Clear Sky Science · sv
Det aktuella läget för polygena poäng vid utveckling av lungcancer: en systematisk översikt och validering i UK Biobank
Varför våra gener spelar roll för lungcancer
Lungcancer förknippas ofta med rökning, men inte alla som röker får lungcancer och vissa som aldrig rökt drabbas. Denna gåta har fått forskare att undersöka hur stor del av lungcancerrisken som finns dold i vår DNA. Artikeln behandlar om det är möjligt att kombinera många små genetiska ledtrådar till så kallade polygena poäng för att bättre identifiera vem som löper störst risk att utveckla lungcancer, utöver vad som redan är känt om tobaksanvändning.
Söker genetiska ledtrådar
I stället för ett enskilt ”lungcancergen” vet forskare nu att risken uppstår genom samlad effekt av många subtila DNA‑skillnader. Dessa små förändringar, utspridda över genomet, påverkar var och en risken uppåt eller nedåt i liten utsträckning. Genom att addera hundratals eller till och med tusentals av dessa förändringar till ett enda tal—en polygen poäng—hoppas forskare kunna uppskatta en persons ärftliga benägenhet att utveckla lungcancer. Om sådana poäng fungerar väl kan de en dag hjälpa till att avgöra vem som bör få tidiga screeningundersökningar, även bland dem som aldrig rökt.
Samling av befintliga poäng
Författarna genomförde först en bred sökning i vetenskaplig litteratur och i en offentlig databas över genetiska riskpoäng. De fann 60 olika polygena poäng för lungcancer som skapats sedan 2012, främst baserade på stora genetiska studier i europeiska och östasiatiska populationer. Dessa poäng skilde sig åt i hur många DNA‑förändringar de inkluderade, hur de byggdes upp och om de försökte ta hänsyn till rökning. Vissa hade testats endast i de grupper de skapats från, och bara ett fåtal hade validerats i helt oberoende populationer.
Sätter poängen på prov
För att jämföra dessa poäng rättvist vände sig teamet till UK Biobank, en stor hälsoundersökning som har genetiska data och långsiktiga hälsojournaler för omkring en halv miljon vuxna. Efter att ha uteslutit personer som redan hade cancer följde de över 429 000 deltagare, däribland mer än 3 500 som senare utvecklade lungcancer. Forskarna kunde rekonstruera och testa 39 av de publicerade poängen i denna grupp. För varje person beräknade de en polygen poäng och undersökte sedan hur väl den skiljde dem som senare fick lungcancer från dem som inte gjorde det, med standardiserade mått på prediktionsprestanda.
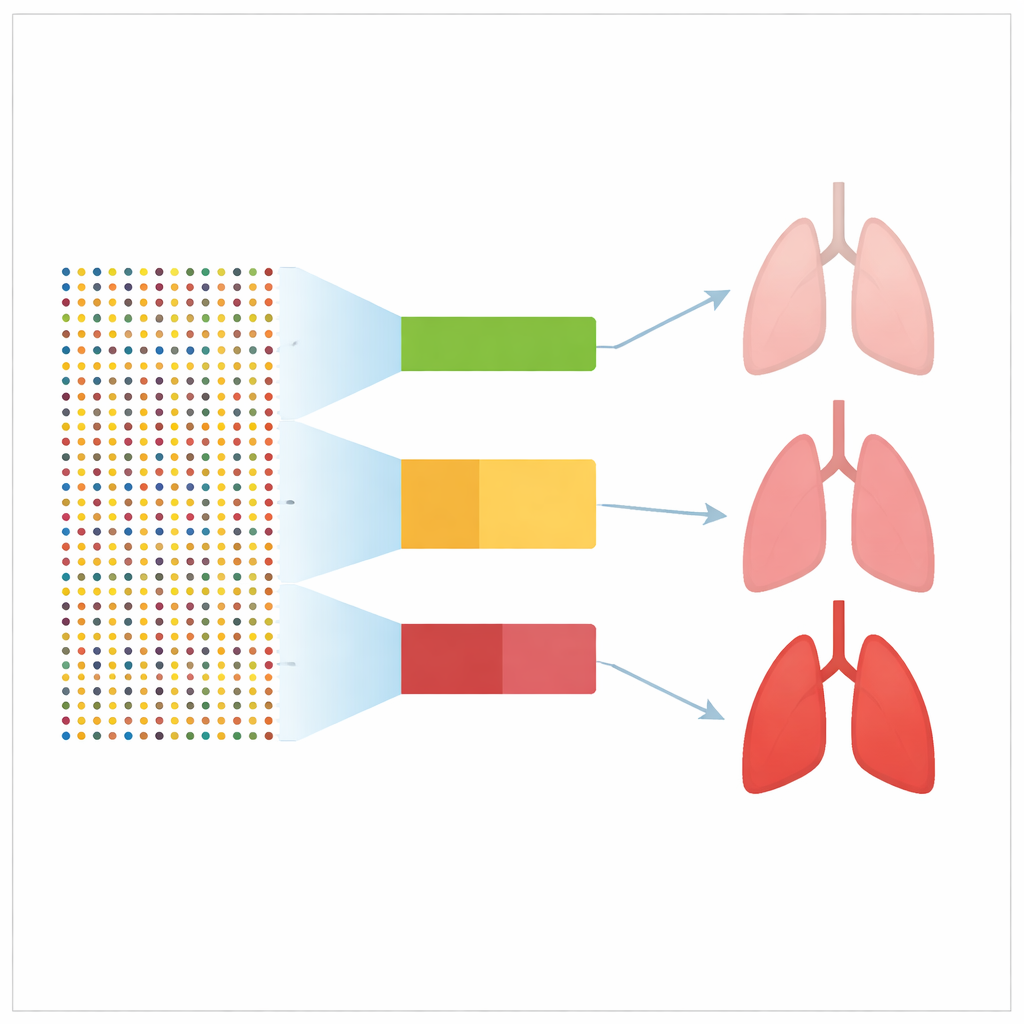
Vad resultaten egentligen visar
