Clear Sky Science · sv
Multimodal bildigenkänning för kulturarv baserad på kvant- och klassiskt multimodalt fusionsnätverk
Varför det är viktigt att lära datorer om forna skatter
Kulturella skatter i museer och arkiv fotograferas i allt större utsträckning och publiceras online, men de flesta av dessa bilder är dåligt märkta eller inte märkta alls. Det gör det svårt för besökare, lärare och forskare att hitta det de söker, och begränsar hur djupt allmänheten kan utforska mänsklighetens gemensamma arv. Denna artikel undersöker ett nytt sätt att automatiskt känna igen och sortera sådana bilder genom att kombinera två idéer som sällan möts: museisamlingar och kvantdatorer.
Från dammiga förråd till digitala samlingar
Museer rymmer idag miljontals föremål, från brons och lackarbete till broderade dräkter. Många institutioner tävlar om att digitalisera dessa samlingar så att vem som helst med internetuppkoppling kan bläddra bland dem. Men när bilder väl ligger online måste de placeras i rätt kategorier—såsom emalj, jade, siden eller brokad—om de ska vara verkligt användbara. Konventionella AI-verktyg ser oftast bara till pixlarna i varje bild. De bortser från de rika textbeskrivningar som kuratorer och historiker fäster vid föremålen, trots att dessa bildtexter ofta nämner material, färger och motiv som inte är uppenbara för ögat. När samlingarna växer blir även klassiska algoritmer utmanade av hastighet, energiförbrukning och komplexitet.
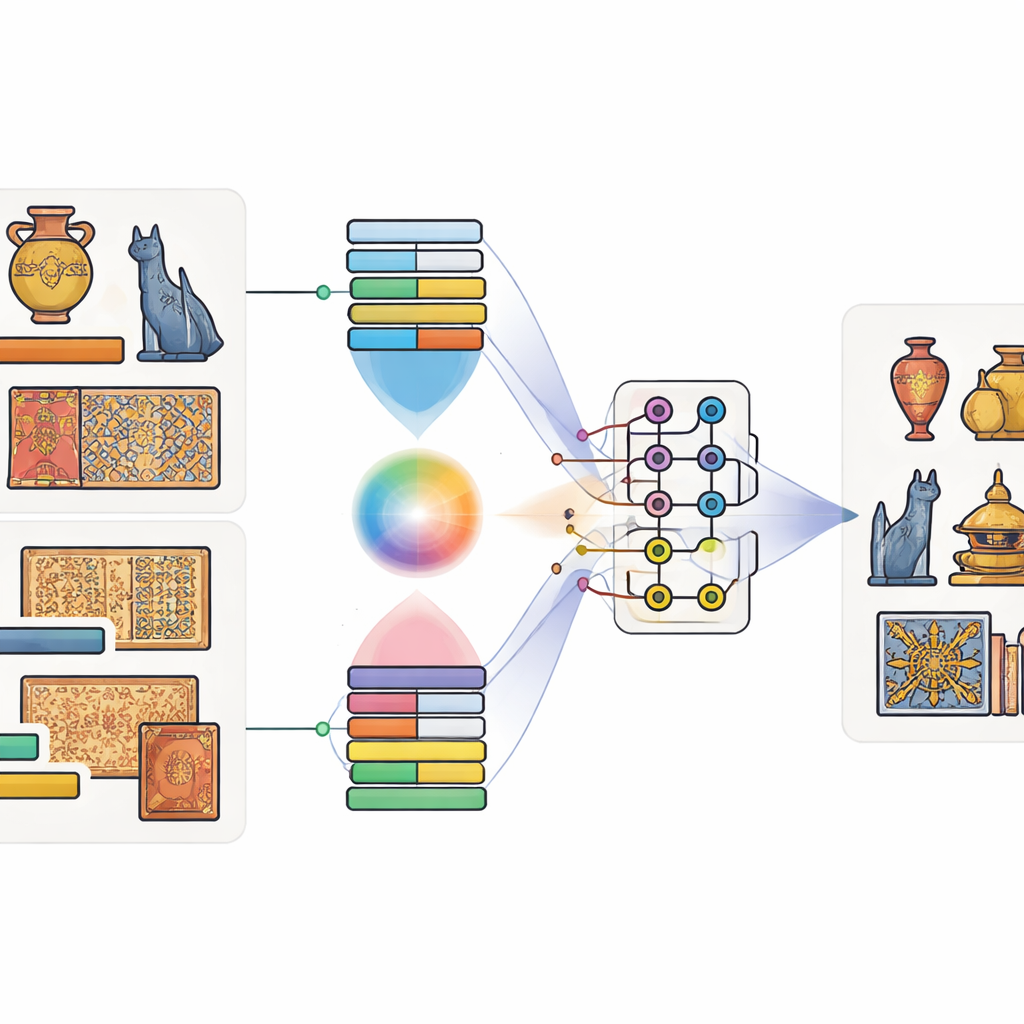
Parning av bilder med ord, och bitar med qubits
