Clear Sky Science · ru
Визуальное внимание человека и алгоритмов в задачах вождения
Почему это важно для повседневного вождения
По мере того как автомобили становятся более автоматизированными, остается ключевой вопрос: действительно ли системы автопилота «видят» дорогу так же, как люди? В этом исследовании изучают, как человеческие водители и искусственный интеллект фокусируют визуальное внимание в потоке движения, и показывают, что аккуратное добавление фрагмента человеческого внимания может сделать алгоритмы вождения умнее и безопаснее — без необходимости в гигантских, энергоёмких моделях ИИ.
Как глаза человека перемещаются на дороге
Исследователи сначала поместили новичков и опытных водителей в симулированную среду вождения и отслеживали их движения глаз, пока они выполняли три распространённые задачи безопасности: обнаружение опасностей, оценку безопасности поворота или перестроения и выявление необычных, выбивающихся из контекста объектов. Они обнаружили, что внимание водителей следует надёжному трёхэтапному ритму. На этапе сканирования, сразу после появления сцены, глаза широко просматривают обзор, в основном ориентируясь по расположению объектов. На этапе изучения внимание закрепляется на самой информативной области — например, на переходящем пешеходе или препятствующей машине — и исследует её детали и смысл. Наконец, на этапе переоценки водители сравнивают ключевой объект с другими, переводя взгляд туда и обратно, чтобы подтвердить своё решение.
Куда смотрят машины и куда смотрят люди
Затем команда создала глубокую модель в виде механизма внимания для сцен вождения и сравнила её внутренние «карты внимания» с теми, что получены из движений глаз людей. Обучение модели на общей задаче обнаружения объектов сделало её внимание несколько более похожим на человеческое, но дообучение под конкретные задачи вождения часто отводило её от человеческих шаблонов, особенно в богатой по смыслу фазе изучения. В целом корреляции между человеческим и алгоритмическим вниманием оставались умеренными, что говорит о том, что современным алгоритмам вождения трудно выявить организующие принципы того, куда люди смотрят и почему.
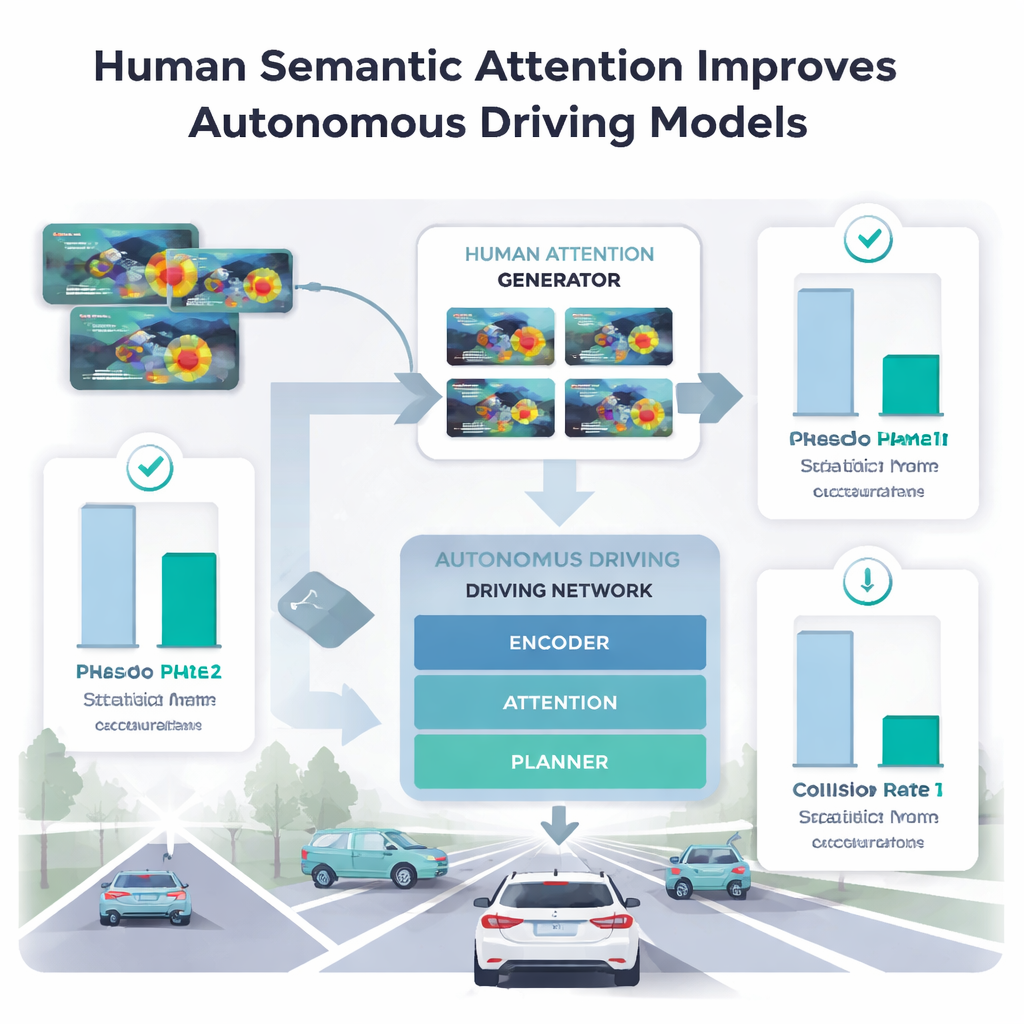
Обучение автомобилей заимствовать человеческий фокус
Чтобы выяснить, какие части человеческого внимания действительно помогают машинам, авторы подавали различные фазы человеческого взгляда в свою модель вождения. Прямой сбор данных отслеживания взгляда для миллионов изображений непрактичен, поэтому они обучили отдельный «генератор человеческого внимания» на небольшой выборке всего лишь пяти водителей. Этот генератор научился предсказывать карты тепла внимания, похожие