Clear Sky Science · ru
Роль крупномасштабных языковых моделей в неотложной помощи: всестороннее бенчмаркинговое исследование
Почему это важно для каждого, кто может оказаться в отделении неотложной помощи
Отделения неотложной помощи перегружены как никогда — время ожидания растет, а персонала становится меньше на фоне увеличения числа критически больных пациентов. В этом исследовании поставлен вопрос, который касается почти всех: могут ли современные системы ИИ, известные как крупномасштабные языковые модели, безопасно помогать врачам и медсестрам работать быстрее и эффективнее в условиях неотложной помощи? Пропуская несколько ведущих ИИ через серию медицинских тестов и симулированных случаев из приемного покоя, авторы оценивают, насколько близки эти инструменты к тому, чтобы стать надежными «сопилотами» при оказании срочной помощи.
Отделения неотложной помощи под сильным давлением
Статья начинается с описания усиливающегося кризиса в неотложной помощи, особенно в Соединенных Штатах. Стареющее население и рост числа хронических заболеваний приводят к рекордному числу обращений в приемные покои — примерно 155 миллионов только в 2022 году. Одновременно больницы сталкиваются с острой нехваткой медсестер и врачей, а число коек на душу населения за последние десятилетия сократилось. Фрагментированная система здравоохранения затрудняет координацию помощи, повышая риск задержек и ошибок. На этом фоне авторы утверждают, что необходимы новые инструменты, которые помогли бы клиницистам осуществлять триаж пациентов, принимать быстрые решения и документировать уход, не увеличивая рабочую нагрузку.
Как исследователи тестировали медицинский ИИ
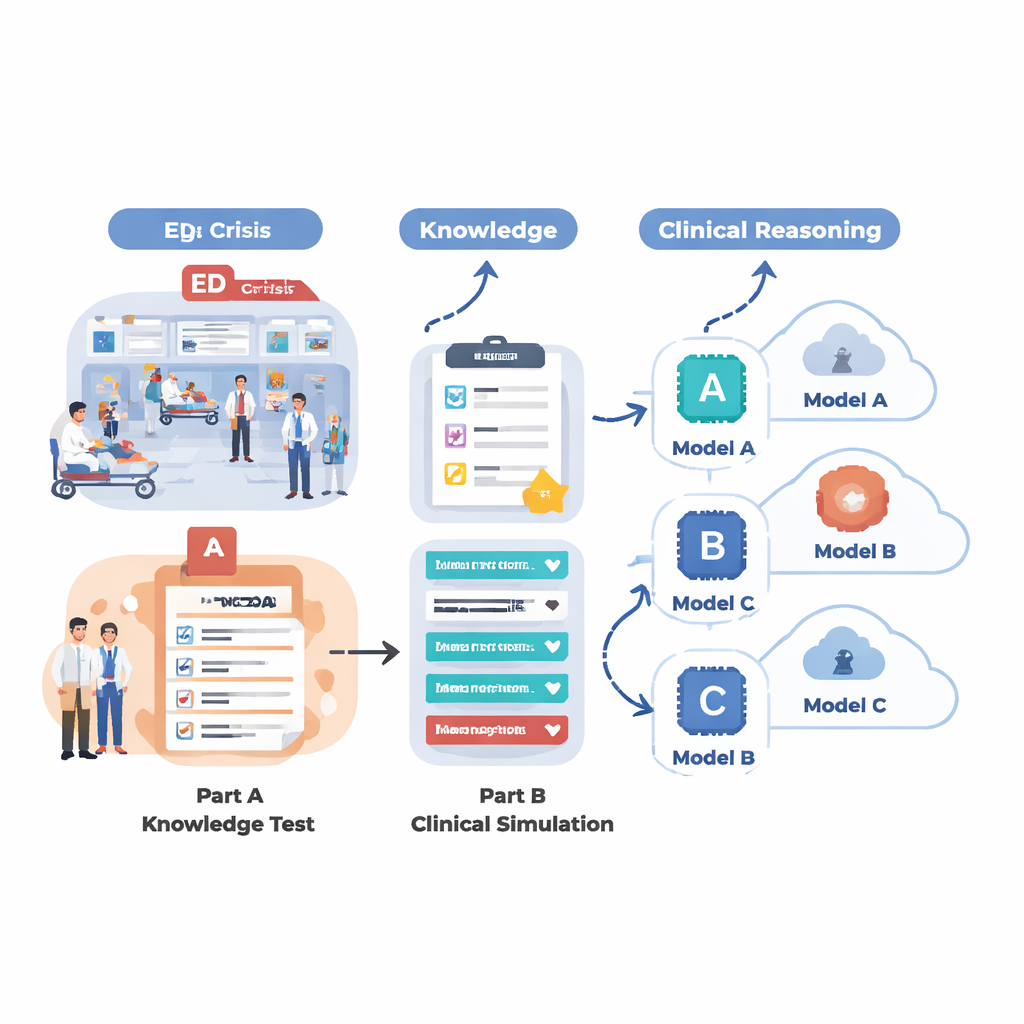
Чтобы понять, на что способны современные системы ИИ в условиях, приближенных к отделению неотложной помощи, команда разработала двухэтапную оценку. Сначала они протестировали 18 различных языковых моделей на большом наборе вопросов с множественным выбором из датасета MedMCQA — экзаменационного по форме набора, охватывающего 12 распространенных жалоб в приемном покое, таких как боль в груди, одышка, головная боль и боли в животе. Этот этап измерял базовые медицинские знания: могли ли модели выбрать правильный ответ из четырех вариантов по тысячам вопросов? Затем из лучших по результатам этого раунда пяти моделей просили последовательно проработать 12 реалистичных экстренных случаев, шаг за шагом, как это сделал бы врач. Для каждого случая ИИ нужно было кратко описать пациента, присвоить балл срочности триажа, предложить ключевые уточняющие вопросы, рекомендовать шаги ведения и перечислить вероятные диагнозы по мере поэтапного поступления новой информации (жизненные показатели, анамнез, данные осмотра, лабораторные и визуализирующие исследования).