Författarna föreslår en modell som de kallar Quantum-Classical Multimodal Fusion Model. "Multimodal" betyder enkelt uttryckt att modellen tar hänsyn till mer än en typ av information samtidigt—in caset både bilden av ett artefakt och dess bildtext. Först används väletablerade verktyg tränade på stora datamängder: ett djupt bildnätverk för att fånga former och texturer, och en språkmodell för att fånga bildtextens betydelse. En särskild uppmärksamhetsmekanism lär sig sedan vilka regioner i bilden som tenderar att höra ihop med vilka ord. Till exempel, när en bildtext nämner "gylldene drake" lär sig modellen att fokusera på guldfärgade regioner formade som en drake. Detta ger en gemensam beskrivning som blandar synintryck och språk.
Låta kvantkretsar blanda signalerna
När bild- och textfunktionerna har extraherats matar modellen in dem i en liten simulerad kvantkrets. Eftersom dagens kvantmaskinvara bara har ett måttligt antal qubits komprimerar författarna informationen med ett schema som packar många klassiska värden i amplituderna hos några få qubits. Inuti den kvantiska delen designar de en tvåstegs-krets som upprepade gånger applicerar rotationer på individuella qubits och sedan sammanflätar dem—vilket tvingar deras tillstånd att bli beroende av varandra. Denna struktur är avsedd att fånga subtila samband mellan visuella mönster och ledtrådar i bildtexter som annars kan gå förlorade. Efter kvantbearbetningen mäts qubitsens tillstånd och omvandlas tillbaka till vanliga tal, som sedan skickas till en slutlig klassificerare som förutser föremålets kategori.
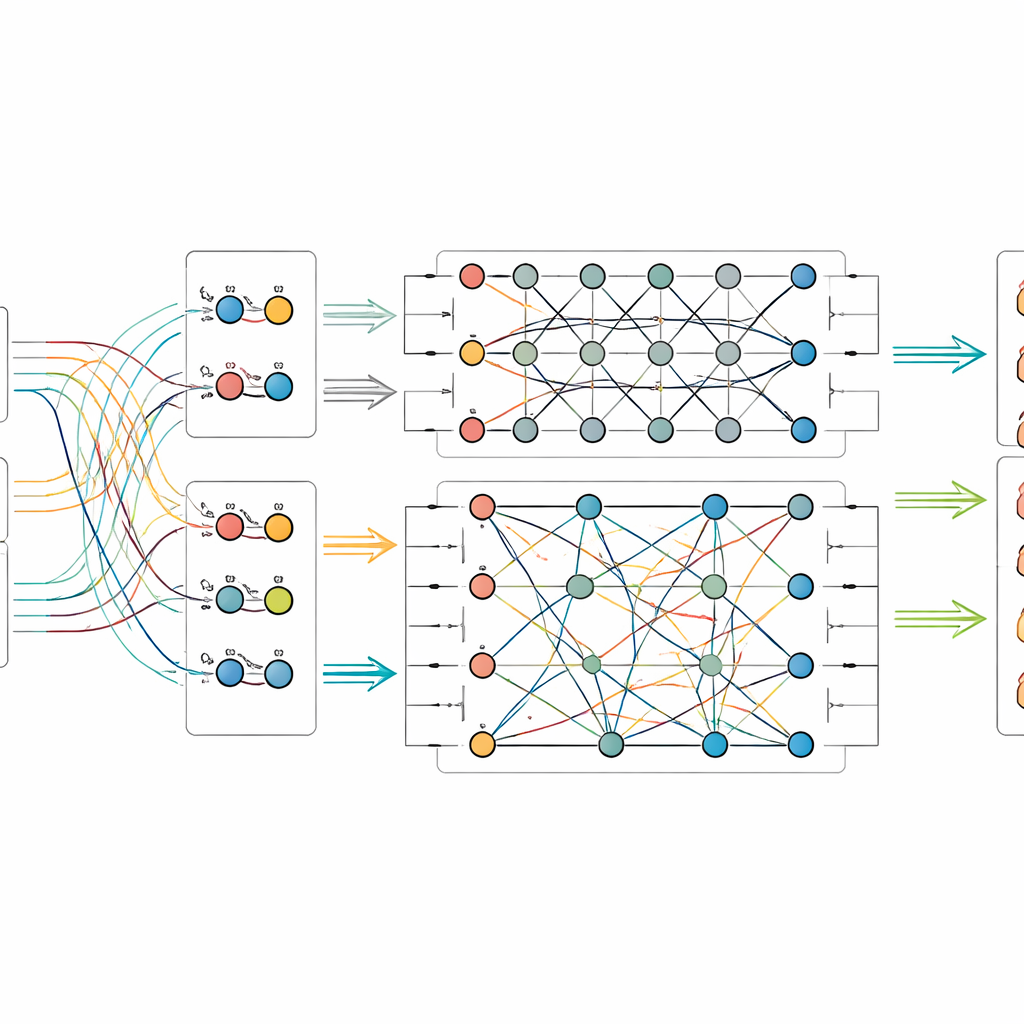
Sätta det nya tillvägagångssättet på prov
För att avgöra om deras metod ger verkliga fördelar sammanställde forskarna två nya dataset från Palatset-museet: ett med fysiska artefakter såsom emalj, guldoch silverarbete, lack, brons och jade, och ett annat som fokuserar på textilier som siden, satin, brokad och den intrikata vävtekniken känd som