanopore direkt-RNA-sekvensering, kan läsa hela RNA-molekyler i ett enda svep—men tekniken introducerar också fel som kan få det att se ut som om gener brutits och sydds ihop på sätt som aldrig sker i verkligheten. Denna studie presenterar DeepChopper, ett program som fungerar som en språkmodell för genomet och rensar bort dessa fel så att forskare kan lita på vad de ser i RNA-data.
När sekvenseraren hittar på falska genblandningar
Moderna nanopore-maskiner drar individuella RNA-strängar genom mycket små porer och läser deras sekvens direkt. Det har stora fördelar jämfört med äldre metoder, som att bevara kemiska modifieringar och fånga fullängds-transkript i ett enda read. Men processen förlitar sig också på korta hjälpfragment kallade adaptrar som fästs vid RNA-molekyler under biblioteksberedningen. Ibland kopplas två eller flera RNA-molekyler av misstag ihop av dessa adaptrar, vilket skapar vad som ser ut som chimärer—hybridmolekyler som verkar förena olika gener. Standardanalysverktyg kan misstolka dessa tekniska rester som verkliga biologiska händelser, till exempel cancerrelaterade genfusioner eller ovanliga splitsningsmönster, vilket ger missledande resultat.
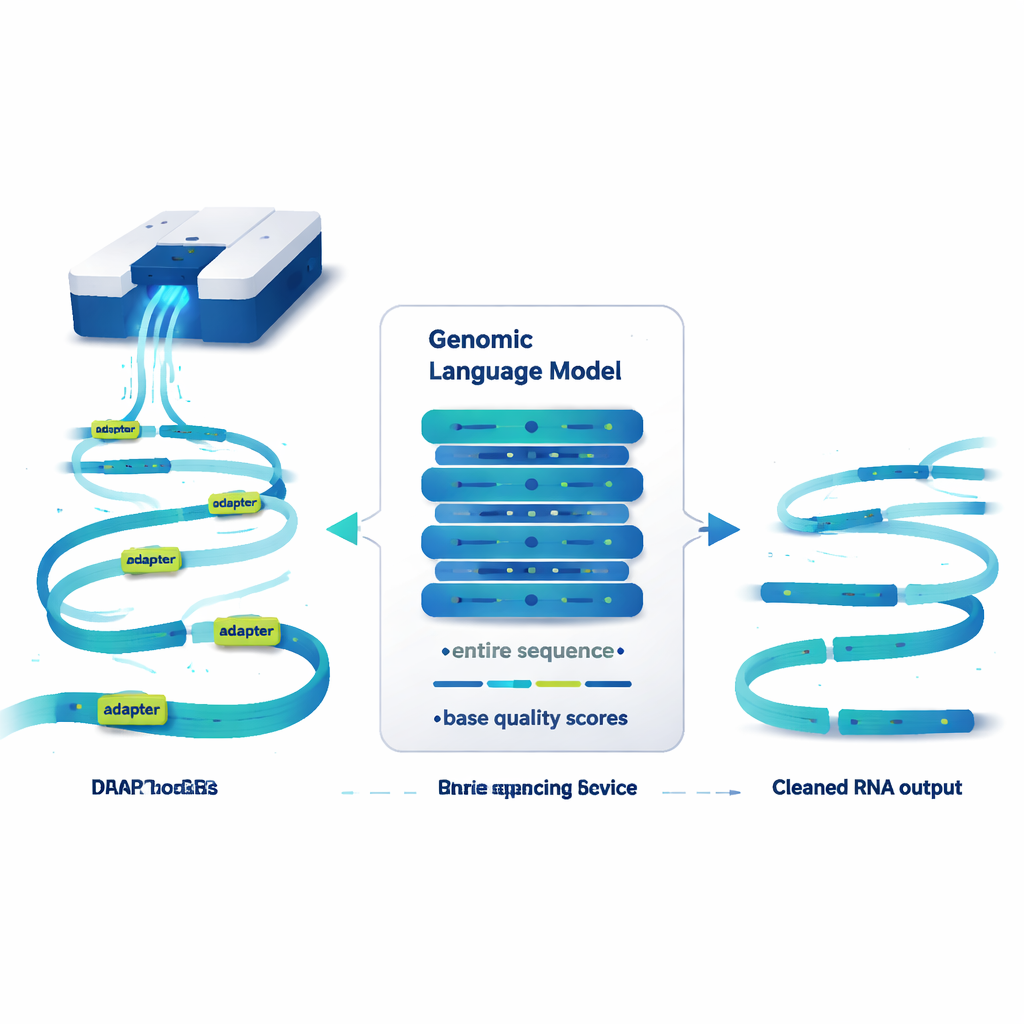
En språkmodell som läser genom, inte meningar
DeepChopper behandlar genetiska sekvenser lite som text och tillämpar idéer från stora språkmodeller på dem. Istället för ord läser den RNA-sekvenser bokstav för bokstav, tillsammans med en kvalitetspoäng för varje bas som anger hur tillförlitligt readet är. Byggd på en kompakt arkitektur kallad HyenaDNA kan den skanna upp till 32 000 baser åt gången—långt nog att täcka i princip vilket mänskligt RNA som helst. För varje position uppskattar DeepChopper om basen är del av en genuin RNA-sekvens eller en adapter. Ett förfiningssteg jämnar sedan ut dessa prediktioner så att adaptrar markeras som kontinuerliga block istället för utspridda punkter.
