Clear Sky Science · sv
Tre öppna frågor om bärbarheten hos polygena poäng
Varför det är svårare än det verkar att förutsäga hälsa från DNA
Läkare och forskare hoppas i allt större utsträckning kunna använda DNA-baserade "polygena poäng" för att förutsäga en persons risk för vanliga tillstånd som diabetes, hjärtsjukdom eller astma. Men dessa poäng fungerar ofta bra endast hos personer som liknar de ursprungliga studiedeltagarna, vanligen av europeiskt ursprung. Denna artikel undersöker varför dessa prediktioner inte "reser" på ett tillförlitligt sätt till människor med annorlunda genetisk bakgrund eller livsomständigheter, och vad det innebär för att använda genetiska riskpoäng rättvist inom vården.
Vad polygena poäng lovar — och var de brister
Polygena poäng kombinerar de små effekterna från många genetiska varianter över genomet till ett enda tal avsett att förutsäga ett drag, såsom längd eller blodtryck. De byggs upp från mycket stora genomomfattande associationsstudier (GWAS) som kopplar DNA-markörer till egenskaper hos hundratusentals frivilliga. När dessa poäng dock tillämpas på nya grupper av människor varierar deras noggrannhet dramatiskt. Vanligen blir prediktionen sämre ju mer den nya gruppen skiljer sig genetiskt eller socialt från de ursprungliga GWAS-deltagarna. Detta är känt som bärbarhetsproblemet: en poäng som fungerar i ett sammanhang kan vilseleda i ett annat, och riskera att fördjupa hälsoskillnader om den används okritiskt.
Se bortom ursprung: avstånd på den genetiska kartan
För att undersöka problemet använde författarna data från UK Biobank, som innehåller genetisk och hälsoinformation från över 400 000 personer. De byggde polygena poäng för 15 starkt ärftliga egenskaper, såsom längd, vikt, blodcellsantal och kolesterolnivåer, baserat på en stor grupp mestadels vitt brittiska deltagare. Därefter testade de hur väl dessa poäng förutsade egenskaper hos 69 500 andra deltagare, som spände över ett brett spektrum av genetiska bakgrunder. Istället för att placera människor i breda ursprungsboxar satte teamet varje individ längs en kontinuerlig "genetisk distans"-skala: hur långt varje persons DNA-profil låg från genomsnittet för GWAS-frivilliga när den projicerades in i en genetisk karta baserad på huvudkomponenter.
Prediktionskraften avtar — men inte på ett enkelt eller rättvist sätt
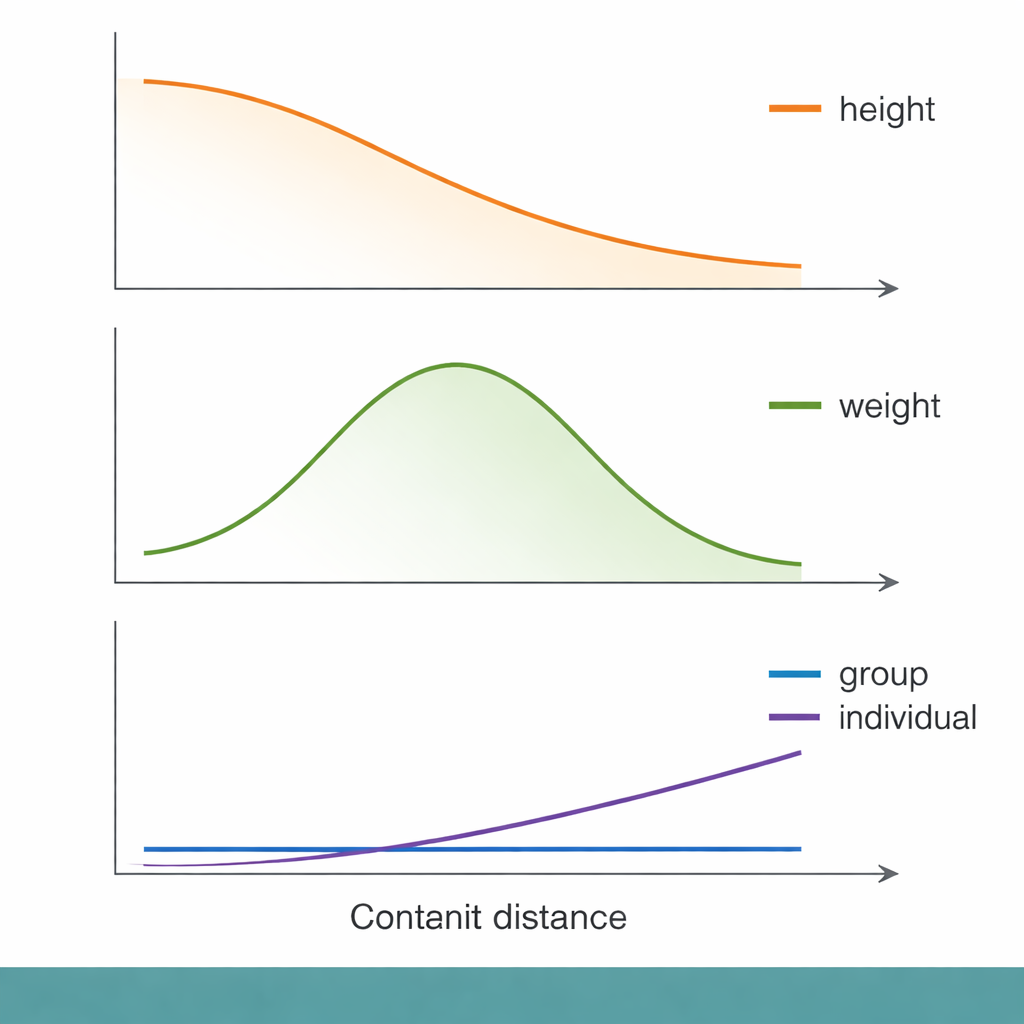
Över denna genetiska distansskala framträdde vissa bekanta mönster. För längd, till exempel, minskade gruppnivåns prediktionsnoggrannhet jämnt i takt med att människor blev mer genetiskt avlägsna från GWAS-gruppen. När forskarna zoomade in på individnivå förklarade den genetiska distansen dock bara en liten del av hur väl deras egenskaper predikterades. Socioekonomiska mått, såsom Townsend Deprivation Index (en områdesnivåindikator för materiell utsatthet), förklarade ungefär lika mycket — eller något mer — av vem som fick dåliga prediktioner. Med andra ord tenderade personer med lägre socioekonomisk status att få mindre exakta genetiska prediktioner, även inom samma genetiska distansband, vilket lyfter fram att sociala sammanhang kan spela lika stor roll som DNA för om en poäng är användbar.
