Clear Sky Science · sv
Högupplöst 3D-återgivning av kulturarv via superupplösning och progressiv Gaussian splatting
Varför klarare digitala lämningar spelar roll
Museer och arkeologer världen över tävlar om att skapa trogna 3D-kopior av sköra föremål, från porslinsvaser till tempelportaler. Dessa digitala ersättningar gör det möjligt att studera, dela och bevara kulturarv utan att röra originalen. Men i verkligheten är foton av kulturföremål ofta mörka, suddiga eller tagna från svårplacerade vinklar, vilket kan få dagens 3D-återuppbyggnadsmetoder att producera förvrängda eller ofullständiga modeller. Denna artikel presenterar en ny metod som angriper problemet direkt genom att både förbättra indatafotonen och stabilisera 3D-modelleringsprocessen.
När dåliga bilder förstör 3D-modeller
Nuvarande 3D-fångstflöden följer oftast en enkel idé: ta många foton, uppskatta var varje kamera var, härleda objektets form och slutligen rendera en 3D-modell. I praktiken erbjuder kulturmiljöer sällan studiokvalitet. Svagt ljus, slitna eller ojämna ytor, reflektioner från glasmontrar och begränsningar i kameraplacering försämrar alla bilderna. Författarna visar hur dessa brister sprider sig genom kedjan. Suddiga eller lågupplösta foton försvårar för mjukvaran att matcha kännetecken mellan vyer, vilket leder till fel i kamerapositioner och fläckiga djupskattningar. När dessa osäkra mätningar matas in i moderna "Gaussian splatting"-renderare — system som bygger scener av tusentals små färgade klot — kan resultatet bli instabil optimering, redundanta klot och synligt förvrängd geometri.
Skärpning av foton med smartare bildförbättring
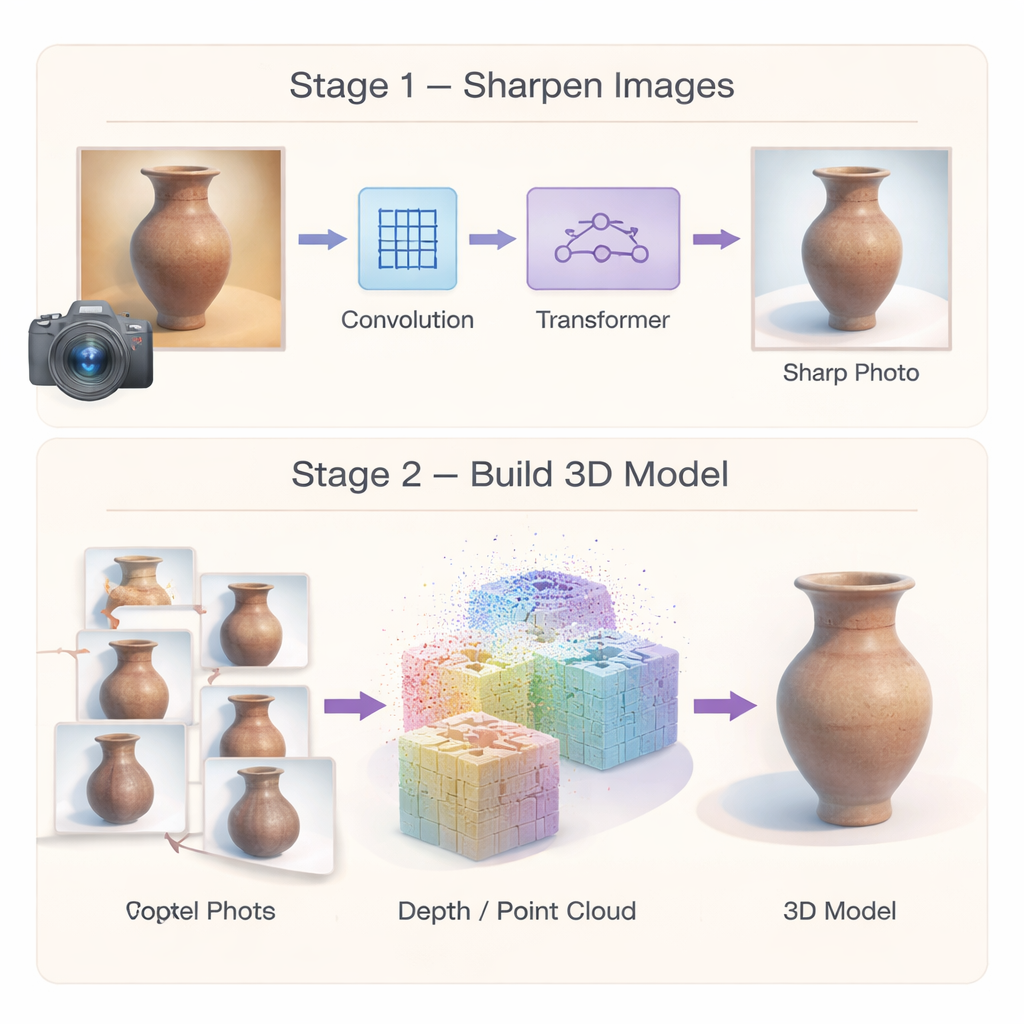
För att stoppa felen vid källan bygger författarna först ett specialiserat bildsuperupplösningsnätverk som förvandlar lågkvalitativa kulturfoton till skarpare, mer detaljerade versioner. Istället för att förlita sig på en enda typ av bearbetning kombinerar nätverket två styrkor. En multiskalig konvolutionsmodul fokuserar på lokala detaljer — som sprickor, penseldrag eller karvade linjer — genom att betrakta bilden i flera grannskapsskalor samtidigt. En effektiv Transformer-modul fångar sedan bredare mönster, såsom återkommande motiv eller långa kurvor som löper över ett föremål. En tredje komponent förstärker selektivt verkligt likartade områden i bilden samtidigt som brus undertrycks, så att svaga strukturer klargörs istället för att suddas ut. Tillsammans producerar dessa element högupplösta bilder som bevarar både fin utsmyckning och övergripande struktur, vilket ger senare 3D-steg en betydligt bättre utgångspunkt.
Bygga stabilare 3D-former från många vyer
