Clear Sky Science · sv
Användning av maskininlärning och genomik för förbättring av föräldralösa grödor
Skymda grödor med stor potential
I Afrika, Asien och Latinamerika är miljontals människor beroende av så kallade ”föräldralösa grödor” såsom sorghum, teff, kassava och jordnöt. Dessa växter hamnar sällan i rubrikerna, men tål ofta värme, torka, skadedjur och dåliga jordar bättre än globala stapelvaror som vete eller ris. Denna översiktsartikel undersöker hur två kraftfulla verktyg — genomik och maskininlärning — kan frigöra potentialen hos dessa förbisedda grödor, stärka lokal livsmedelssäkerhet och samtidigt leverera värdefulla gener som kan stärka större grödor världen över.
Varför förbisedda grödor spelar roll
Föräldralösa grödor kallas ibland ”försummade” eller ”underutnyttjade” eftersom de fått mycket mindre vetenskaplig och kommersiell uppmärksamhet än stora exportgrödor. Ändå är de näringsmässiga huvudstöd för många samhällen och odlas ofta i hårda, marginala miljöer där andra grödor misslyckas. Till skillnad från vete eller ris missade de flesta föräldralösa grödor Grüna revolutionens förädlingsframsteg och moderna verktyg som markörstödd förädling och genredigering. Genomiska projekt som African Orphan Crops Consortium börjar sekvensera och katalogisera deras DNA, men att omvandla rå genetisk data till praktiska förbättringar är fortfarande en stor utmaning.
Lära datorer att läsa växter
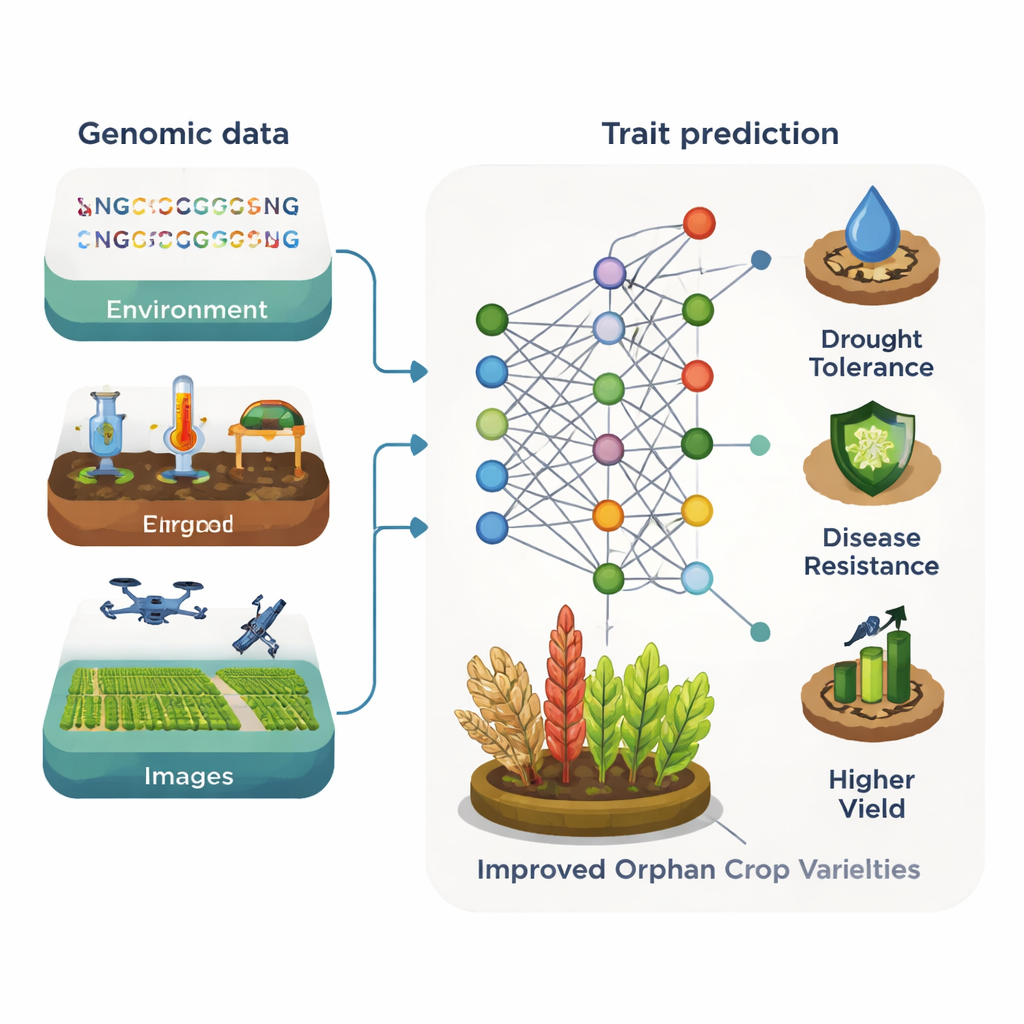
Maskininlärning — datorbaserade metoder som lär sig mönster från stora datamängder — omvandlar redan förädlingen av stora grödor. Genom att kombinera genomsekvenser, väder- och jorddata, sensormätningar och bilder från drönare eller smarttelefoner kan algoritmer förutsäga komplexa egenskaper såsom avkastning, sjukdomsresistens eller sädesskvalitet. Olika modelltyper, från beslutsträd till djupa neurala nätverk, är framgångsrika i olika situationer. Ibland matchar eller överträffar traditionella statistiska verktyg fortfarande djupinlärning, men överlag ger en blandning av flera datakällor och modeller förädlare mer precisa och konsistenta förutsägelser än någon enskild metod ensam.
