Clear Sky Science · ru
Исправление ошибок умножения-аккумуляции в вычислениях в памяти с помощью LDPC
Почему важно исправлять ошибки вычислений в памяти
Современные чипы для искусственного интеллекта повышают скорость и энергоэффективность за счёт выполнения вычислений непосредственно в памяти, вместо постоянной передачи данных между памятью и отдельными процессорами. Такой подход «вычислений в памяти» экономит энергию, но порождает серьёзную проблему: крошечные электрические дефекты могут переворачивать биты или искажать аналоговые сигналы, тихо снижая точность задач вроде распознавания изображений. В статье описан новый способ автоматически обнаруживать и корректировать эти ошибки на лету, помогая будущему аппаратному обеспечению ИИ оставаться и быстрым, и надёжным.
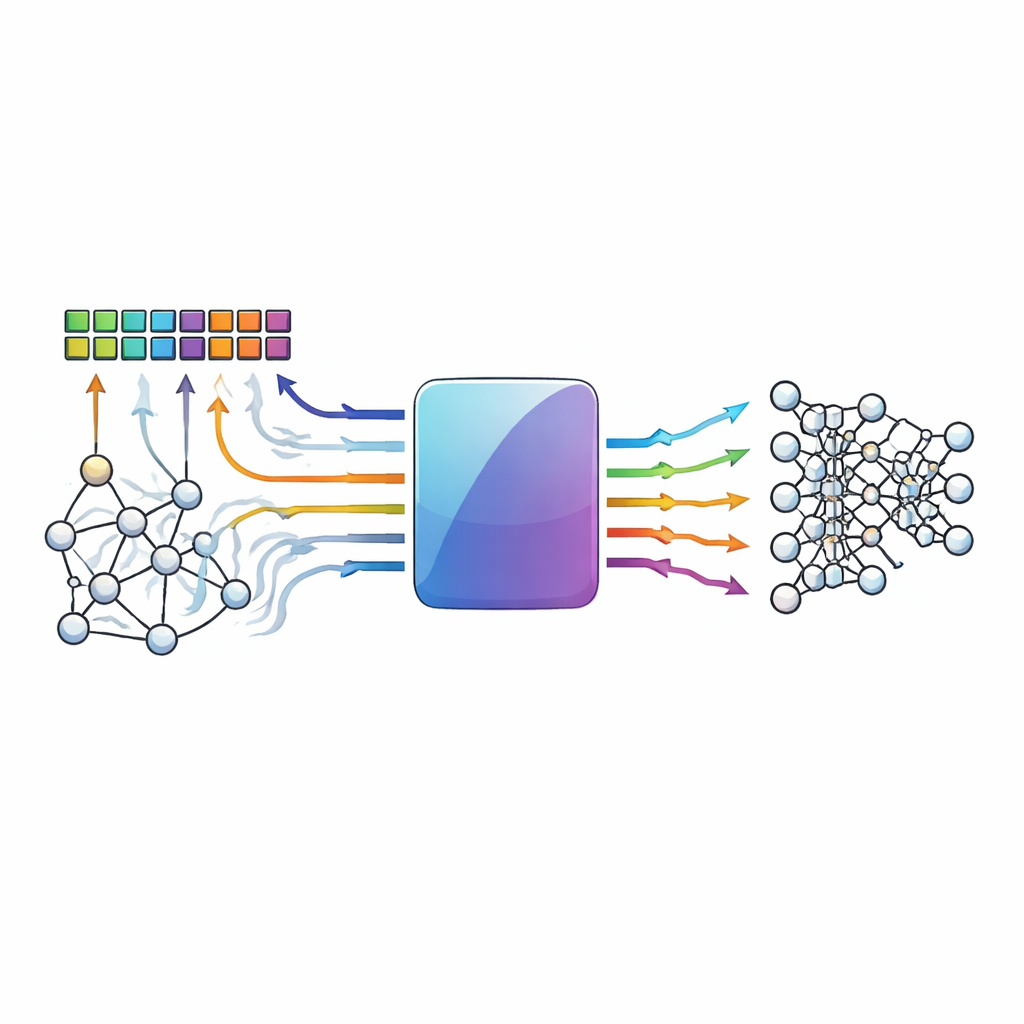
Вычисления там, где хранятся данные
Традиционные компьютеры замедляются из‑за необходимости перемещать данные между памятью и процессором. Архитектуры с вычислениями в памяти избегают этого узкого места, выполняя операции умножения и суммирования — основу нейронных сетей — непосредственно внутри плотных матриц ячеек памяти. Перспективные устройства, такие как резистивная ОЗУ и другие мемристивные элементы, особенно привлекательны, поскольку могут хранить множество значений и эффективно выполнять аналоговые арифметические операции. Однако та же аналоговая природа и вариабельность устройств, которые дают им преимущество, делают их шумными: тепловые флуктуации, разброс параметров и падения напряжения могут сдвигать сохранённые значения или результаты вычислений от их истинных значений.
