Clear Sky Science · sv
Beräkningsbaserade prediktorer för varianter inom farmakogenomik: från utvärdering av enstaka alleler till bedömning av allvarliga läkemedelsreaktioner på antidepressiva
Varför dina gener spelar roll för säkerheten vid antidepressiva
När två personer tar samma antidepressiva kan den ena må bättre med få biverkningar medan den andra får svåra problem, inklusive läkemedelstoxicitet. Denna studie undersöker om datorprogram kan läsa små skillnader i vårt DNA för att förutsäga vem som sannolikt hanterar antidepressiva på ett säkert sätt och vem som kan ha högre risk för skadliga reaktioner, vilket potentiellt skulle göra ordinering både säkrare och mer precis.

Från stela etiketter till flexibla genetiska poäng
Idag förlitar sig många kliniker på ett system kallat ”star-alleler”, som grupperar kända DNA-varianter i läkemedels‑metaboliserande gener i ett fåtal breda funktionskategorier, såsom normal eller nedsatt aktivitet. Detta tillvägagångssätt har hjälpt till att vägleda behandling, men det fallerar när en person bär på sällsynta eller aldrig tidigare sedda varianter, eller komplexa kombinationer av förändringar som inte finns på officiella listor. Författarna hävdar att detta är en betydande blindfläck: de flesta farmakogenetiska varianter är sällsynta, och en stor del av variationen i hur människor hanterar läkemedel förblir oförklarad av nuvarande etiketter.
Test av smartare verktyg på kända och nya varianter
Teamet utvärderade tio beräkningsverktyg som poängsätter hur skadlig en DNA-förändring sannolikt är, inklusive två nya ramverk de utvecklat (PharmGScore och PharmMLScore). Först frågade de om dessa verktyg kunde återskapa de funktionskategorier som redan tilldelats 541 kurerade star-alleler över åtta viktiga läkemedelsmetaboliserande gener. Genom att summera poängen för alla varianter inom varje haplotyp matchade flera verktyg eller överträffade till och med prestandan hos star-systemet, med PharmGScore i täten. Därefter utmanade de verktygen med data från höggenomströmmande laboratorieexperiment på två viktiga enzymer, CYP2C9 och CYP2C19, som metaboliserar många läkemedel. Dessa experiment mätte hur tusentals enskilda varianter påverkade enzymaktivitet och proteinnivåer, varav de flesta aldrig tidigare setts hos patienter. Återigen identifierade de bättre verktygen, särskilt farmakogenfokuserade ensemblemetoder och CADD, noggrant varianter som kraftigt försämrade enzymfunktionen.
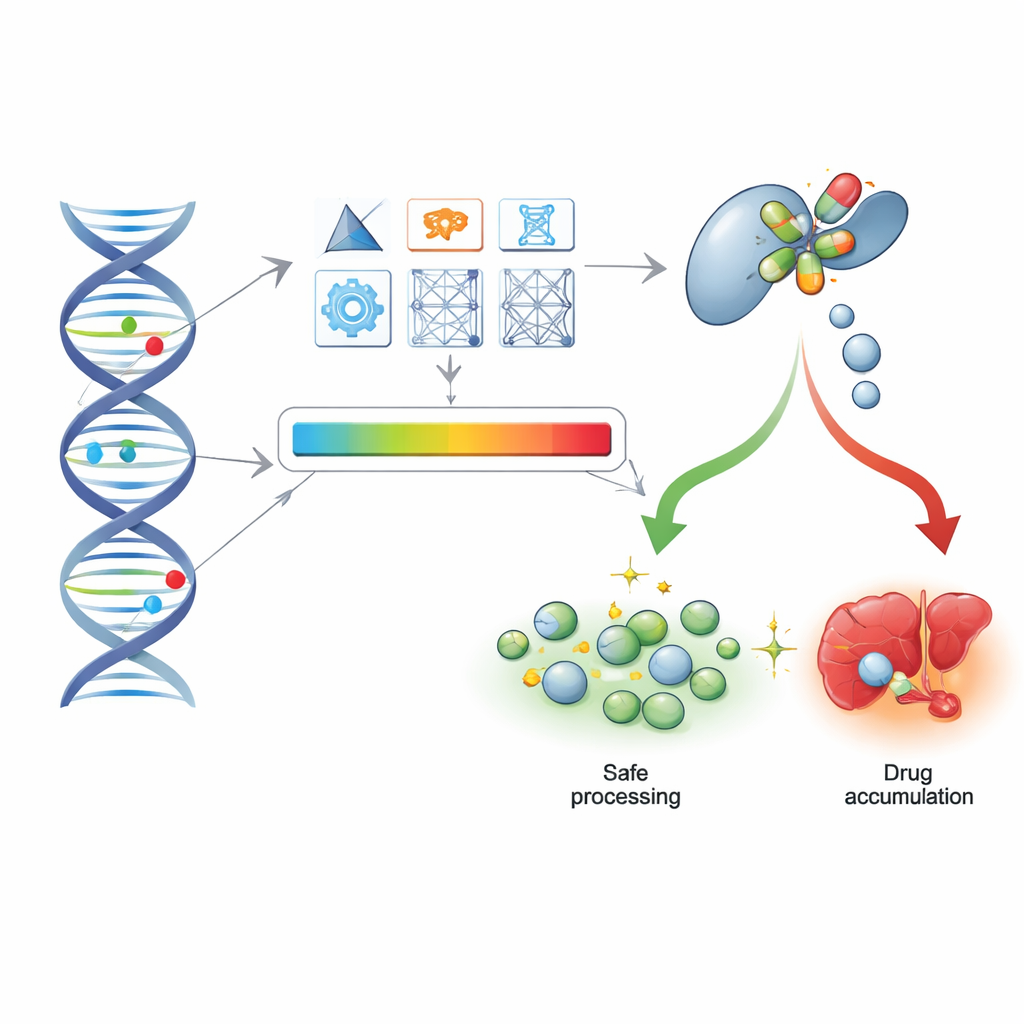
Från DNA-sekvenser till patientjournaler i vardagen
