Clear Sky Science · ru
3D Волшебное Зеркало: восстановление одежды из одного изображения с каузальной точки зрения
Примерка без кабинок
Представьте, что вы делаете один полнотелый снимок на телефон и мгновенно видите себя в 3D, можете прокручивать изображение, менять ракурсы или даже обмениваться нарядами с другом. В этой работе решается основная техническая задача, стоящая за таким «3D Волшебным Зеркалом»: как из обычной 2D фотографии одетого человека получить детализированную 3D‑модель его одежды, не полагаясь на дорогие 3D‑сканы или студийные снимки.
Почему переход от 2D к 3D так сложен
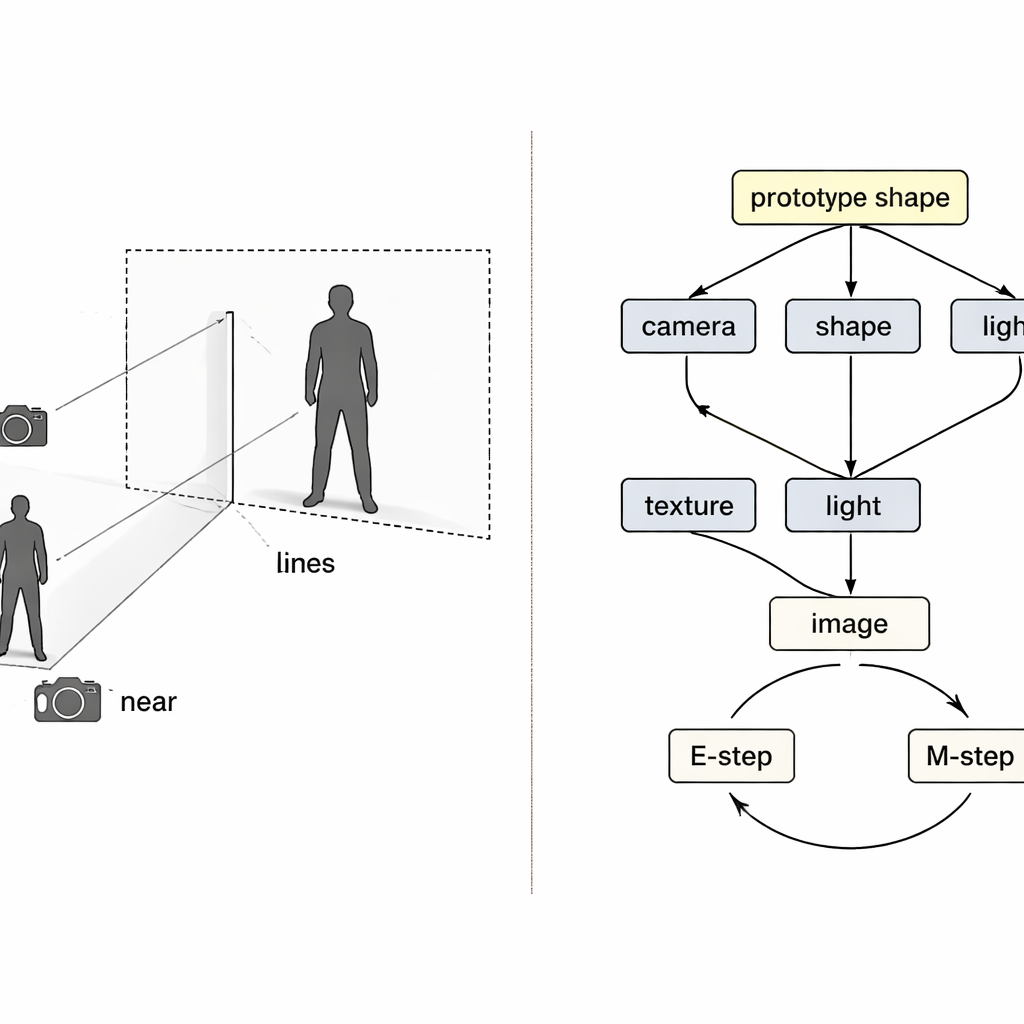
Преобразование плоского изображения в 3D‑объект — классическая задача. Существующие системы часто начинают с фиксированного цифрового шаблона тела и деформируют его под изображение. Это неплохо работает для жестких частей тела, таких как руки или ноги, но даёт сбои для текучих платьев, нависающих пальто, волос или сумок, которые не подчиняются простой стандартной форме. Другой препятствием являются данные: миллионов модных фотографий в сети много, но почти нет крупных наборов точно измеренных 3D‑изделий для обучения. Наконец, одна фотография скрывает важную информацию. Маленькое пальто, снятое близко к камере, может выглядеть так же, как большое пальто, снятое издалека; освещение и рисунок ткани тоже могут ввести модель в заблуждение. Эти неоднозначности мешают нейросети «угадать» правильную 3D‑структуру.
