Clear Sky Science · sv
Identifiering av visuell information och frågor/svar om bärare av immateriellt kulturarv med hjälp av ett förstärkt Graph-Retrieval-ramverk
Att föra dolda traditioner in i den digitala tidsåldern
I hela Kina skyddar mästare inom traditionell opera, pappersklippning, skuggteater och andra levande konstarter färdigheter som gått i arv i generationer. Mycket av det vi vet om dessa bärare finns dock bara i spridda filer och bilder på nätet, vilket gör det svårt för allmänheten — och till och med forskare — att hitta tillförlitlig information. Denna artikel presenterar ett nytt datorramverk som automatiskt läser de "visuella visitkorten" för bärare av immateriellt kulturarv (ICH) och sedan använder avancerade språkmodeller för att besvara frågor och generera läsbara rapporter om dem.
Från bildkort till strukturerad kunskap
Många kulturinstitutioner publicerar idag digitala kort som kombinerar text, layout och enkla grafikinslag för att presentera varje bärare: namn, hantverk, plats, biografi med mera. Människor kan ögna igenom dessa på ett ögonblick, men datorer har svårt eftersom korten kommer från många regioner, använder olika designer och ofta innehåller saknad eller skadad text. Författarna bygger en stor datamängd med 5 237 sådana visitkort för kinesiska ICH-bärare, där varje kort noggrant märkts med tio viktiga informationstyper, som projektnummer, projektnamn, region, kön, arbetsenhet och en kort beskrivning. De använder först optisk teckenigenkänning (OCR) för att läsa texten och registrera var varje textstycke förekommer på kortet, och använder sedan stora språkmodeller för att hjälpa till att standardisera etiketter innan mänskliga experter verifierar dem.
Att lära maskiner att läsa layout och mening
För att omvandla varje kort till ren, strukturerad data utformar teamet en "Graph-Retrieval"-modell som efterliknar hur människor använder både ord och layout. Varje textfragment på ett kort blir en nod i en graf, och de rumsliga relationerna mellan fragmenten — till vänster, höger, ovanför, under — bildar kanter. En språkkomponent baserad på RoBERTa och en bidirektionell LSTM lär sig textens betydelse, understödd av en specialordlista med nästan 5 000 ICH-specifika termer så att ovanliga hantverksnamn eller lokala uttryck hanteras korrekt. Ovanpå detta sprider ett grafneuronätverk information över närliggande noder, vilket förbättrar förutsägelser om vad varje textfragment representerar (till exempel att avgöra om ett platsnamn är en region eller en arbetsenhet).
Göra systemet robust mot verklighetens stökighet
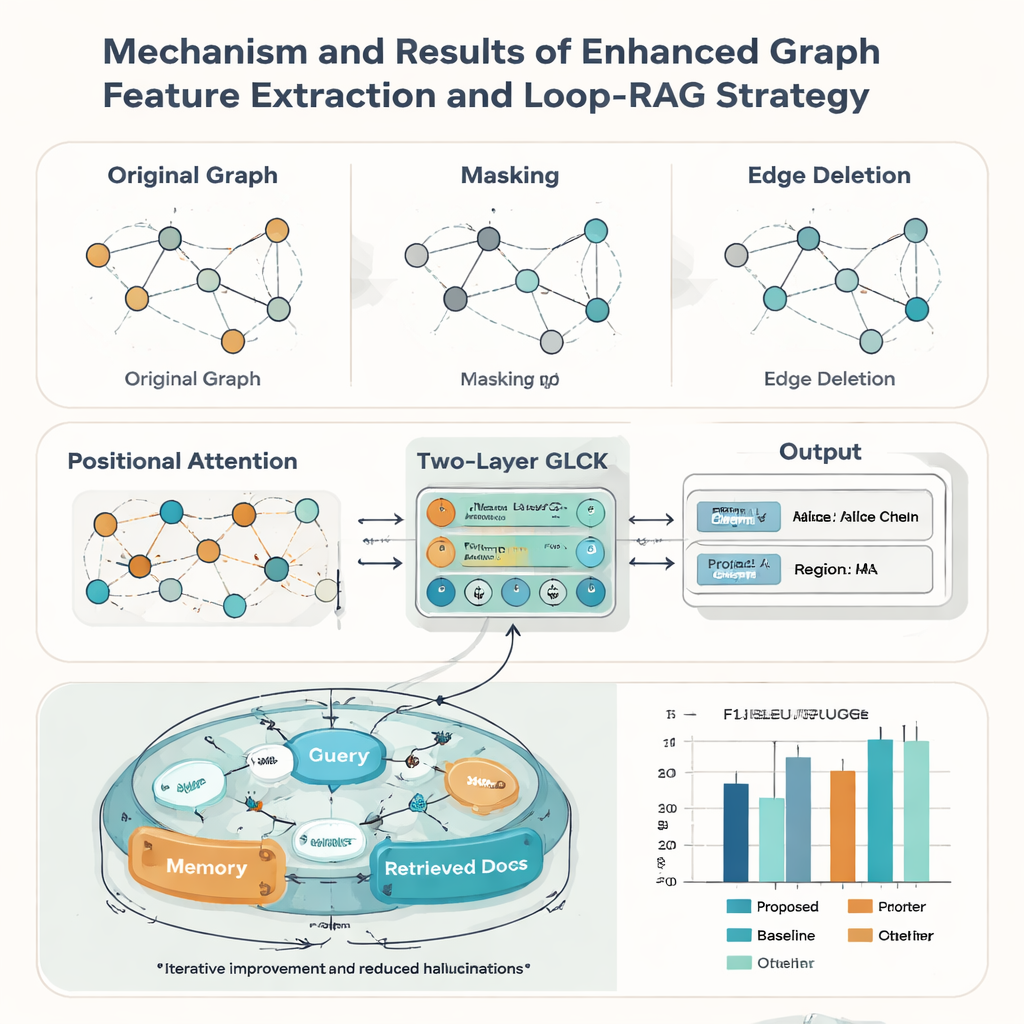
