Clear Sky Science · sv
Geo-TCAM: en Thangka-bildtextmetod som integrerar ämnesmodellering med geometriledd spatial uppmärksamhet
Antik konst möter smart teknik
Thangka-målningar – de färgstarka rullmålerierna som syns i många tibetanska tempel – är fyllda med små detaljer och flera lager av religiös betydelse. För museibesökare eller onlinesökare utan specialkunskap är mycket av den symboliken svår att uppfatta. Denna studie introducerar Geo‑TCAM, ett artificiellt intelligenssystem (AI) som automatiskt genererar rika, korrekta beskrivningar av Thangka-bilder och hjälper människor världen över att bättre förstå och bevara detta unika kulturarv.
Varför Thangka-bilder är svåra för datorer
Till skillnad från vardagsfotografier är Thangka-verk avsiktligt täta och symboliska. En enda målning kan innehålla en central gudom, dussintals mindre figurer, mönstrade ramar samt specifika handgester, föremål, färger och poser som var och en bär religiös betydelse. Standardprogram för bildtextning klarar ofta enkla scener som ”en hund på en strand”, men kämpar här: de kan namnge huvudbuddhan men missa om han håller en skål eller ett svärd, feltolka hans hållning eller förväxla honom med en annan liknande gudom. Sådana misstag är inte triviala – de kan vända berättelsen och doktrinen som målningen ska förmedla och undergräva dess pedagogiska och kulturella värde.
En ny mall för att beskriva heliga bilder
Geo‑TCAM tar itu med dessa problem genom att kombinera tre idéer: visuella egenskaper på flera nivåer, ämneskunskap om Thangka-konst och geometriledd uppmärksamhet mot nyckelområden som ansikten. Först använder den ett djupt nätverk (ResNet50) för att betrakta varje bild på flera nivåer samtidigt: mellanliggande lager fångar kanter, texturer och enkla former, medan djupare lager summerar den övergripande kompositionen. Genom att föra samman dessa nivåer kan modellen upptäcka både fina detaljer såsom utsmyckningar och den breda layouten av bakgrund och figurer, vilket ger en rikare visuell förståelse än tidigare system som fokuserade på ett enda lager. 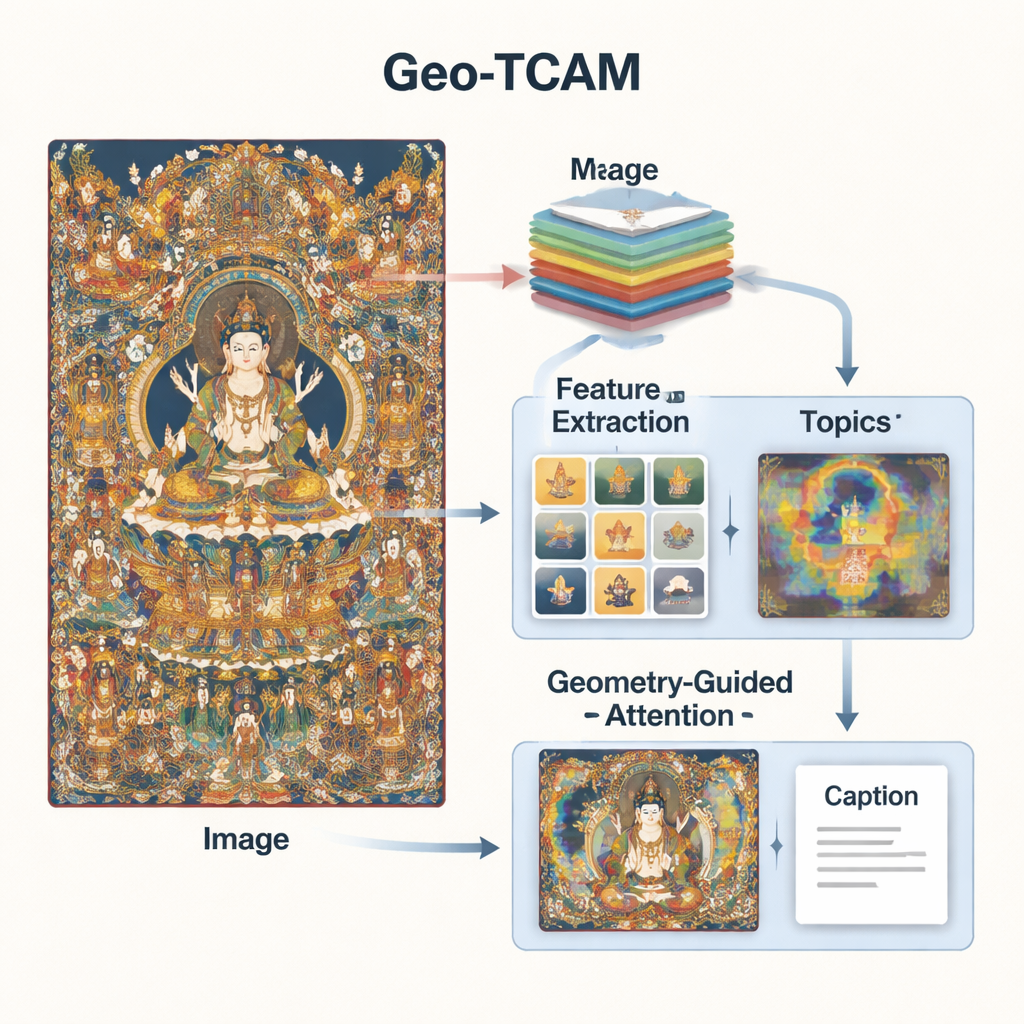