Обучение ИИ отделять причину от следствия
Вместо того чтобы рассматривать задачу как «чёрный ящик» преобразования пикселей в 3D, авторы заимствуют идеи из каузального рассуждения — математики причин и следствий. Они интерпретируют финальное изображение как результат четырёх скрытых причин: положения камеры, формы одежды, её текстуры (цвета и узоры) и освещения. Специальная «структурная каузальная карта» показывает, как эти факторы комбинируются, чтобы дать наблюдаемую картинку. В соответствии с этой картой система использует четыре отдельных нейроэнкодера, каждый отвечает за свой фактор. Вкупе с физически обоснованным 3D‑рендерером они образуют цикл: на вход подаётся изображение и маска переднего плана, на выходе получается цветная 3D‑сетка, которая затем проецируется обратно в изображение для сравнения с оригиналом.
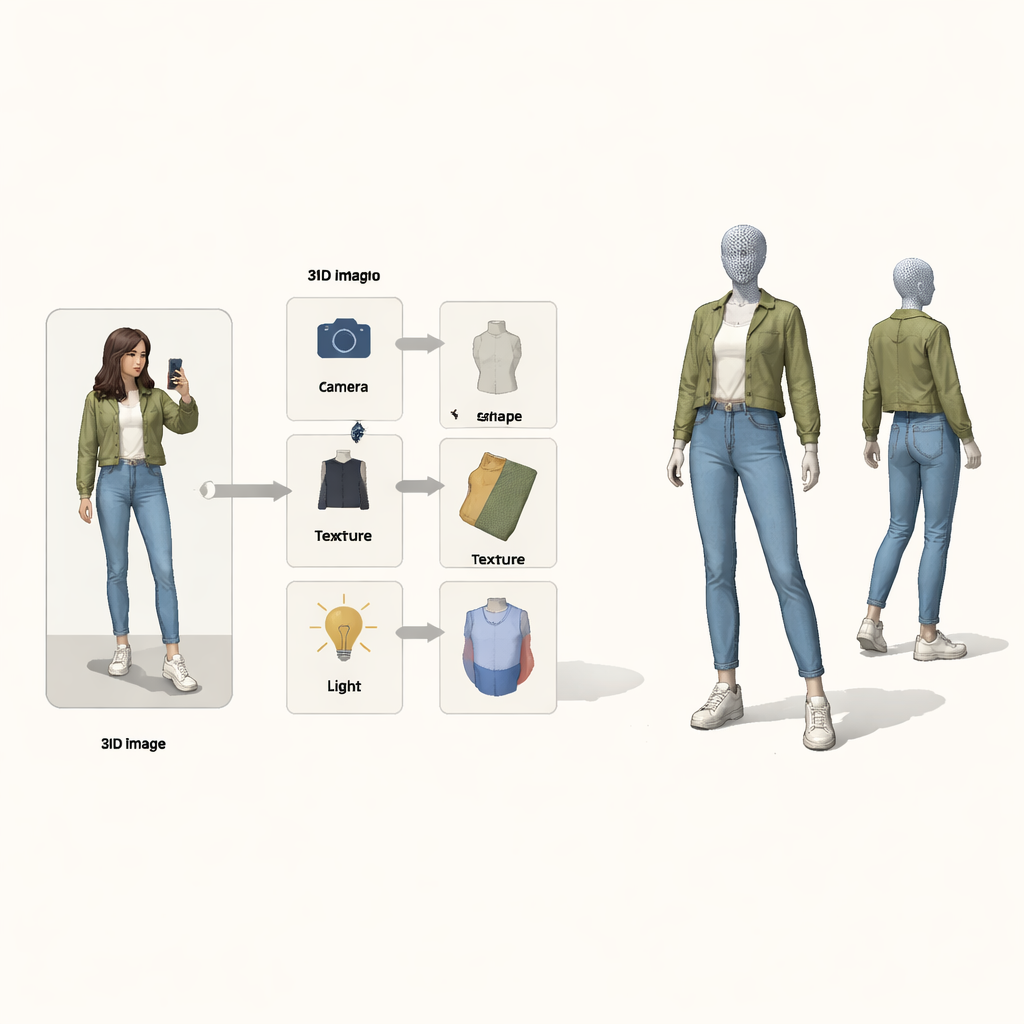
Цикл обучения, который исправляет по одной вещи
Даже при раздельных энкодерах обучение может идти не так. Если реконструкция неточна, непонятно, какой энкодер виноват, и обычное обучение склонно менять их всех одновременно. Авторы рассматривают это как классическую проблему «коллайдера» в каузальности, когда разные причины ошибочно компенсируют друг друга. Их решение — вплести два цикла ожидания–максимизации в процесс обучения. В первом цикле три энкодера временно замораживаются, пока обновляется только четвёртый, чтобы ошибки были однозначно приписаны и компонент выучил более чистую роль. Во втором цикле общий «прототип» 3D‑формы — начинающийся как простая сфера — постепенно обновляется, чтобы стать усреднённой человеческой или птицеподобной формой в данных. Отдельные примеры учатся лишь небольшим отклонениям от этого прототипа, в то время как модуль камеры принимает на себя полную ответственность за то, насколько велик или близок объект выглядит, непосредственно решая путаницу между размером и расстоянием.
