Clear Sky Science · sv
Omfattande kartläggning av RNA‑modifieringsdynamik och korsprat via djupinlärning och nanopore direkt RNA‑sekvensering
RNA:s dolda skiljetecken
Cellernas RNA‑molekyler är inte enkla strängar av A, C, G och U. De är prydda med mängder av små kemiska markörer som fungerar som skiljetecken och hjälper till att styra vilka gener som slås på, hur proteiner tillverkas och hur celler reagerar på stress och sjukdom. Ändå har forskare hittills mestadels kunnat studera dessa markörer en i taget, vilket gör det svårt att förstå hur de samverkar över hela genomet. Denna artikel presenterar ORCA, ett djupinlärningssystem som läser nativa RNA‑molekyler direkt och bygger en global, flerskiktad karta över dessa kemiska markörer och deras interaktioner.
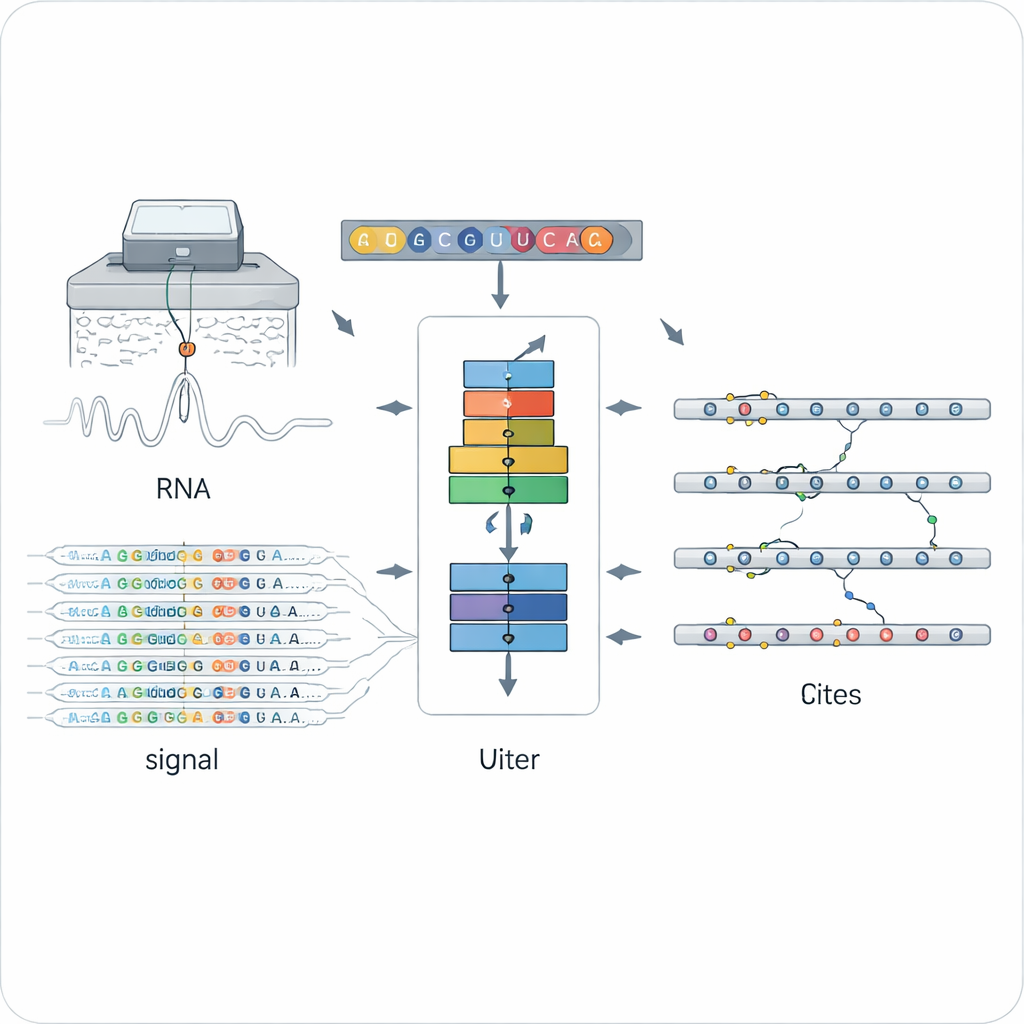
En ny metod för att avläsa kemiska markörer på RNA
Traditionella metoder för att hitta RNA‑modifieringar förlitar sig vanligen på specifika antikroppar eller kemi som är inriktad på en enda typ av markör, som den välkända N6‑metyladenosin (m6A). Det gör dem kraftfulla men snäva: varje metod ser bara en typ av markör, ofta i en enda experimentell uppställning. Nanopore direkt RNA‑sekvensering öppnade en annan väg genom att träda individuella RNA‑molekyler genom en mycket liten por och mäta förändringar i elektrisk ström som beror på den exakta kemiska strukturen hos varje bas. Modifierade och omodifierade baser förvränger signalen och basavläsningen på subtilt olika sätt, men att tolka denna bullriga, högdimensionella data över många modifieringstyper har varit en större utmaning.
