Clear Sky Science · sv
Konstruktion av det ordklassmärkta korpuset av de Tjugofyra historieböckerna (antik-modernt)
Varför gamla krönikor spelar roll i AI-eran
I mer än två millennier dokumenterade kinesiska historieskrivare krig, domstolar, svält och vardagsliv i den omfattande serien som kallas De Tjugofyra historieböckerna. Idag återupptäcks dessa klassiker inte bara av forskare utan också av datorer. Denna studie beskriver hur forskare förvandlade dessa antika krönikor och deras moderna kinesiska översättningar till en noggrant märkt språkdatabas. Denna resurs kan hjälpa artificiell intelligens att läsa, översätta och analysera historiska texter mer exakt — och göra det avlägsna förflutna betydligt mer tillgängligt för allmänheten.
Från dammiga volymer till digital text
Projektet börjar med en grundläggande men överväldigande uppgift: att göra miljontals tryckta tecken till ren, korrekt digital text. Teamet använde två källor — en auktoritativ modern upplaga av De Tjugofyra historieböckerna och en stor online-samling — för att mata ett optiskt teckenigenkänningssystem. De rensade sedan noggrant bort förvrängda avsnitt, rättade feltolkade tecken och tog bort brus som sidhuvuden och sidfötter. Resultatet blev ett parallellt uppsättning filer, en i antik kinesiska och en i modern kinesiska, som troget motsvarade de ursprungliga böckerna men var redo för beräkningsanalys. 
Parbildning av antika meningar med moderna
Eftersom målet var att jämföra hur språket förändrats över tid var det avgörande att rada upp de gamla och nya versionerna mening för mening. Forskarna använde specialiserad aligneringsmjukvara för att först matcha stycken och sedan dela upp dem i motsvarande meningar. Automatiska verktyg gjorde det tunga jobbet, men mänskliga experter granskade varje föreslagen parning, eftersom antik kinesisk grammatik kan skilja sig avsevärt från modern kinesiska. Där mjukvaran snubblade — delade upp ett tankegång felaktigt eller tolkade ett tecken fel — kontrollerade annotatörerna de ursprungliga skannade sidorna och korrigerade den digitala texten så att varje antik mening linjerade väl med sin moderna motsvarighet.
Att lära datorer att se grammatik
Bortom enkel transkription är kärnan i projektet grammatikmärkning. Varje ord i både de antika och moderna texterna märktes med en ordclass-tagg som anger om det till exempel är ett substantiv, verb eller tidsord. Eftersom det inte finns en enhetlig standard för antik kinesiska förankrade teamet sitt system i moderna nationella riktlinjer och anpassade dem sedan till äldre bruk. De utarbetade ett 22-taggssystem som inkluderar en särskild etikett för unika antika verbbruk såsom “orsaka att leva” eller “dö för landet.” Ett anpassat neuralt nätverk — byggt på en språkmodell för antika texter och sekvensmärkninglager — genererade initiala taggar, som sedan kontrollerades och rättades av ett stort team välutbildade doktorander. Strikta överensstämmelsetester mellan annotatörer visade mycket hög konsekvens, vilket bekräftar att det slutliga taggade korpuset både är omfattande och tillförlitligt.
