Clear Sky Science · sv
Bästa praxis och verktyg i R och Python för statistisk bearbetning och visualisering av lipidomik- och metabolomikdata
Varför det spelar roll att omvandla laboratoriesiffror till tydliga bilder
Moderna instrument kan nu mäta tusentals små molekyler—lipider och andra metaboliter—i en enda droppe blod eller vävnad. Dessa mätningar innehåller ledtrådar om sjukdomsrisker, behandlingssvar och hur våra kroppar reagerar på kost eller åldrande. Men rådata är inget färdigt svar: det är en enorm tabell med siffror som måste rengöras, analyseras och omvandlas till begripliga bilder. Denna artikel förklarar hur forskare kan använda två populära programspråk, R och Python, för att göra detta på ett pålitligt, transparent sätt och med grafik som håller publiceringskvalitet.
Från kemiska mätningar till komplexa datatabeller
Inom lipidomik och metabolomik genererar masspektrometri och kromatografi stora dataset där varje rad är ett prov och varje kolumn en molekyl. Dessa tabeller beter sig sällan som prydliga läroboksexempel. De innehåller saknade värden, avvikare och sneda fördelningar där ett fåtal molekyler visar extremt höga nivåer. Koncentrationer kan spänna över flera storleksordningar och påverkas av ålder, kön, kost, läkemedel, dygnsrytm och tekniska problem som instrumentdrift eller batcheffekter. Internationella expertgrupper har utfärdat riktlinjer för att standardisera hur prover samlas in, bearbetas och rapporteras, men även med god laboratoriepraxis är noggrann statistisk bearbetning avgörande för att extrahera verkliga biologiska signaler ur detta brusiga underlag.
Rengöring och förberedelse av siffrorna
Innan någon jämförelse mellan friska och sjuka grupper ger mening måste data förberedas. Översikten beskriver hur saknade värden uppstår—genom slumpmässiga missöden, instrumentbegränsningar eller signalstörningar—och förklarar när de kan förbises, när de bör mätas om och hur de rimligtvis kan uppskattas (imputeras) med metoder som k-närmaste grannar, random forests eller enkel substitution med låga värden. Därefter skisserar författarna normaliseringsstrategier som minskar oönskad variation, till exempel genom korrigering av batcheffekter med kvalitetskontrollprov eller justering för skillnader i provmängd. De diskuterar också transformationer som logaritmer—som tämjer långa högersvansar i data—och skalningsmetoder som sätter alla molekyler på jämförbar grund så att mycket variabla föreningar inte dominerar senare analyser. 
Statistiska tester och visuella berättelser
När data är ordentligt förberedda kommer en rad statistiska verktyg till användning. För enskilda molekyler kan forskare beräkna fold changes och använda klassiska tester såsom t-testet eller dess icke-parametriska motsvarigheter (som Mann–Whitney-testet) för att undersöka om nivåer skiljer sig mellan grupper. För jämförelser som involverar flera grupper introduceras metoder som ANOVA eller Kruskal–Wallis-testet, tillsammans med post hoc‑procedurer för att avgöra vilka grupper som skiljer sig åt. Kraften i dessa tester frigörs när resultaten visualiseras tydligt. Artikeln lyfter fram lådagram (inklusive förbättrade versioner för snedfördelade data), violinplots och vulkanplots som kombinerar effektstorlek och statistisk signifikans. För lipider beskrivs mer specialiserade visualiseringar, såsom lipidnätverk som visar koordinerade förändringar över hela klasser, och grafer över fettsyra‑acylkedjor som avslöjar mönster i kolkedjelängd och mättnadsgrad.
Se mönster i många variabler samtidigt
Eftersom varje prov kan ha hundratals eller tusentals uppmätta molekyler är multivariata metoder avgörande. Översikten förklarar hur principal component analysis (PCA) komprimerar denna komplexitet till några nya axlar som fångar huvudriktningarna för variation, vilket möjliggör snabba kontroller av gruppseparation, batcheffekter eller analytisk stabilitet. Mer avancerade icke‑linjära metoder, inklusive t‑SNE och UMAP, kan avslöja subtila kluster och strukturer i högdimensionellt utrymme. För situationer där målet är att klassificera prover—till exempel att skilja patienter från kontroller—beskriver författarna övervakade tillvägagångssätt baserade på Partial Least Squares och dess ortogonala förlängning (PLS‑DA och OPLS‑DA). Dessa metoder kopplar molekylprofiler till provetiketter, stöder feature‑urval och sammanfattas ofta med scoreplots, loadingplots och receiver operating characteristic‑kurvor.