De flesta av de testade poängen visade någon koppling till framtida lungcancer, vilket innebär att personer med högre poäng tenderade att oftare diagnostiseras. Styrkan i denna prediktion var dock måttlig. I tekniska termer presterade nästan alla poäng bättre än slumpen men långt under den noggrannhet som setts för liknande poäng vid cancerformer som bröst‑ eller kolorektalcancer. Även de bäst presterande lungcancerpoängen kunde inte koncentrera mer än cirka 2 % av framtida fall till den översta 1 % av den genetiska riskfördelningen. Att göra poängen mer komplexa genom att lägga till fler DNA‑markörer eller använda nyare metoder förbättrade inte deras prestanda påtagligt.
Skillnader efter rökning och härkomst
Eftersom rökning är en så kraftfull riskfaktor undersökte forskarna också hur väl poängen fungerade hos personer med olika rökvanor. För de flesta poäng var prediktionen något bättre bland nuvarande och tidigare rökare än bland personer som aldrig använt tobak, vilket tyder på att många genetiska markörer delvis kan spegla benägenhet för rökbeteende. Intressant nog presterade en liten delmängd av poäng något bättre hos dem som aldrig rökt, vilket antyder att dessa särskilda DNA‑mönster kan fånga mer av den underliggande biologiska benägenheten att utveckla lungcancer. Studien betonade också en allvarlig obalans: de flesta ursprungliga genetiska studierna baserades på personer av europeisk eller östasiatisk härkomst, vilket lämnar mycket begränsad information om hur väl dessa poäng fungerar i andra etniska grupper.
Vad detta betyder för framtida screening
För en lekmannaläsare är huvudbudskapet att nuvarande genetiska poäng för lungcancer ännu inte är tillräckligt starka för att fungera ensamma som ett screeningverktyg. De kan i viss mån skilja hög‑ och lågriskpersoner åt, särskilt bland rökare, men skillnaderna är för små för att på ett tillförlitligt sätt plocka ut vilka som kommer att få lungcancer. Författarna drar slutsatsen att dessa poäng för närvarande sannolikt är mest användbara som en ingrediens i bredare riskmodeller som också inkluderar ålder, rökhistorik och andra hälso‑ eller miljöfaktorer. De betonar också behovet av mer mångsidig genetisk forskning och bättre förståelse för hur gener och rökning samverkar innan genetisk risk meningsfullt kan påverka vem som screenas och när.
Citering: Galal, B., Dennis, J., Antoniou, A.C. et al. The current state of polygenic scores for the development of lung cancer: a systematic review and validation in UK Biobank. Br J Cancer 134, 939–948 (2026). https://doi.org/10.1038/s41416-025-03330-9
Nyckelord: lungcancerrisk, polygena poäng, genetisk känslighet, rökning och genetik, cancerscreening