Olika egenskaper, olika historier, olika svar
Inte alla egenskaper uppförde sig likadant. För kroppsvikt och kroppsfett nådde prediktionsnoggrannheten faktiskt en topp vid måttliga genetiska avstånd innan den sjönk, vilket bröt det enkla "längre bort betyder sämre"-mönstret. Immunrelaterade egenskaper, såsom vita blodkroppar och lymfocytantal, visade särskilt förbryllande beteenden. För några av dessa egenskaper föll gruppnivåns prediktionsnoggrannhet nästan till noll även för personer som inte var genetiskt mycket avlägsna från GWAS-provet. Författarna föreslår att immunegenskaper kan formas av snabbt förändrade evolutionära påtryckningar — till exempel tidigare infektioner — som ändrar vilka DNA-varianter som är betydelsefulla i olika populationer. I dessa fall kan den genetiska arkitekturen i sig ha skiftat så mycket att en poäng baserad på en grupp blir nästan oanvändbar i en annan.
Hur vi mäter prestanda kan vända på berättelsen
Bilden blir ännu mer komplicerad när vi ändrar hur "bra prediktion" mäts. Mycket tidigare arbete har förlitat sig på en enda statistisk måttstock kallad R², som fångar hur mycket variation i en egenskap en poäng förklarar inom en grupp. Författarna visar att andra mått kan berätta en annan historia, särskilt för sjukdomar. För astma minskade både precision (hur många förutsagda fall som är verkliga fall) och recall (hur många verkliga fall som hittas) med genetisk distans på liknande sätt. Men för typ 2-diabetes höll sig precisionen någorlunda konstant medan recall faktiskt ökade med distansen — vilket betyder att poängen hittade en större andel verkliga fall i mer avlägsna grupper, trots att den byggts i en närmare grupp. Beroende på om en klinik värderar att hitta alla högriskpatienter eller att undvika falska larm kan man alltså dra motsatta slutsatser om hur bärbar poängen är.
Vad detta betyder för att använda DNA-poäng i verkliga livet
Sammantaget argumenterar studien för att vi inte kan bedöma användbarheten hos polygena poäng genom att endast titta på breda ursprungsetiketter eller ett enda noggrannhetstal. Individuell prediktionskvalitet beror på en blandning av faktorer: subtila mönster av genetisk likhet, den evolutionära historien för varje egenskap, de miljöer och sociala villkor människor lever i, och hur poängen och dess prestationsmått valts ut. För att polygena poäng ska kunna användas rättvist och effektivt inom medicinen behöver forskare bättre sätt att fånga finmaskig genetisk struktur, modellera sociala och miljömässiga influenser och anpassa utvärderingsmått till verkliga beslut. Fram tills dess bör genetiska riskpoäng användas med försiktighet, med uppmärksamhet på de personer — och kontexter — för vilka de fungerar dåligt såväl som de där de fungerar väl.
Citering: Wang, J.Y., Lin, N., Zietz, M. et al. Three open questions in polygenic score portability. Nat Commun 17, 942 (2026). https://doi.org/10.1038/s41467-026-68565-3
Nyckelord: polygena poäng, genetisk prediktion, hälsoojämlikheter, genetiskt ursprung, precisionmedicin