Förbättrade bilder räcker inte ensamma; själva 3D-återuppbyggnaden måste också vara robust. Den andra delen av ramverket omprövar hur 3D-modellen initieras och optimeras. Istället för att förlita sig på en gles uppsättning matchade punkter använder författarna en "tät" matchningsmetod som från början producerar rika punktmoln och mer tillförlitliga kamerapositioner. Dessa täta punkter fungerar som ett starkt geometriskt skelett för scenen. Ovanpå detta introducerar de en hybridrepresentation: rummet kring artefakten delas in i grova 3D-celler, och en delad avkodare förutspår detaljerad färg och form för många små klot inom varje cell. Eftersom parametrar i stor utsträckning delas istället för att dupliceras minskar metoden minnesbruket och uppmuntrar till släta, koherenta ytor, vilket gör den slutliga modellen mindre känslig för slumpmässiga knölar och håligheter.
Träna i milsvisa steg istället för allt på en gång
Författarna ändrar också hur systemet tränas. Istället för att tvinga modellen att från början matcha både utseende och geometri — en snabb väg till att fastna i dåliga lösningar — antar de en trestegsstrategi. Först lär sig systemet enbart att reproducera färgerna i indatafoton, vilket säkerställer global visuell konsistens. Därefter adderas gradvis djupinformation härledd från de täta punktmolnen, vilket vägleder modellen mot rimliga ytor. I det sista steget förfinas småskaliga detaljer genom att upprätthålla konsistens över överlappande bildpatchar från olika vyer. Testat på ett nytt Cultural-Relics-dataset med porslin, möbler, hantverk och textilier, liksom på en standardbenchmark av komplexa utomhusscener, förbättrar denna upptrappade strategi inte bara visuell kvalitet utan minskar även träningstid och minnesanvändning jämfört med ledande alternativ.
Vad detta betyder för att bevara det förflutna
För icke-specialister är huvudbudskapet enkelt: detta ramverk hjälper till att förvandla ofullkomliga musei- eller fältfotografier till renare, mer exakta 3D-repliker av kulturarvsföremål utan att de berörs fysiskt. Genom att skärpa lågkvalitativa bilder, starta från ett stadigare geometriskt skelett och träna 3D-modellen i noggrant kontrollerade steg producerar metoden digitala artefakter som bättre fångar både fin dekor och övergripande form samtidigt som den använder färre datorkällor. I praktiken gör detta det lättare för museer, konservatorer och forskare att bygga pålitliga virtuella samlingar från vanliga fotosessioner, vilket hjälper till att skydda känsliga föremål och dela dem brett med forskare och allmänhet.
Citering: Jia, Q., He, J. High-fidelity 3D reconstruction of cultural heritage via super-resolution and progressive Gaussian splatting. npj Herit. Sci. 14, 84 (2026). https://doi.org/10.1038/s40494-026-02355-4
Nyckelord: digitalisering av kulturarv, 3D-återuppbyggnad, bildsuperupplösning, Gaussian splatting, digital bevarande