Когда крошечные сбои накапливаются
В таких массивах памяти одновременно активируются многие строки ячеек, и их вклады суммируются по общим проводникам. По мере участия большего числа строк индивидуальные погрешности складываются, создавая частые и сложные паттерны ошибок. Вместо одного неверного бита проектировщики часто наблюдают множественные ошибки, сгруппированные в одном столбце матрицы или распределённые по нескольким столбцам таким образом, что традиционные приёмы коррекции оказываются бессильны. Стандартные коды обычно предполагают простые паттерны ошибок и короткие слова; они могут пропускать многоразрядные сбои или не иметь записей в таблицах соответствия для редких, но разрушительных сочетаний. В результате точность глубоких нейронных сетей может резко падать даже при относительно небольшой ненадёжности аппаратного уровня.
Новая цифровая страховочная сетка
Авторы предлагают небинарный код с малой плотностью контрольных символов (NB-LDPC), специально адаптированный к аппаратуре вычислений в памяти. Вместо работы лишь с нулями и единицами их схема оперирует малыми группами битов, рассматриваемыми как символы в математической структуре — конечном поле, построенном над простым числом (в данном случае три). Это позволяет одному и тому же коду защищать как обычное бинарное хранение, так и многозначные или дифференциальные кодировки, часто используемые в аналоговых акселераторах. Система добавляет к каждому блоку данных небольшое число дополнительных символов — проверочных символов. Как при обычном чтении памяти, так и при выполнении операций умножения и суммирования в памяти аппарат вычисляет результаты для данных и проверочных символов вместе, поэтому обнаружение ошибок органично вплетено в сам процесс вычисления.
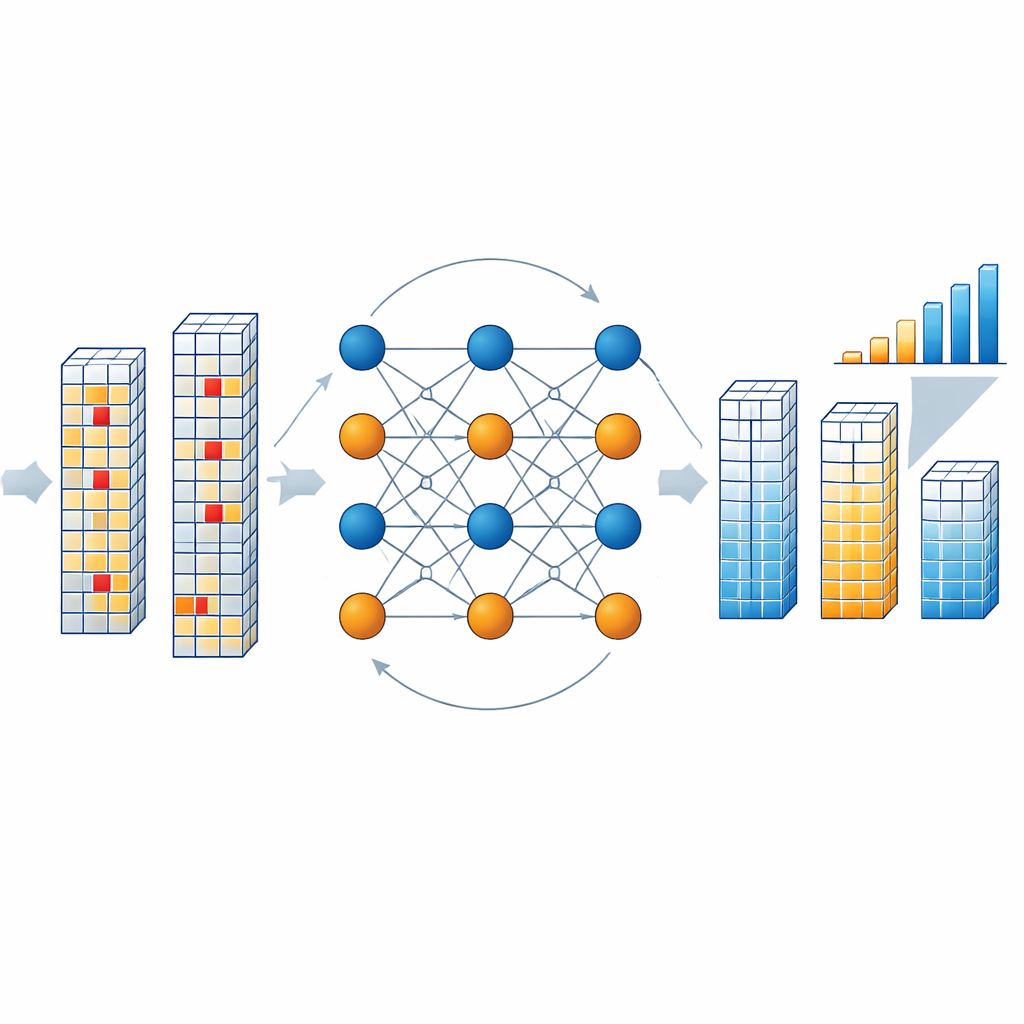
Как движок коррекции работает внутри чипа
При считывании блока результатов выделенный декодер проверяет, соблюдают ли объединённые данные и проверочные символы паритетные соотношения, заданные кодом. Если соблюдают, блок считается чистым. В противном случае декодер запускает итеративный процесс, в котором абстрактные «переменные узлы», представляющие каждый символ, и «проверочные узлы», представляющие паритетные условия, обмениваются сообщениями о вероятностях. Эти сообщения оценивают, насколько вероятно, что каждый символ примет каждое из допустимых значений, на основе наблюдаемых выходов и ожидаемой частоты переворотов битов в памяти. Авторы упрощают эту математически нагруженную процедуру, используя приближения на основе манхэттенского расстояния, что значительно снижает аппаратные затраты при сохранении высокой производительности. После нескольких раундов — обычно трёх — декодер сходится к наиболее правдоподобной откорректированной версии векторa результатов, не требуя повторного чтения памяти и не останавливая поток вычислений.