на человеческие, для новых сцен. Когда основная модель вождения использовала только пространственную, раннюю фазу сканирования, её показатели при обнаружении аномалий и построении траекторий часто ухудшались или приводили к «безопасно выглядящим» траекториям, которые на практике были более склонны к столкновениям. Напротив, при использовании фазы изучения — когда человек концентрируется на одной наиболее значимой области — точность улучшалась по сравнению с предыдущими методами, использующими полный по длине взгляд, а частота столкновений в задачах планирования снижалась.
Чего большим моделям зрения и языка всё ещё не хватает
Исследователи также протестировали крупные модели, объединяющие зрение и язык, которые отвечают на вопросы о вождении или генерируют детальные подписи для 3D уличных сцен. Для задачи вопросов и ответов, требующей высокого уровня рассуждений, добавление человеческого внимания едва помогало и иногда вредило, что подразумевает: такие модели уже захватывают значительную часть необходимого абстрактного знания. Но для требовательной задачи подпиcей, где нужно точно привязать слова к конкретным объектам, внимание человека в фазе изучения по-прежнему давало значительные улучшения. Это указывает на то, что крупные модели могут хорошо рассуждать в целом, но всё ещё испытывают трудности, когда нужно строго связать слова с точными участками в насыщенной визуальной сцене — пробел, который может помочь закрыть человеческий взгляд.
Что это значит для более безопасных автономных автомобилей
Проще говоря, исследование утверждает, что истинное отличие людей от современных алгоритмов вождения — это не только куда мы смотрим, но и как мы мгновенно оцениваем что важно в сцене. Этот компактный всплеск семантического внимания — когда мы внимательно рассматриваем ту одну область, которая делает ситуацию безопасной или опасной — оказывается именно тем сигналом, которого многим алгоритмам не хватает. Научившись имитировать эту фазу по небольшому объёму данных отслеживания взгляда, системы вождения могут приобрести человекоподобное понимание дорожных сцен без опоры исключительно на всё более крупные и дорогие модели ИИ. Этот «семантический шорткат» может стать эффективным способом сделать будущие автоматизированные автомобили надёжнее в хаотичных, непредсказуемых условиях реального трафика.
Цитирование: Zheng, C., Li, P., Jin, B. et al. Human and algorithmic visual attention in driving tasks. npj Artif. Intell. 2, 23 (2026). https://doi.org/10.1038/s44387-026-00079-1
Ключевые слова: автономное вождение, визуальное внимание, отслеживание взгляда человека, модели зрения и языка, безопасность дорожного движения