Какие модели знали факты — и какие умели рассуждать
По чистому воспроизведению фактов несколько моделей показали впечатляющие результаты. Специализированная система LLaMA 4 Maverick набрала примерно 91 процент общей точности по медицинским вопросам, за ней следовали LLaMA 3.1, GPT-4.5, GPT-5 и Claude 4. Эти ведущие модели последовательно хорошо выступали по разным жалобам, что указывает на возможный приближающийся потолок в знании учебно-справочного медицинского материала у передовых ИИ. Модели среднего уровня заметно отставали — некоторые набирали около 60 процентов и испытывали трудности в ключевых областях, таких как уход за ранами и проблемы с дыханием. Однако при переходе от разрозненных вопросов к рассуждениям в условиях богатых, развивающихся клинических сценариев различия стали более выраженными. В этих клинических симуляциях GPT-5 явно выделялся: он давал наиболее точные и полные сводки, задавал самые полезные уточняющие вопросы, рекомендовал разумные и безопасные последующие шаги и предлагал наиболее подробные и логично упорядоченные списки возможных диагнозов.
Сильные стороны, слабости и вопросы безопасности
Клиницисты тщательно оценивали выводы каждой модели по точности, релевантности и безопасности. GPT-5 не только получил наивысшие общие оценки; это была также единственная модель, чьи показатели оставались стабильными или улучшались по мере усложнения случаев, при этом галлюцинации и серьезные ошибки держались ниже примерно 2 процентов. Другие модели проявляли характерные паттерны слабости. Некоторые склонны были пропускать вторичные диагнозы или ставить незначительные проблемы выше опасных. Другие становились чрезмерно осторожными или расплывчатыми либо слишком быстро фиксировались на единственном диагнозе. В целом большинство систем недооценивали степень тяжести состояния пациентов при присвоении уровней триажа — консервативная предвзятость, которая может привести к задержке неотложной помощи, если ее не скорректировать. Выводы подчеркивают ключевой момент: знание медицинских фактов не то же самое, что надежное встраивание этих фактов в безопасное пошаговое принятие решений в условиях неполной, неструктурированной и меняющейся информации.

Что это может означать для будущих визитов в приемный покой
Авторы приходят к заключению, что хотя несколько современных ИИ теперь соперничают между собой по медицинским знаниям, GPT-5 в частности демонстрирует новый уровень способности к рассуждению, который может сделать его полезным инструментом поддержки принятия решений в отделениях неотложной помощи. Они подчеркивают, что эти системы не готовы заменить клиницистов или действовать автономно. Вместо этого наиболее перспективная ближайшая роль — контролируемый помощник: помощь медсестрам триажа в оценке срочности, составление сводок по пациентам, предложение вопросов или тестов и проверка того, учтены ли серьезные диагнозы. Исследование также отмечает необходимость дополнительных исследований в реальных клинических условиях с надежными мерами безопасности и четкими правилами использования. Для пациентов посыл — осторожный оптимизм: ИИ становится лучше в анализе медицинских проблем, но его безопасное применение в приемном покое будет зависеть от продуманного проектирования, надзора и постоянной ориентированности на поддержку — а не замену — человеческого суждения врачей и медсестер.
Цитирование: Naderi, B., Liu, L., Ghandehari, A. et al. The role of large language models in emergency care: a comprehensive benchmarking study. npj Artif. Intell. 2, 24 (2026). https://doi.org/10.1038/s44387-026-00078-2
Ключевые слова: неотложная медицина, крупномасштабные языковые модели, клиническая поддержка принятия решений, триажа, бенчмаркинг медицинского ИИ