Clear Sky Science · sv
Fysiska neurala nätverk med skärpe-medveten träning
Varför detta spelar roll för AI-hårdvarans framtid
När artificiell intelligens blir kraftfullare begränsas den i allt högre grad inte av smarta algoritmer utan av de kretsar som kör dem. En lovande väg ut är att bygga neurala nätverk direkt i fysisk hårdvara med hjälp av ljus, analog elektronik eller andra vågbaserade system. Den här artikeln introducerar ett nytt sätt att träna sådana ”fysiska neurala nätverk” så att de förblir precisa även när verkligheten är rörig—när enheter är något felbyggda, värme driver, eller komponenter hamnar ur linje.
Från digitala hjärnor till fysiska maskiner
Modern AI körs vanligtvis på digital hårdvara som grafikprocessorer, där träning förlitar sig på backpropagation för att justera miljontals numeriska vikter. Fysiska neurala nätverk försöker flytta ut denna beräkning i verkliga material och enheter—som fotoniska chip, interferometernät eller diffraktiva optiska uppställningar—vars beteende naturligt efterliknar neurala nätverks matematik. Eftersom dessa system bearbetar information där den lagras kan de vara mycket snabbare och mer energieffektiva än konventionella kretsar. Men att träna dem är svårt: antingen tränar man en digital modell och hoppas att den matchar hårdvaran, eller så tränar man direkt på själva enheten. Båda vägarna stöter på problem när verkliga enheter avviker från ideala modeller eller driver över tid.
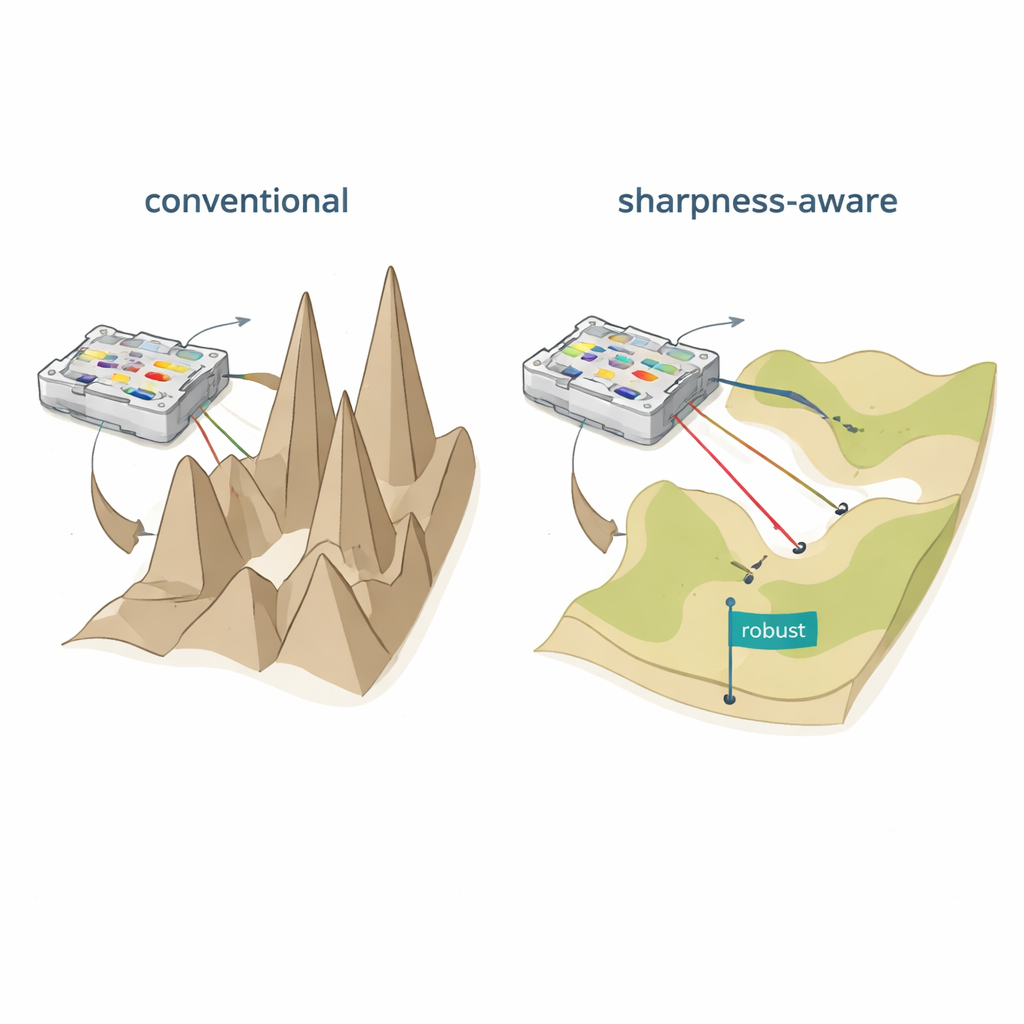
Två bristfälliga sätt att lära fysiska nätverk
Det första tillvägagångssättet, kallat in silico-träning, lär alla parametrar i en datorbaserad modell och kopierar dem sedan till hårdvaran. Detta fungerar bara bra om den matematiska modellen nästan exakt överensstämmer med den tillverkade enheten, vilket sällan är fallet när tillverkningsvariationer, elektriskt brus och termiska effekter