Clear Sky Science · ru
Тематический анализ с помощью открытой генеративной ИИ и машинного обучения: новый метод индуктивной разработки кодовой книги для качественных данных
Почему это важно для повседневных вопросов
Когда люди заполняют опросы или отвечают на вопросы интервью, они оставляют после себя содержательные рассказы о работе, учёбе, здоровье или жизни сообщества. Прочитать несколько десятков таких ответов легко; понять тысячі — нет. В этой статье описывается новый способ, позволяющий исследователям использовать открытый искусственный интеллект для помощи в обработке больших объёмов письменных комментариев и выделении ключевых идей при сохранении человеческого контроля над интерпретацией. Цель — сделать тщательные, нюансированные качественные исследования возможными в масштабах, которые обычно доступны лишь для статистики больших данных.
Более умный способ читать тысячи комментариев
Авторы сосредотачиваются на популярном в социальных науках подходе — тематическом анализе, где исследователи читают текст и ищут повторяющиеся шаблоны или «темы», отвечающие на их исследовательские вопросы. Традиционно это означает медленную ручную кодировку каждого ответа и построение кодовой книги — структурированного списка тем и подтем. Этот процесс работает хорошо для нескольких десятков интервью, но становится непосильным при десятках тысяч открытых ответов. Статья задаёт вопрос: могут ли общедоступные генеративные текстовые модели и другие открытые инструменты помочь в ранних, повторяющихся этапах работы, не заменяя человеческого суждения?
Представляем рабочий процесс GATOS
Чтобы ответить на этот вопрос, авторы предлагают рабочий процесс Generative AI-enabled Theme Organization and Structuring, или GATOS. Этот рабочий процесс объединяет несколько шагов. Сначала открытая языковая модель читает отдельные ответы и формулирует короткие, сфокусированные пункты-резюме того, что говорит каждый респондент. Затем другой инструмент превращает эти резюме в числовые представления, чтобы компьютер мог сравнивать и группировать похожие идеи. Эти резюме кластеризуются в группы, которые, вероятно, отражают общие темы — например, заботы о балансе работы и личной жизни или недовольство неясной коммуникацией.
Позволять ИИ предлагать, но не наводнять новыми идеями
Наиболее новаторский шаг наступает, когда система начинает составлять черновую кодовую книгу. Для каждого кластера связанных резюме другая генеративная модель рассматривает идеи в этом кластере и уже существующие коды в кодовой книге. Она затем обдумывает, нужен ли действительно новый код или достаточно существующих. Если появляется новый ракурс — например, «надёжные инструменты для видеоконференций» как конкретная проблема — модель предлагает короткую метку и определение, которые добавляются в книгу. Если новый код не нужен, она предпочитает повторно использовать существующие коды. Финальный шаг группирует связанные коды в более широкие темы, создавая структурированную карту от сырых комментариев к организованным инсайтам. На протяжении всего процесса делается упор на избежание потока почти дублирующих кодов при сохранении способности фиксировать тонкие отличия в опыте людей.