Skära bort de dåliga kopplingarna utan att kasta bort data
När DeepChopper hittat adaptrar i ett read gör den något avgörande: istället för att kassera hela readet "hackar" den vid adapterplatserna och behåller de verkliga bitarna. På så sätt kan en artificiell fusion av två RNA återdelas till sina ursprungliga delar. I tester på miljontals nanopore-reads från flera humana cancercellinjer och stamceller överträffade DeepChopper vida de befintliga adapter-trimningsverktygen, som aldrig var utformade för denna direkt-RNA-inställning. Den kände igen adaptrar med över 99 % precision och återkallning i syntetiska benchmarks, och den skalade effektivt till dataset med mer än 20 miljoner reads med hjälp av grafikprocessorer.
Separera verkliga genfusioner från sekvenseringsillusioner
Författarna undrade sedan om DeepChopper kunde skilja verkliga biologiska händelser från artefakter i äkta cancerdata. Genom att jämföra direkt-RNA-reads med motsvarande dataset producerade av oberoende metoder (såsom direkt cDNA-sekvensering på både Oxford Nanopore och PacBio) kunde de märka vilka till synes chimära reads som stöddes av andra tekniker och vilka som inte gjorde det. DeepChopper minskade icke-stödda chimära alignments med så mycket som 62–91 %, samtidigt som andelen som bekräftades av andra metoder ökade kraftigt. Det minskade också antalet misstänkta genfusion—anrop med nästan 90 %, särskilt de som involverade ribosomala gener som visade sig vara frekventa artefakter. Samtidigt bevarades verkliga fusionshändelser som stödjades av short-read RNA-sekvensering.
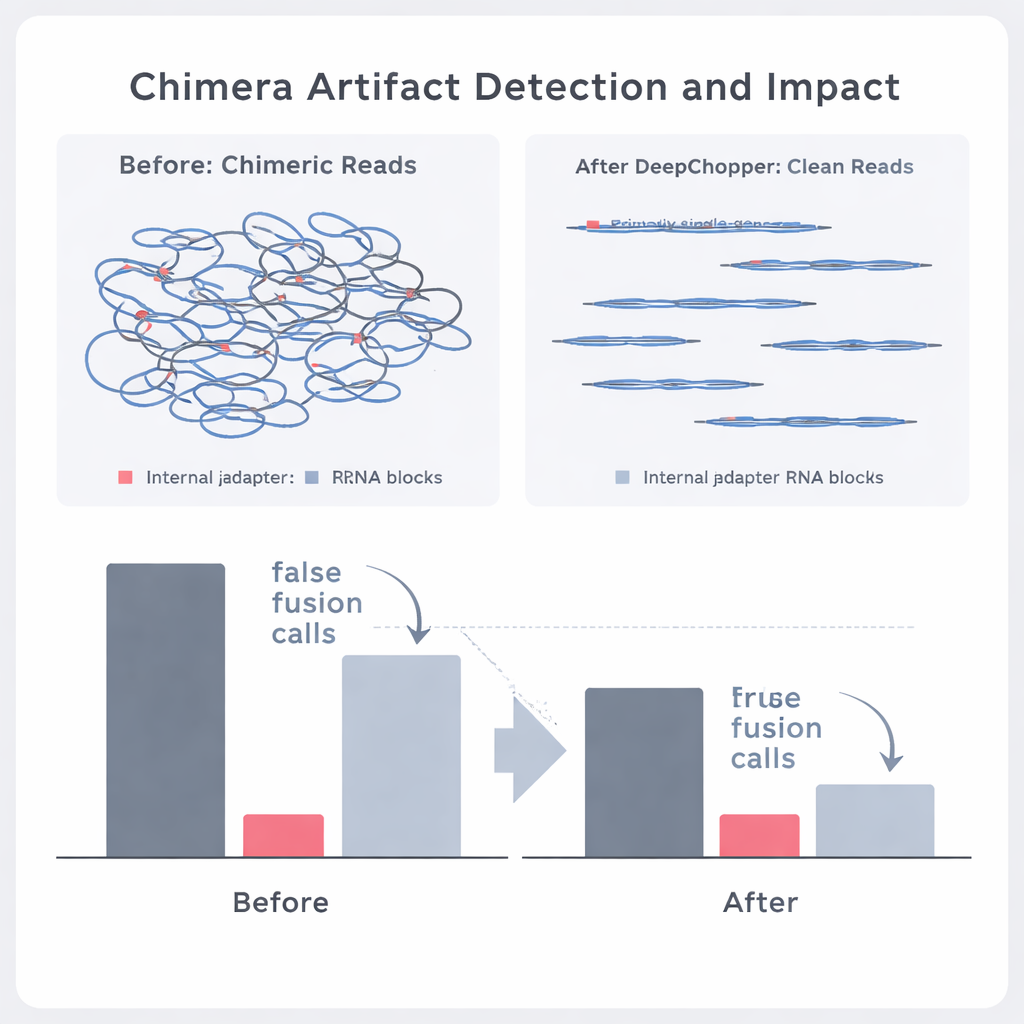
Bättre kemi hjälper—men artefakter kvarstår