räknas in. Det andra tillvägagångssättet, in situ-träning, integrerar den fysikaliska enheten direkt i inlärningsprocessen och mäter upprepade gånger utsignaler medan parametrarna justeras. Även om detta kringgår modelleringsfel skapar det andra problem: gradientinformation är svår och kostsam att få fram, träningen blir enhetsspecifik och de resulterande parametrarna kan ofta inte överföras till en annan nominalt identisk krets. I båda fallen kan små förändringar efter distribution—som en liten temperaturskiftning eller feljustering—kapa nog noggrannheten och tvinga fram dyr omträning.
Att jämna ut inlärningslandskapet
Författarna föreslår skärpe-medveten träning (SAT), inspirerad av en maskininlärningsidé kallad sharpness-aware minimization. Istället för att bara hitta inställningar som ger låg fel på träningsdata söker SAT också områden där felet förändras långsamt när de underliggande fysiska parametrarna nudgas. I geometriska termer hittar traditionell träning ofta en djup men smal dal i ”förlustlandskapet”, där även små skift i strömmar, faser eller positioner får prestandan att kollapsa. SAT söker medvetet breda, platta dalar där prestandan förblir hög under sådana störningar. Matematiskt lägger det till ett termer i träningsmålet som straffar skarpa, mycket krökta regioner i parameterutrymmet, och det approximerar detta straff effektivt med två noggrant valda gradientsteg istället för dyra andraderivata-beräkningar.
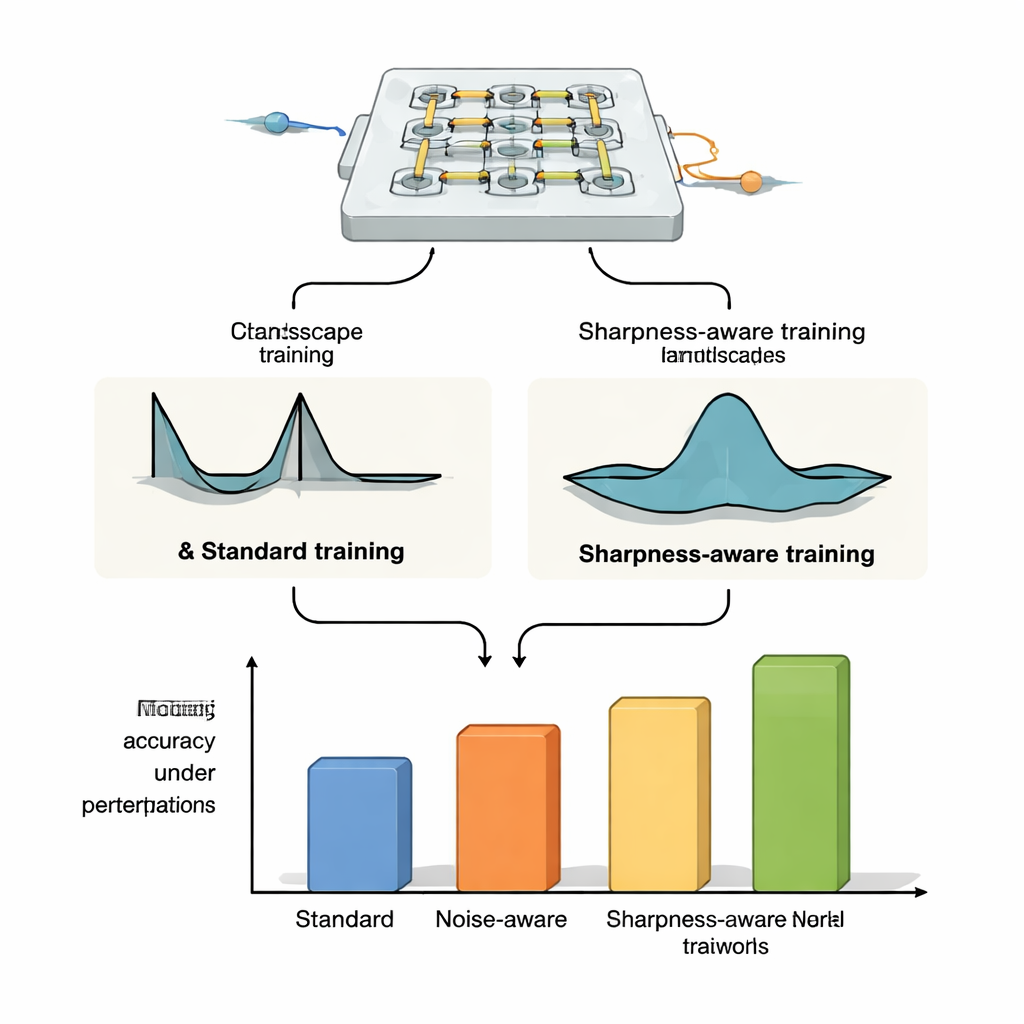
Bevisad robusthet över olika optiska plattformar
För att visa att SAT inte är bunden till en specifik enhet tillämpar författarna det på tre olika optiska neurala nätverksplattformar. På microring-resonatorviktbanker—små siliconringar som styr ljus vid olika våglängder—visar de att SAT-tränade system behåller hög klassificeringsnoggrannhet även när temperaturen driver med flera grader Celsius, medan