För att se om dessa beräkningspoäng håller i vardagsmedicin vände forskarna sig till exomsekvenseringsdata från mer än 200 000 deltagare i UK Biobank, tillsammans med deras recepthistorik och sjukhusjournaler. De jämförde verktygens prediktioner med star-allel‑kategorier för fem stora läkemedelsmetaboliserande gener och fann att de bästa metoderna i stort kunde återskapa samma funktionsgrupper, trots att exomdata missar vissa icke-kodande och strukturella förändringar. Viktigt är att det additiva tillvägagångssättet — att summera effekten av alla varianter i en gen — fungerade tillräckligt väl för att skilja personer utan funktionella genotyper från dem med normal aktivitet.
Att upptäcka personer i riskzonen för allvarliga antidepressiva reaktioner
Författarna fokuserade sedan på användning och säkerhet av antidepressiva, med särskilt intresse för enzymet CYP2C19, som hjälper till att bryta ner flera vanliga antidepressiva. Bland mer än 75 000 antidepressivaanvändare undersökte de två utfall: frekventa läkemedelsbyten, som en grov markör för dåligt behandlingssvar, och sjukhus‑ eller dödsfall i journaler som indikerar förgiftning av antidepressiva. Medan varken star-alleler eller de flesta poäng visade en stark eller tydlig signal för behandlingsbyten, visade de ett meningsfullt mönster för allvarliga biverkningar. Bärare av skadliga CYP2C19-varianter hade ungefär 20–35 % högre odds för allvarliga förgiftningskoder relaterade till antidepressiva i sina journaler, oavsett om de klassificerades med star-alleler eller med topprankade beräkningsverktyg som PharmGScore, PharmMLScore och CADD. Denna relation förblev likartad även när analyser begränsades till fall utan dokumenterat självskadebeteende.
Vad detta kan betyda för framtida ordinationer
Sammanfattningsvis visar studien att väl utformade beräkningsprediktorer kan nå samma noggrannhetsnivå som det traditionella star-allelsystemet, samtidigt som de övervinner dess största svaghet: oförmågan att hantera nya, sällsynta eller komplexa genetiska varianter. Genom att översätta råa DNA-sekvenser till kontinuerliga riskpoäng som fungerar över hela genomet kan dessa verktyg så småningom tillåta kliniker att se bortom en kort lista över kända genotyper och bättre förutse vilka som har högre risk för allvarliga biverkningar av antidepressiva. Innan de används i rutinvård behövs mer validering och integration med andra kliniska faktorer, men detta arbete lägger en stark grund för säkrare, mer personligt anpassad ordinering baserad på omfattande genetisk information.
Citering: Hajto, J., Piechota, M., Krätschmer, I. et al. Computational variant predictors for pharmacogenomics: from evaluation of single alleles to assessment of adverse drug reactions to antidepressants. Pharmacogenomics J 26, 8 (2026). https://doi.org/10.1038/s41397-026-00399-0
Nyckelord: farmakogenomik, antidepressiva, genetiska varianter, allvarliga läkemedelsreaktioner, beräkningsbaserad prediktion