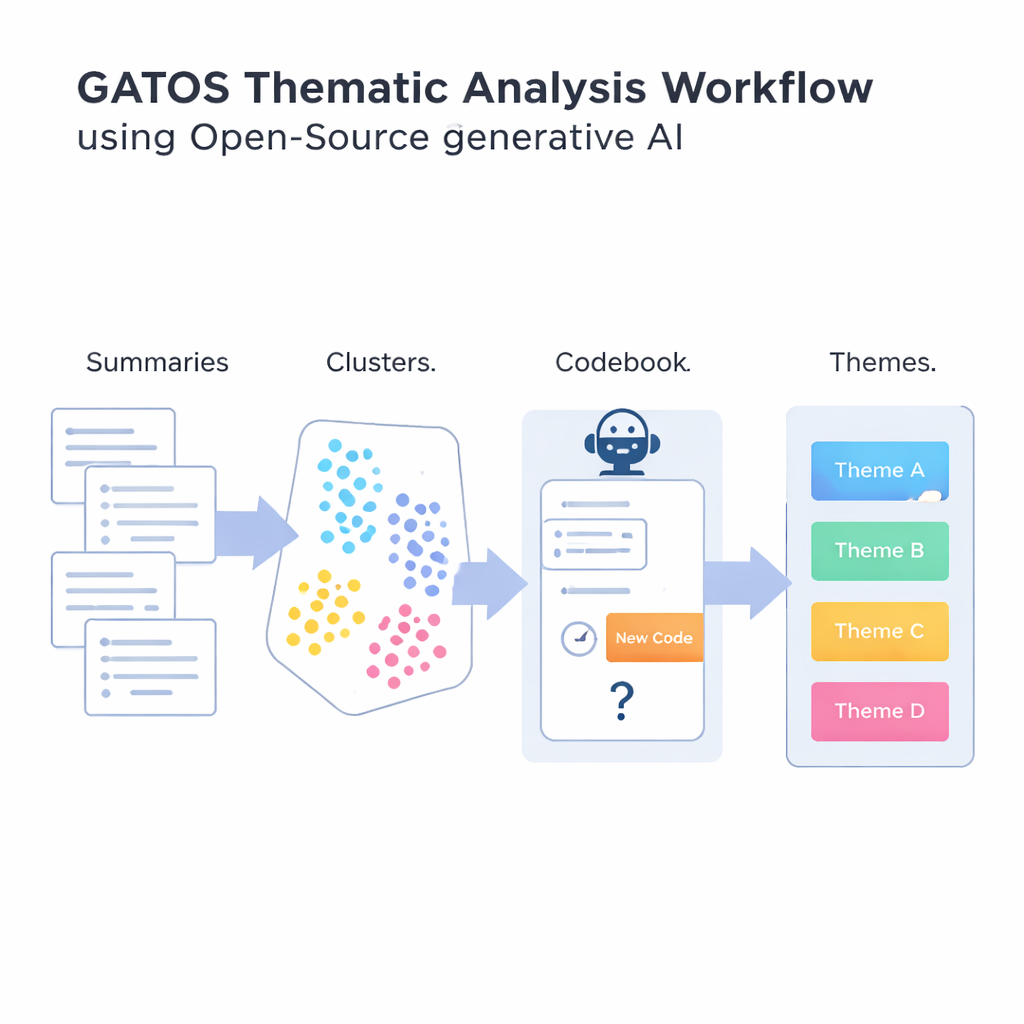
Тестирование метода на реалистичных синтетических данных
Поскольку в реальных исследованиях редко бывает известный «ключ ответов», команда протестировала GATOS с использованием синтетических (сгенерированных компьютером) данных, где скрытые темы были заранее известны. Они создали три большие, правдоподобные наборы данных: отзывы коллег о командной работе, мнения о деловой этике на рабочем месте и взгляды на возвращение в офис после пандемии COVID-19. Для каждого набора сначала были определены восемь тем и несколько подтем, затем языковая модель сгенерировала сотни реалистичных ответов от разных персонажей — например, от членов профсоюзов, менеджеров или студентов. После запуска GATOS люди-ревьюеры сравнили темы, предложенные ИИ, с исходными скрытыми подтемами, чтобы понять, насколько хорошо они совпадают.
Насколько хорошо это сработало и каковы компромиссы?
Во всех трёх тестовых случаях рабочий процесс восстанавливал большинство исходных подтем довольно точно: подавляющее большинство имели по крайней мере одно сильное соответствие, и лишь немногим не хватало подходящего аналога. Важно, что по мере увеличения объёма данных система предлагала всё меньше новых кодов, что указывает на склонность повторно использовать существующие идеи вместо порождения бесконечных вариаций. Авторы утверждают, что такая открытая, локально выполняемая конфигурация может снизить беспокойство о приватности и упростить другим исследовательским группам воспроизведение результатов. В то же время они подчёркивают, что синтетические данные проще многих реальных ситуаций, что рабочий процесс всё ещё может создавать перекрывающиеся коды, и что людям-исследователям по-прежнему нужно дорабатывать, интерпретировать и оценивать финальную кодовую книгу.
Что это значит для неспециалистов
Для читателей вне академической среды вывод таков: открытый ИИ может помочь социальным учёным и другим исследователям выслушать намного больше людей, не сводя их слова к грубым цифрам. Вместо того чтобы заменять человеческих аналитиков, рабочий процесс GATOS выступает в роли очень быстрого и организованного помощника, который предлагает закономерности и черновые метки, оставляя людям решение о том, что действительно означают эти закономерности. Если дальнейшие исследования подтвердят эти результаты на реальных данных, такие инструменты, как GATOS, могут упростить использование полного богатства высказанных мнений при формировании политик на рабочих местах, образовательных программ и общественных решений, а не опираться только на варианты ответов в виде множества вариантов.
Цитирование: Katz, A., Fleming, G.C. & Main, J.B. Thematic analysis with open-source generative AI and machine learning: a new method for inductive qualitative codebook development. Humanit Soc Sci Commun 13, 209 (2026). https://doi.org/10.1057/s41599-026-06508-5
Ключевые слова: анализ качественных данных, тематический анализ, генеративный ИИ, открытые языковые модели, методы социальных исследований