standardträning och brusinjiceringsmetoder misslyckas dramatiskt. De utvidgar detta till mer krävande uppgifter som bildklassificering på CIFAR-10, bildkompression och rekonstruktion, samt bildgenerering, där SAT håller prestandan stabil medan konventionella metoder fallerar vid måttliga termiska skift. I simuleringar av Mach–Zehnder-interferometernät är SAT-tränade modeller mycket mer toleranta mot realistiska tillverkningsfel och, vilket är avgörande, parametrar tränade på en enhet kan överföras till andra kretsar med olika imperfektioner utan att förlora noggrannhet. Slutligen, i en fritt-luft diffraktiv optisk uppställning med OLED-skärm, linser och en spatial ljusmodulator förbättrar SAT toleransen mot fysiska feljusteringar som rotation, pixelförskjutningar och skalning, även om det exakta sambandet mellan dessa feljusteringar och nätverksparametrarna inte modelleras explicit.
En praktisk väg till pålitlig fysisk AI
I klarspråk visar detta arbete hur man lär hårdvarubaserade neurala nätverk på ett sätt som ”förlåter” de oundvikliga egenheterna hos verkliga enheter. Genom att styra inlärningen mot platta, stabila regioner i felfläcken gör skärpe-medveten träning fysiska neurala nätverk både mer precisa och mer robusta mot tillverkningsvariationer, temperaturförändringar och mekaniska feljusteringar. Eftersom metoden kan användas med eller utan detaljerade fysiska modeller och fungerar över flera typer av optisk hårdvara, erbjuder SAT ett praktiskt recept för att skala upp snabba, energieffektiva fysiska AI-system från labbdemonstrationer till verkliga tillämpningar.
Citering: Xu, T., Luo, Z., Liu, S. et al. Physical neural networks using sharpness-aware training. Nat Commun 17, 1766 (2026). https://doi.org/10.1038/s41467-026-68470-9
Nyckelord: fysiska neurala nätverk, fotonisk beräkning, robust träning, skärpe-medveten optimering, neuromorf hårdvara