kesi. Varje bild har en officiell bildtext och en betrodd etikett från museets register. De jämförde sin kvant–klassiska fusionsmodell mot en rad starka konkurrenter, inklusive rena bildsystem, rena textsystem och andra tekniker som kombinerar båda. Över båda dataset uppnådde den nya modellen de högsta resultaten i noggrannhet och relaterade mått, och slog till och med avancerade multimodala och kvantinspirerade baslinjer. Ytterligare experiment visade hur dess prestanda beror på antalet qubits och kretsdjup, och att den förblir robust även när vanliga typer av kvantbuller introduceras i simulering.
Vad detta kan innebära för framtida museibesökare
För icke-specialister är huvudbudskapet att en kombination av bilder, ord och kvantinspirerad bearbetning kan göra datorer bättre på att skilja mellan olika slags kulturföremål. Medan de kvantiska delarna för närvarande körs på simulatorer snarare än fullskaliga kvantmaskiner, antyder studien en väg mot mer effektiva och uttrycksfulla verktyg i takt med att hårdvaran mognar. I praktiska termer skulle sådana system kunna hjälpa museer och arkiv att automatiskt sortera nya uppladdningar, städa upp gamla register och göra det enklare för människor att söka efter "jade-ceremoniella kärl" eller "broderade drakrober" och faktiskt hitta dem. Arbetet antyder att kvantdatorer kan bli en användbar ny väg för att förstå och bevara kulturarvet i den digitala tidsåldern.
Citering: Fan, T., Wang, H., Zhao, Y. et al. Multimodal cultural heritage image recognition based on quantum and classical multimodal fusion network. npj Herit. Sci. 14, 160 (2026). https://doi.org/10.1038/s40494-026-02419-5
Nyckelord: bilder av kulturarv, kvantmaskininlärning, multimodal fusion, museidigitalisering, bildigenkänning