Clear Sky Science · sv
M3SFormer: mångstegs semantiskt och stil-fusionerat transformer för inpainting av muralbilder
Att återge falnade väggmålningar liv
I tempel och grottor i Kina vittrar antika väggmålningar och rullmålningar långsamt sönder—färgen flagar, ansikten saknas och hela scener har gått förlorade i tidens gång. Konservatorer förlitar sig i allt större utsträckning på digitala verktyg, både för att studera dessa verk säkert och för att föreställa sig hur de en gång såg ut. Denna artikel presenterar M3SFormer, ett nytt artificiellt intelligenssystem särskilt utformat för att "inpainta" skadade muraler och traditionella målningar, fylla i saknade regioner samtidigt som det förblir troget den ursprungliga strukturen, färgerna och konstnärliga stilen.

Varför gamla muraler är så svåra att laga
Att återställa historiska väggmålningar är mycket mer krävande än att laga en familjebild. Muraler innehåller ofta täta mönster, fint penselarbete och skarpa färggränser mellan figurer, kläder och bakgrund. Tidigare djupinlärningsmetoder, särskilt de som bygger på standardkonvolutionella neurala nätverk, fungerar bra för små repor men sviktar när stora partier saknas. De kan sudda ut viktiga linjer, hitta på former som kolliderar med omgivande motiv eller jämna ut de dramatiska kontraster som ger muralerna deras karaktär. Andra metoder komprimerar bildinformationen för aggressivt och kastar bort just de högfrekventa detaljer—fina sprickor, hårstrån, textilstrukturer—that bevarandearbetare värdesätter högst.
En trestegs digital restaureringspipeline
M3SFormer tar sig an dessa utmaningar med en grov-till-fin, flerstegs pipeline. Först delar ett steg kallat Global Structure Reasoning bilden i små patchar och använder en transformer—en modell som ursprungligen utvecklades för språk—för att förstå hur avlägsna delar av muralen relaterar till varandra. Genom att modellera långdistansförbindelser utan den vanliga informationsförlusten från tung kvantisering bygger detta steg en detaljerad, global plan för muralens struktur. Därefter tillför ett steg för Semantic–Stylistic Consistency två slags hög-nivå vägledning: det segmenterar bilden i meningsfulla regioner (såsom ansikten, dräkter eller bakgrund) och använder ett förtränat nätverk för att lära sig de karakteristiska texturerna och färgerna i varje region. Slutligen behandlar ett steg för Flow-Guided Refinement restaureringen som en gradvis utveckling och använder ett inlärt "hastighetsfält" för att föra den initiala gissningen mot ett visuellt sammanhängande slutresultat över flera små steg.
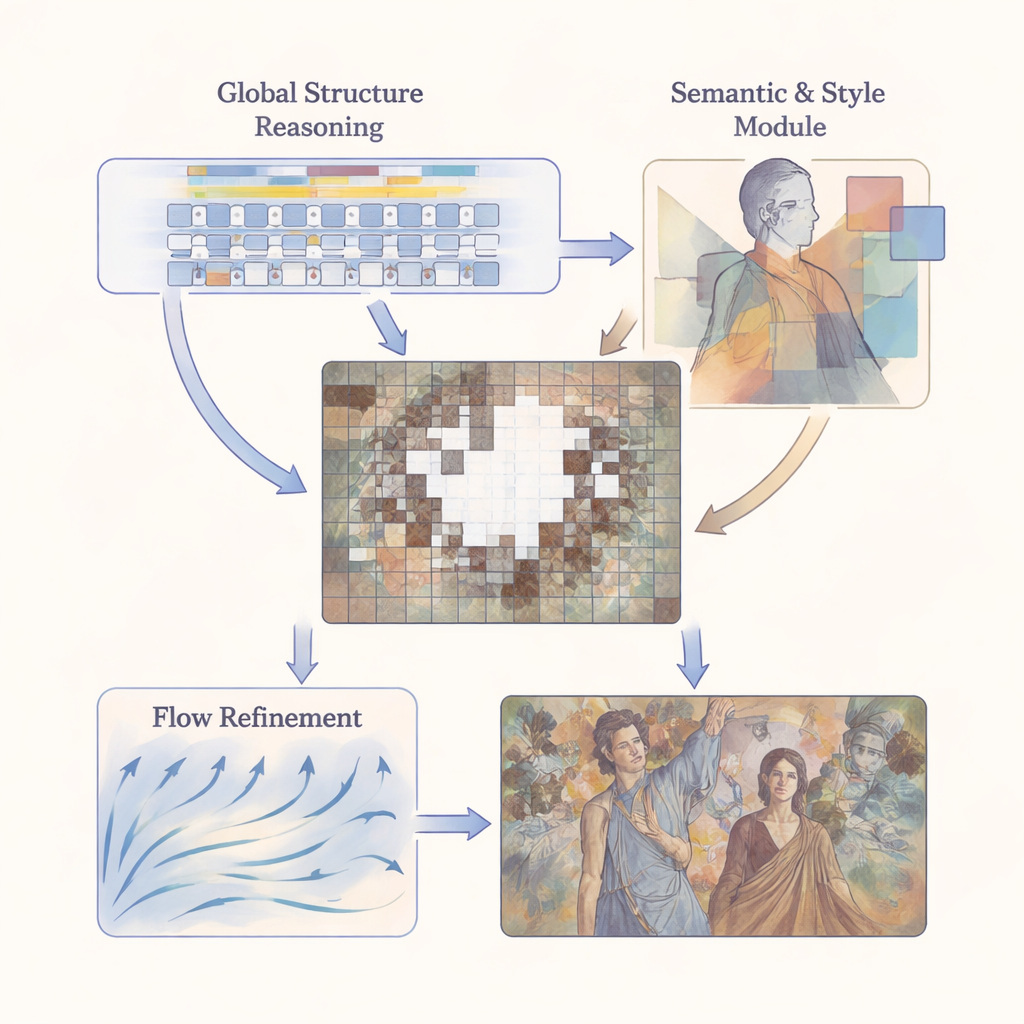
Att hålla struktur och stil i harmoni