От модных фото до птиц и дальше
Чтобы проверить подход, исследователи обучали систему на двух больших наборах модных фотографий с обычными уличными снимками и на стандартной коллекции изображений птиц. Важно, что они использовали только 2D‑маски переднего плана, а не 3D‑эталоны сеток. По одежде на людях их система превосходит популярные методы на основе шаблонов тела в точности совпадения контура одежды и более правдоподобно обрабатывает негибкие элементы вроде волос и сумок. По птицам она достигает или превышает качество ведущих методов 3D‑реконструкции по одному изображению и даёт более реалистичные новые ракурсы. 3D‑модели достаточно гибки для игровых приложений, например для обмена текстурами одежды между людьми или генерации синтетических данных для улучшения систем повторной идентификации людей в исследованиях наблюдения.
Что это значит для повседневных цифровых миров
Для неспециалистов главный вывод в том, что правдоподобные 3D‑аватары и инструменты виртуальной примерки больше не требуют дорогих 3D‑сканеров или жёстких шаблонов. Явно моделируя причинно‑следственные связи — разделяя камеру, форму, текстуру и свет и привязывая их к общему прототипу — авторы показывают, как система может «объяснить» одну фотографию как 3D‑сцену. Хотя метод всё ещё испытывает трудности с видами, которых он никогда не видел, например с задней частью человека, снятого только спереди, это значительный шаг к практичным 3D Волшебным Зеркалам, работающим с неряшливыми, «в дикой среде» изображениями, которые мы реально делаем.
Цитирование: Zheng, Z., Zhu, J., Ji, W. et al. 3D Magic Mirror: clothing reconstruction from a single image via a causal perspective. npj Artif. Intell. 2, 29 (2026). https://doi.org/10.1038/s44387-026-00082-6
Ключевые слова: виртуальная примерка, 3D реконструкция, каузальное обучение, компьютерное зрение, мода и ИИ