Att lära modellen Thangka-”ämnen”
Synintryck räcker inte; systemet behöver också en känsla för Thangka-språk och teman. För att tillhandahålla detta tränade forskarna en ämnesmodell på tusentals expertskrivna Thangka-beskrivningar. Denna modell grupperar ord i ett fåtal vanliga teman – till exempel de som rör buddhor, bodhisattvor, lotus-throner, ritualföremål eller skyddande gudomar. För varje ny bild uppskattar Geo‑TCAM vilka teman som är mest relevanta och blandar den informationen med de visuella egenskaperna. En uppmärksamhetsmekanism framhäver sedan de bildregioner som bäst matchar de sannolika ämnena. I praktiken gör förhandskunskap om vilka objekt och symboler som tenderar att förekomma tillsammans att AI:n styrs mot mer meningsfulla och kulturkänsliga beskrivningar.
Låta AI:n ”titta” där det spelar störst roll
Den tredje nyheten är en geometriledd ansikts- och rumslig uppmärksamhetsmodul (GFSA). Thangka-kompositioner placerar vanligtvis huvudfigurens ansikte i ungefär förutsägbara delar av målningen. Geo‑TCAM använder enkla kantdetekteringsverktyg för att fokusera på detta område och dess omgivande händer och hållning, och tillämpar sedan en särskild uppmärksamhetsmekanism som ökar dessa pixlars påverkan vid bildtexternas bildande. Denna ”lokalisera först, vägled senare”-strategi hjälper till att förhindra tidig felidentifiering av den centrala gudomen, vilket annars skulle skapa långa kedjor av textfel om gester, attribut och status. Visuella värmekartor visar att med GFSA koncentrerar modellen sig renare på huvudfigurens ansikte och nyckelföremål samtidigt som den behåller viktiga bakgrundsmotiv. 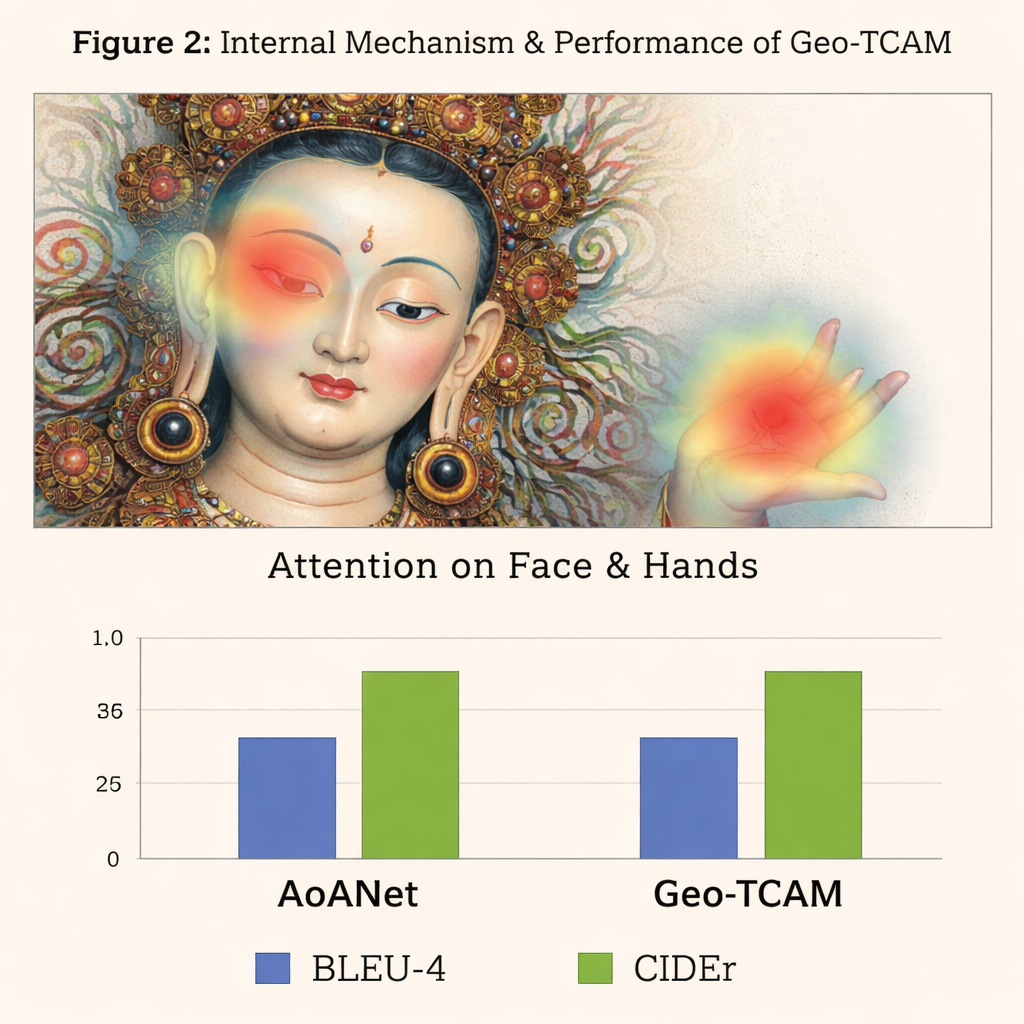