Praktiska verktygslådor i R och Python
För att hjälpa nybörjare att gå från teori till praktik kartlägger artikeln ett brett ekosystem av mjukvarupaket. I R förenklar kollektioner som tidyverse och tidymodels datarengöring och modellering, medan ggplot2 och tilläggspaket som ggpubr, ggstatsplot och tidyplots gör det lättare att generera figurer i publiceringskvalitet. Specialiserade bibliotek hanterar PCA, klustring och PLS‑baserade modeller, och Bioconductor‑paket stödjer komplexa värmekartor och interaktiva grafer. I Python erbjuder pandas tabellhantering, medan matplotlib, seaborn och plotly täcker visualisering, och scikit‑learn ger en bred uppsättning multivariata metoder. Genomgående betonar författarna steg‑för‑steg‑exempel som görs tillgängliga i en medföljande GitBook, så att läsare kan reproducera arbetsflöden och anpassa dem till sina egna data. 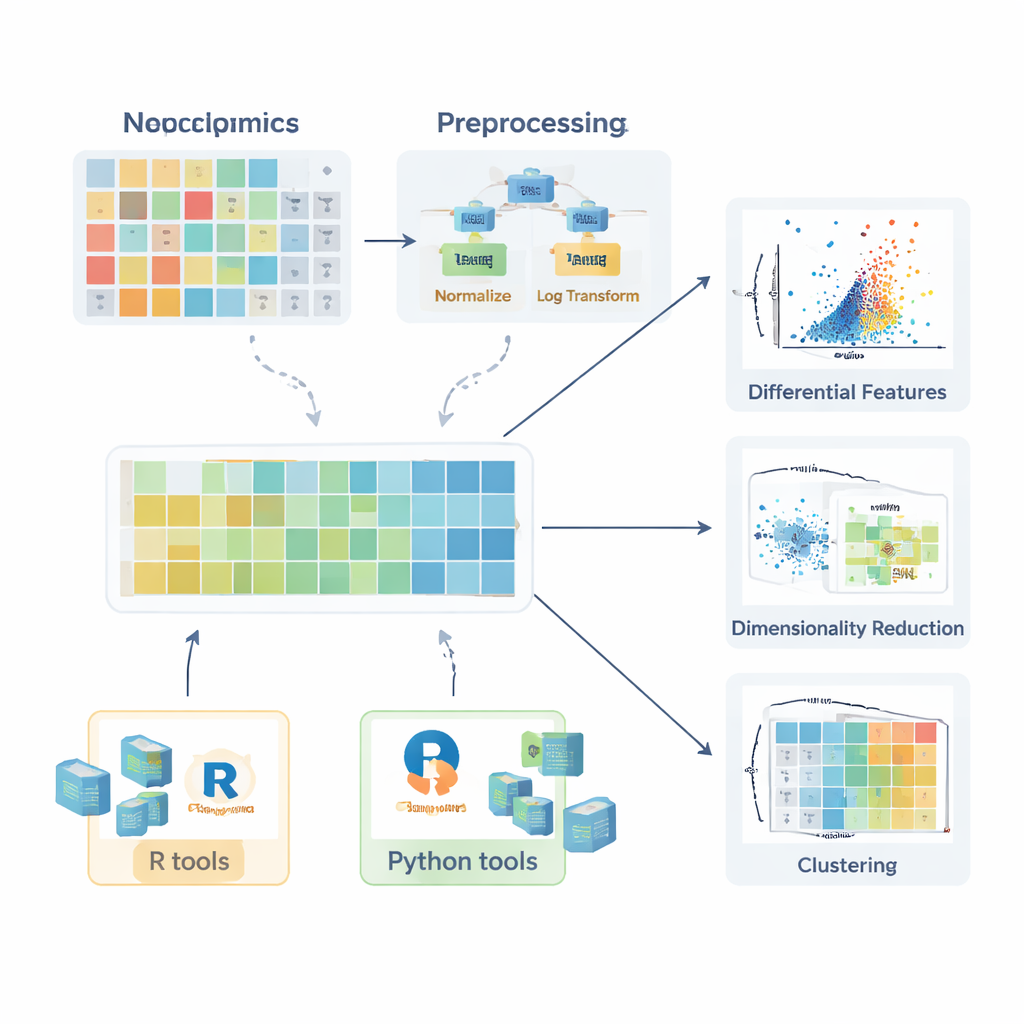
Att omvandla komplex kemi till tillförlitlig insikt
Artikeln avslutar med att konstatera att den verkliga potentialen i lipidomik och metabolomik inte bara ligger i kraftfulla instrument, utan i hur genomtänkt deras output bearbetas och visualiseras. Genom att följa god statistisk praxis, använda öppna och väl dokumenterade verktyg i R och Python och förlita sig på delade kodexempel, kan forskare bygga robusta och reproducerbara pipelines. Det ökar chansen att mönster funna i små molekyler blir till pålitliga biomarkörer, bättre förståelse av sjukdomsmekanismer och mer personanpassade medicinska tillvägagångssätt som i slutändan gynnar patienter.
Citering: Idkowiak, J., Dehairs, J., Schwarzerová, J. et al. Best practices and tools in R and Python for statistical processing and visualization of lipidomics and metabolomics data. Nat Commun 16, 8714 (2025). https://doi.org/10.1038/s41467-025-63751-1
Nyckelord: lipidomik, metabolomik, datavisualisering, R-programmering, Python