Att lära ett neuralt nätverk att känna igen vilken markör som helst
ORCA (Omni‑RNA modification Characterization and Annotation) angriper denna utmaning i två steg. Först fokuserar det på ett litet fönster runt varje position i RNA och summerar både den råa elektriska signalen och mönstret av sekvenseringsfel över många läsningar. Eftersom endast en bråkdel av RNA‑kopiorna bär en viss markör visar verkligt modifierade positioner mer snedfördelade signalsfördelningar och oftare fel i basavläsningen vid den positionen. ORCA använder ett djup återkommande neuralt nätverk tränat med en ”adversarial” strategi så att det lär sig generella mönster som skiljer modifierade från omodifierade positioner utan att låsa sig vid någon enskild känd kemisk typ. Detta gör att ORCA kan tilldela varje position en modifieringspoäng och en uppskattad andel av molekylerna som är modifierade.
Lära sig vilken typ av markör som finns
I det andra steget lär sig ORCA att märka vilken sorts kemisk markör som är närvarande. Författarna matar modellen med ett set hög‑konfidents‑positioner från offentliga databaser, där konventionella experiment redan identifierat m6A, 5‑metylcytosin (m5C), pseudouridin (Ψ), inosine, 2′‑O‑metylering och flera mer sällsynta markörer. ORCA komprimerar signalmönstren, sekvenskontexten och korta sekvens"motif" runt varje position till en lägre‑dimensionell karta och finjusterar sig sedan för att förutsäga modifieringstypen och den exakta basen den sitter på. Viktigt är att omärkta positioner också används som ”bakgrundsexempel”, vilket hjälper modellen att undvika att tvinga okända markörer in i fel kategori. När den är tränad kan ORCA överföra dessa inlärda etiketter till tiotusentals tidigare oannoterade positioner över transkriptomet.
Att se många modifieringar samtidigt
När ORCA appliceras på mänskliga och musceller visar författarna att den inte bara matchar eller överträffar noggrannheten hos ledande verktyg för specifika markörer som m6A, m5C och Ψ, utan också kan upptäcka markörer den aldrig uttryckligen tränats på. Till exempel, även när m6A‑data uteslöts under träningen återfann ORCA de flesta oberoende mätta m6A‑positionerna och skilde korrekt dem från liknande sekvensmotif som inte är modifierade. Den gjorde samma sak för 2′‑O‑metylgrupper, inosinediteringsplatser och ett brett spektrum av kemiska förändringar på ribosomalt RNA, inklusive många sällsynta modifieringar mätta med massespektrometri. Sammantaget utökar ORCA den kända katalogen av RNA‑modifieringsplatser avsevärt, med flera gånger fler annoterade m5C, Ψ, m7G och andra lågfrekventa markörer jämfört med befintliga databaser.