Hur bra fungerar Geo‑TCAM?
För att testa sitt förhållningssätt byggde författarna en specialiserad D‑Thangka-databas med nästan 4 000 noggrant annoterade bilder, var och en med detaljerade experbeskrivningar. På denna datamängd överträffade Geo‑TCAM tydligt flera starka bildtextningssystem, inklusive det populära AoANet och stora visions–språkmodeller. Beroende på mätmetod förbättrades poängen med upp till cirka 120 % över baslinjen, och mänskliga utvärderare föredrog överväldigande dess bildtexter vad gäller korrekthet, flyt och detaljrikedom. Viktigt är att när samma modell utvärderades på en standarduppsättning vardagsfotografier (COCO-datasetet) förblev den konkurrenskraftig med ledande metoder, vilket visar att dess konstruktion är kraftfull men ändå allmänt användbar.
Vad detta betyder för kulturarv och vidare
För icke-experter är huvudslutsatsen att Geo‑TCAM kan förvandla visuellt komplexa Thangka-målningar till klara, informativa berättelser som lyfter fram vem som avbildas, vad de gör och varför dessa detaljer spelar roll. Genom att blanda flerskikig visuell analys, lärda teman från expertt texter och särskild uppmärksamhet på ansikten och gester anpassar systemet sina bildtexter mycket närmare hur mänskliga specialister läser dessa konstverk. På längre sikt kan sådana verktyg stödja digitala arkiv, museiguider och utbildningsplattformar, göra esoterisk religiös konst mer tillgänglig och hjälpa konservatorer och forskare att dokumentera och skydda ömtåliga kulturella skatter.
Citering: Zhong, P., Hu, W., Zhao, Y. et al. Geo-TCAM: a Thangka captioning method integrating topic modeling with geometry-guided spatial attention. npj Herit. Sci. 14, 87 (2026). https://doi.org/10.1038/s40494-026-02343-8
Nyckelord: Thangka-bildtextning, AI för kulturarv, visuell uppmärksamhet, ämnesmodellering, konstbevarande