Vad den nya linsen avslöjar
Med det taggade korpuset på plats undersökte författarna några av de mönster det gör synliga. I antik kinesiska dominerar envkastiga teckenord, vilket speglar en berömdt kompakt skrivstil, medan modern kinesiska föredrar tvåteckensord. De vanligaste antika elementen är små grammatiska partiklar såsom “之” och “以,” medan verb och vanliga substantiv tillsammans utgör ungefär hälften av alla ord i båda tidsperioderna. Datamaterialet visar också vilka ord som tenderar att förekomma tillsammans — till exempel konstruktioner som beskriver ämbetsmän, arméer eller diplomatiska uppdrag. Genom att jämföra taggar över antik–modern-paren spårade teamet hur funktioner skiftat över tid: vissa gamla prepositioner och adverb motsvarar nu fulla moderna verb, och vissa verb har fastnat som fasta titlar eller juridiska termer. En fallstudie plockade ut alla ortsnamn och kartlade var de klustrar i olika dynastier, vilket avslöjar hur politiska och ekonomiska centra förflyttades från nordväst till nedre Yangtze-regionen och vidare. 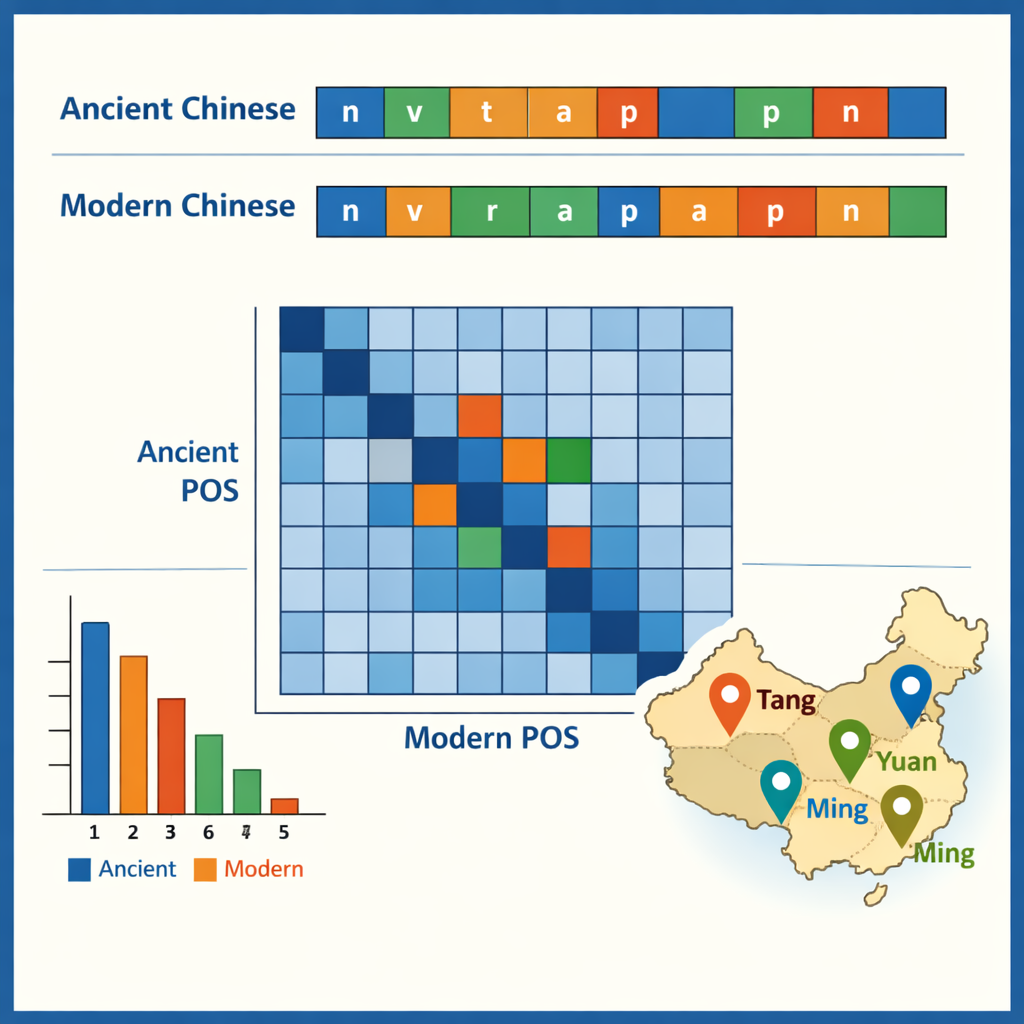
Att föra det förflutna in i den digitala framtiden
Enkelt uttryckt omvandlar detta projekt en mäktig vägg av klassisk prosa till strukturerade data som både människor och maskiner kan navigera. För historiker och lingvister ger det ett kraftfullt verktyg för att följa hur ord, grammatik och till och med statsgränser utvecklats över århundraden. För AI-utvecklare erbjuder det högkvalitativt träningsmaterial för att bygga språkmodeller som faktiskt kan hantera klassisk kinesiska istället för att behandla det som en röra av tecken. Och för studenter och allmänna läsare sänker mening-för-mening-parningen av antik och modern text tröskeln för att läsa klassikerna. Genom att noggrant märka och alignera De Tjugofyra historieböckerna har författarna skapat en bro från de handskrivna rullarna i det förflutna till de intelligenta systemen i nuet och framtiden.
Citering: Ye, W., Xu, Q., Zhao, X. et al. Construction of the twenty-four histories ancient-modern part-of-speech tagged corpus. npj Herit. Sci. 14, 97 (2026). https://doi.org/10.1038/s40494-026-02309-w
Nyckelord: antik kinesisk korpus, ordklassmärkning, digital humaniora, parallella texter, historisk språkutveckling