En central idé i arbetet är att innehåll och stil måste hanteras tillsammans men inte förväxlas. Modellens semantiska komponent, baserad på ett kraftfullt segmenteringssystem känt som Mask2Former, talar om för nätverket var olika element i scenen börjar och slutar. Ovanpå detta mäter stilkomponenten hur väl de restaurerade regionerna matchar originalet inom varje semantiskt område, genom en flerskiktsjämförelse av funktionsmönster (via Gram-matriser) över flera skalor. Detta gör det möjligt för systemet att behandla en figurs ansikte annorlunda än en mönstrad dräkt eller en molnig himmel, i stället för att applicera en enda global stilregel som skulle jämna ut lokala skillnader. I förfiningssteget fungerar de semantiska maskerna som räcken för flowfältet och säkerställer att ifyllda pixlar utvecklas på sätt som förblir förenliga med både struktur och stil.
Att pröva metoden
För att se hur väl M3SFormer fungerar i realistiska scenarier satte författarna samman två stora dataset: ett med kinesiska muraler från flera regioner och ett annat med traditionella landskapsmålningar. De simulerade skador med masker modellerade efter verkliga sprickor och saknade fragment, och jämförde sedan sin metod med sju toppmoderna alternativ, inklusive både transformer- och diffusionsbaserade system. Över standardmått för bildkvalitet, strukturell likhet och perceptuell realism presterade M3SFormer konsekvent bäst, särskilt när det skadade området var stort och komplext. Visuella jämförelser visar att den undviker den suddning, konstiga färgfläckar och brusiga korn som plågar många konkurrerande metoder, samtidigt som den körs i en praktisk hastighet för verklig användning.
Begränsningar, lärdomar och framtida möjligheter
Trots sina styrkor är M3SFormer inte ett magiskt universalmedel. När den ställs inför mycket stora saknade regioner eller mycket intrikata mönster kan den fortfarande hallucinera detaljer som kolliderar med historisk verklighet—en viktig varning för konservatorer som alltid måste hålla linjen mellan sannolik rekonstruktion och spekulation i åtanke. Författarna föreslår att framtida versioner bör införliva explicita uppmaningar, såsom skisser eller korta textbeskrivningar, för att hålla modellens fantasi förankrad. Även med dessa förbehåll erbjuder tillvägagångssättet ett kraftfullt nytt verktyg för museer och forskare: ett sätt att generera detaljerade, stilmässigt trogna digitala rekonstruktioner, utforska "what-if"-restaureringar icke-invasivt och hjälpa till att säkerställa att sköra kulturella skatter kan studeras och uppskattas långt efter att de ursprungliga pigmenten har falnat.
Citering: Hu, Q., Ge, Q., Zhang, Y. et al. M3SFormer: multi-stage semantic and style-fused transformer for mural image inpainting. npj Herit. Sci. 14, 64 (2026). https://doi.org/10.1038/s40494-026-02325-w
Nyckelord: digital muralrestaurering, bildinpainting, kulturarv, transformermodeller, konservatorsarbete