Oxford Nanopore släppte nyligen ett uppdaterat sekvenseringskit (RNA004) utformat delvis för att minska tekniska artefakter. DeepChopper applicerades först "direkt ur lådan" på data från denna nya kemi och fann ändå att en liten men viktig andel reads innehöll interna adaptrar och chimära kopplingar. Även utan extra träning minskade modellen de artefaktiva chimärerna med ungefär en femtedel; efter finjustering på den nya datan presterade den något bättre, samtidigt som genuina signaler lämnades intakta. Över alla kemier och celltyper gjorde korrigering av dessa artefakter att efterföljande verktyg kunde upptäcka betydligt fler fullängds- och alternativa transkript, vilket gav en tydligare bild av cellens RNA-landskap.
Vad detta betyder för framtida RNA-studier
För icke-specialister är huvudbudskapet att inte varje överraskande RNA-koppling som rapporteras av en sekvenserare är verklig biologi—vissa är kabelkopplingsfel införda av tekniken själv. DeepChopper fungerar som en högt utbildad korrekturläsare för nanopore-RNA-data, identifierar de karakteristiska adaptersekvenserna som förenar orelaterade molekyler och skär bort dem med enbasprecisionsnoggrannhet. Resultatet är renare, mer tillförlitliga kartor över vilka RNA-molekyler som finns i en cell och hur de är sammansatta. När laboratorier i allt högre grad förlitar sig på long-read RNA-sekvensering för att studera cancer, hjärnsjukdomar och andra komplexa sjukdomar kommer verktyg som DeepChopper vara avgörande för att omvandla brusiga råa reads till pålitlig biologisk insikt.
Citering: Li, Y., Wang, TY., Guo, Q. et al. Genomic language model mitigates chimera artifacts in nanopore direct RNA sequencing. Nat Commun 17, 1864 (2026). https://doi.org/10.1038/s41467-026-68571-5
Nyckelord: nanopore RNA-sekvensering, chimära reads, genfusion-artefakter, genomisk språkmodell, DeepChopper