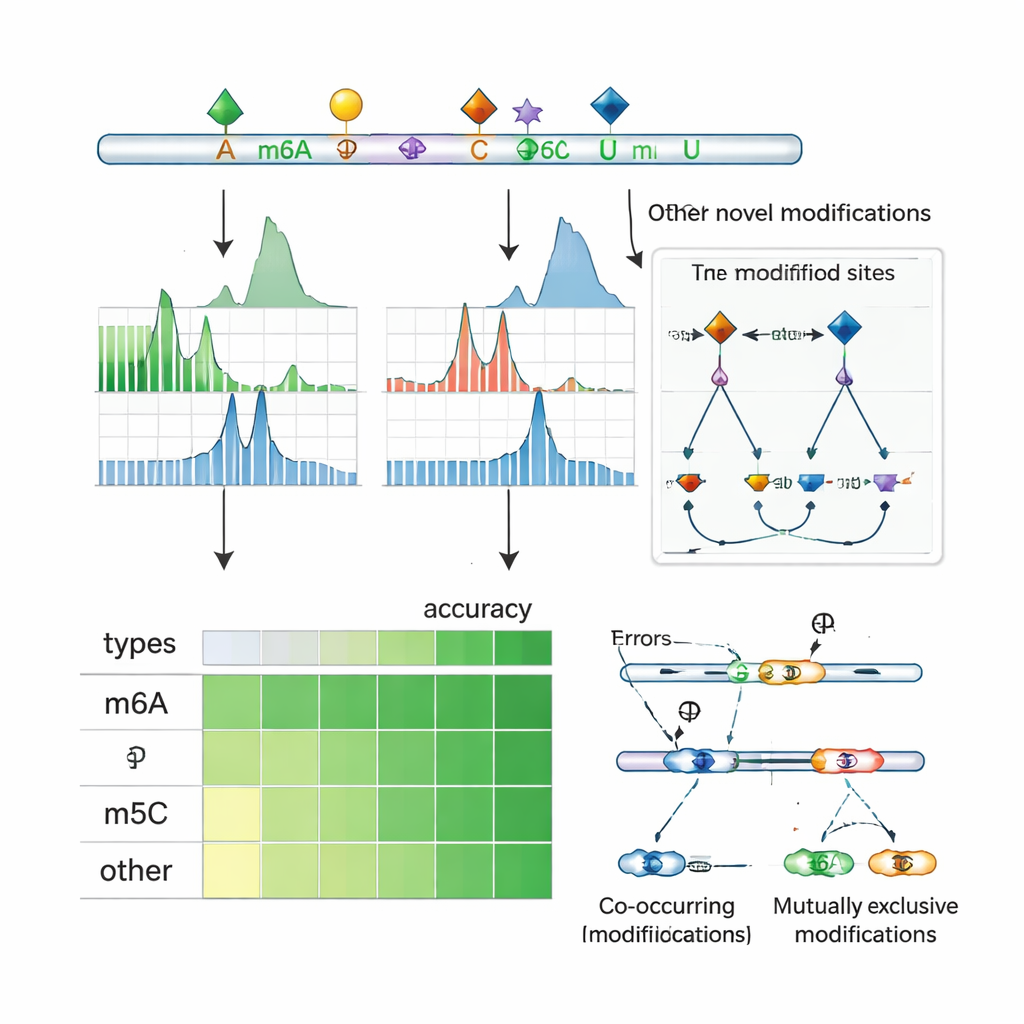
Avslöja korsprat och kontroll av splitsning
Eftersom nanoporesekvensering läser hela RNA‑molekyler kan ORCA undersöka vilka markörer som förekommer tillsammans på samma transkript och vilka som tenderar att utesluta varandra. Författarna klustrar närliggande markörer längs RNA och använder en probabilistisk modell för att sluta sig till om par av positioner ofta är sammodifierade eller ömsesidigt uteslutande på enskilda molekyler. De finner frekvent samförekomst av m6A med m5C och andra markörer, liksom många regioner där en position endast är modifierad när den intilliggande positionen inte är det. I mänskliga cellinjer faller dessa mönster ofta nära exoner som alternativt inkluderas eller hoppas över, och de overlappar bindningsställen för splitsningsregulatorer och ”reader”‑proteiner som känner igen modifierat RNA. I specifika gener visar ORCA att vissa splicevarianter är berikade för ett mönster av markörer, medan alternativa varianter bär ett annat mönster, vilket kopplar lokal kemisk prydnad av RNA till hur budskap klipps och sammanfogas.
Varför detta är viktigt för biologi och medicin
Genom att kombinera direkt RNA‑sekvensering med flexibel djupinlärning omvandlar ORCA en komplicerad elektrisk signal till en rik, flerskiktad karta över kemiska markörer i transkriptomet. För icke‑specialister är det viktigaste resultatet att forskare nu kan se inte bara var individuella RNA‑modifieringar förekommer, utan hur många olika markörer som pryder samma molekyl och hur dessa kombinationer relaterar till genreglering, särskilt RNA‑splitsning. Denna ram gör det möjligt att studera RNA‑"epigenetik" i många celltyper och tillstånd utan att behöva designa ett nytt experiment för varje markör, vilket banar väg för upptäckter om hur dessa små kemiska justeringar bidrar till utveckling, hjärnfunktion och sjukdomar som cancer och neurologiska störningar.
Citering: Dong, H., Gao, Y., Cai, Z. et al. Comprehensive mapping of RNA modification dynamics and crosstalk via deep learning and nanopore direct RNA-sequencing. Nat Commun 17, 1722 (2026). https://doi.org/10.1038/s41467-026-68419-y
Nyckelord: RNA‑modifieringar, nanoporesekvensering, djupinlärning, epitranskriptom, alternativ splitsning