Verkliga kulturregister är sällan perfekta: kort kan vara slitna, beskurna eller dåligt skannade. För att hantera detta stärker författarna sin grafmodell med tre idéer hämtade från dataaugmentation. De maskerar slumpmässigt vissa noder så att systemet lär sig att härleda saknad information från kontext; de tar bort vissa kanter slumpmässigt så att modellen tål förändringar i layout; och de lägger till en positionsbaserad uppmärksamhetsmekanism som fångar det övergripande "läsläget" för element på ett kort. Tillsammans hjälper dessa knep modellen att generalisera till många stilar och dokumentkvaliteter. I tester mot nio välkända rivalmetoder uppnår det nya tillvägagångssättet det högsta makrogenomsnittliga F1-värdet (0,928) på ICH-kortdatamängden och leder även på fem offentliga dokumentbenchmarkar, vilket tyder på att det är brett användbart utöver kulturarvsapplikationer.
Smartare frågesvar med loopande retrieval
Att känna igen texten är bara halva historien; artikelns andra bidrag är en Loop-RAG (Loop Retrieval-Augmented Generation)-strategi som samarbetar med stora språkmodeller som GPT-4, Llama och ChatGLM. Traditionella retrieval-augmented-system hämtar bakgrundsdokument en gång och genererar sedan ett svar, vilket fortfarande kan bli ofullständigt eller felaktigt. I kontrast lägger Loop-RAG till en inre loop som upprepade gånger kontrollerar om språkmodellen har tillräcklig information för det aktuella svaret och, om inte, triggar en ny riktad sökning i en vektoriserad ICH-kunskapsbas. En yttre loop studerar sedan många tidigare interaktioner för att lära vilka sökvägar och promptstilar som fungerar bäst, vilket gradvis minskar slöseri med sökningar och faktiska misstag.
Från råa register till trovärdiga kulturberättelser
Med detta kombinerade ramverk kan systemet automatiskt skapa korta rapporter om en bärare — sammanfatta deras hantverk, region, representativa verk och status — och besvara tusentals faktabaserade frågor om människor och praxis. Mätt med standardiserade språk- och kvalitetsmått som BLEU, METEOR och ROUGE presterar Loop-RAG med GPT-4 bättre än både rena språkmodeller och enklare retrievalupplägg, samtidigt som det når bäst noggrannhet (F1 upp till 0,941) i frågesvar, även när endast några få exempel ges. För en lekmannaläsare innebär detta att framtida kulturarvsplattformar skulle kunna erbjuda interaktiva, tillförlitliga förklaringar av traditionella konstarter på begäran, och förvandla spridda digitala register till rika, navigerbara berättelser som hjälper till att hålla levande traditioner synliga och värderade.
Citering: Wang, R., Zhang, X., Liu, Q. et al. Visual information identification and Q&A of intangible cultural heritage inheritors by using enhanced Graph-Retrieval framework. npj Herit. Sci. 14, 113 (2026). https://doi.org/10.1038/s40494-026-02384-z
Nyckelord: immateriellt kulturarv, informationsextraktion, grafneurala nätverk, retrieval-augmented generation, digital humaniora