Силиконовое доказательство и влияние на точность ИИ
Для практической проверки идеи команда изготовила прототипный чип в 40‑нанометровом техпроцессе, сочетающий массив резистивной ОЗУ, лёгкие аналого‑цифровые преобразователи и новый NB‑LDPC‑декодер. При конфигурации, защищающей 256 информационных символов с помощью 32 проверочных символов, декодер достигает высокого кодового коэффициента (примерно 0,8), лучшей измеренной энергоэффективности порядка 88 терабит скорректированных данных в секунду на ватт и лишь умеренных затрат площади, которые можно дополнительно сократить, разделяя один декодер между несколькими макросами памяти. Моделирование для разных размеров кодов показывает, что при защите 1024 информационных символов 128 проверочными символами схема может улучшить скорость ошибок битов почти в 60 раз. При применении к модели классификации изображений ResNet‑34, работающей на аппаратуре вычислений в памяти, коррекция возвращает более 20 процентных пунктов утерянной точности в сложных условиях ошибок.
Что это значит для будущих чипов ИИ
Проще говоря, работа обеспечивает аппаратуру вычислений в памяти надёжным «проверщиком орфографии» для её вычислений, который понимает более сложные наборы символов и запутанные паттерны ошибок, не замедляя поток данных. Объединив защиту для сохранённых данных и вычислений на лету и продемонстрировав эффективную реализацию в кремнии, исследование показывает, что высокоплотные, энергоэффективные ускорители в памяти не обязаны жертвовать надёжностью. Такой специализированный механизм коррекции ошибок может стать ключевым компонентом для создания будущих нейроморфных и ИИ‑ускорителей, одновременно экономичных по энергии и достаточно надёжных для реальных приложений — от мобильных устройств до крупных центров обработки данных.
Цитирование: Shi, D., Fu, Y., Zhu, Y. et al. Correcting processing-in-memory multiply-accumulate arithmetic errors with LDPC. npj Unconv. Comput. 3, 14 (2026). https://doi.org/10.1038/s44335-026-00061-9
Ключевые слова: processing-in-memory, коррекция ошибок, коды LDPC, резистивная ОЗУ, аппаратное обеспечение нейронных сетей