Få ut det bästa av knappa data
För föräldralösa grödor är det centrala hindret inte datorkraft utan brist på data. Endast ett fåtal publika genomiska och bilddatabaser finns, och få är tillräckligt stora för konventionella maskininlärningspipelines. Ändå är de första demonstrationerna lovande. I sorghum, till exempel, kunde djupinlärningsmodeller med hjälp av enkla fotografier av spannmål förutsäga proteininnehåll och antioxidanthalter med hög noggrannhet, vilket erbjuder ett billigare alternativ till laboratorietester. I ett annat fall användes nära-infraröda mätningar och djupinlärning för att uppskatta näringsegenskaper i örten Perilla. Artikeln argumenterar för att uppbyggnaden av delade databaser med genomer, bilder och kemiska profiler för föräldralösa grödor snabbt skulle kunna mångfaldiga effekten av sådana verktyg.
Låna kunskap från större grödor
Ett centralt begrepp i artikeln är ”kunskapsöverföring” mellan arter. Många föräldralösa grödor är nära släktingar till stora grödor och delar stora DNA-avsnitt och liknande gener. Maskininlärningsmodeller kan utnyttja denna närhet. Verktyg som först tränats på välstuderade växter som Arabidopsis eller majs kan hjälpa till att identifiera gener för egenskaper som växthöjd, frökvalitet eller stresstolerans i en mindre känd kusin. Stora språkmodeller som ursprungligen utvecklats för mänskliga eller växtgenom kan också behandla DNA som en sorts text och lära sig mönster som markerar regulatoriska regioner eller viktiga gener. När dessa modeller tränats på rika datamängder kan de finjusteras med begränsad data från föräldralösa grödor för att förutsäga genfunktion, lyfta fram mål för genredigering och vägleda mer effektiv förädling.
Från algoritmer till fält och bönder
Författarna betonar att tekniken ensam inte kommer att förvandla föräldralösa grödor. Framsteg beror på investeringar i lokala forskare, partnerskap med småbrukare och politik som säkerställer att samhällen drar nytta av nya sorter. Medborgarvetenskapliga tillvägagångssätt, där bönder testar sorter direkt på sin egen mark, kan generera värdefull data för maskininlärning samtidigt som forskningen anpassas efter lokala behov och smak. Eftersom finansieringen är begränsad rekommenderar artikeln en balanserad strategi: kombinera lågkostnadstraditionell förädling och agronomi med noggrant riktade genomiska och maskininlärningsprojekt, samt dela verktyg och data mellan länder och mellan föräldralösa och större grödor.
Vad detta betyder för vår matframtid
Enkelt uttryckt slutar artikeln att smartare datorer plus bättre genetisk information kan hjälpa till att förvandla dagens ”glömda” grödor till morgondagens klimatanpassade stapelvaror. Genom att lära av stora grödor och tillämpa dessa lärdomar på mindre — och sedan återföra upptäckter åt andra hållet — kan maskininlärning och genomik påskynda sökandet efter härdiga, näringsrika sorter. Om detta stöds av genomtänkt politik och genuint samarbete med jordbrukssamhällen kan tillvägagångssättet förbättra kost, stärka motståndskraften mot klimatförändringar och bredda världens jordbrukslåda bortom en snäv uppsättning stapelgrödor.
Citering: MacNish, T.R., Danilevicz, M.F., Bayer, P.E. et al. Application of machine learning and genomics for orphan crop improvement. Nat Commun 16, 982 (2025). https://doi.org/10.1038/s41467-025-56330-x
Nyckelord: föräldralösa grödor, maskininlärning, genomik, växtförädling, livsmedelssäkerhet