Clear Sky Science · ru
Оценка неопределённости оценок в больших языковых моделях
Почему размытые слова о риске действительно важны
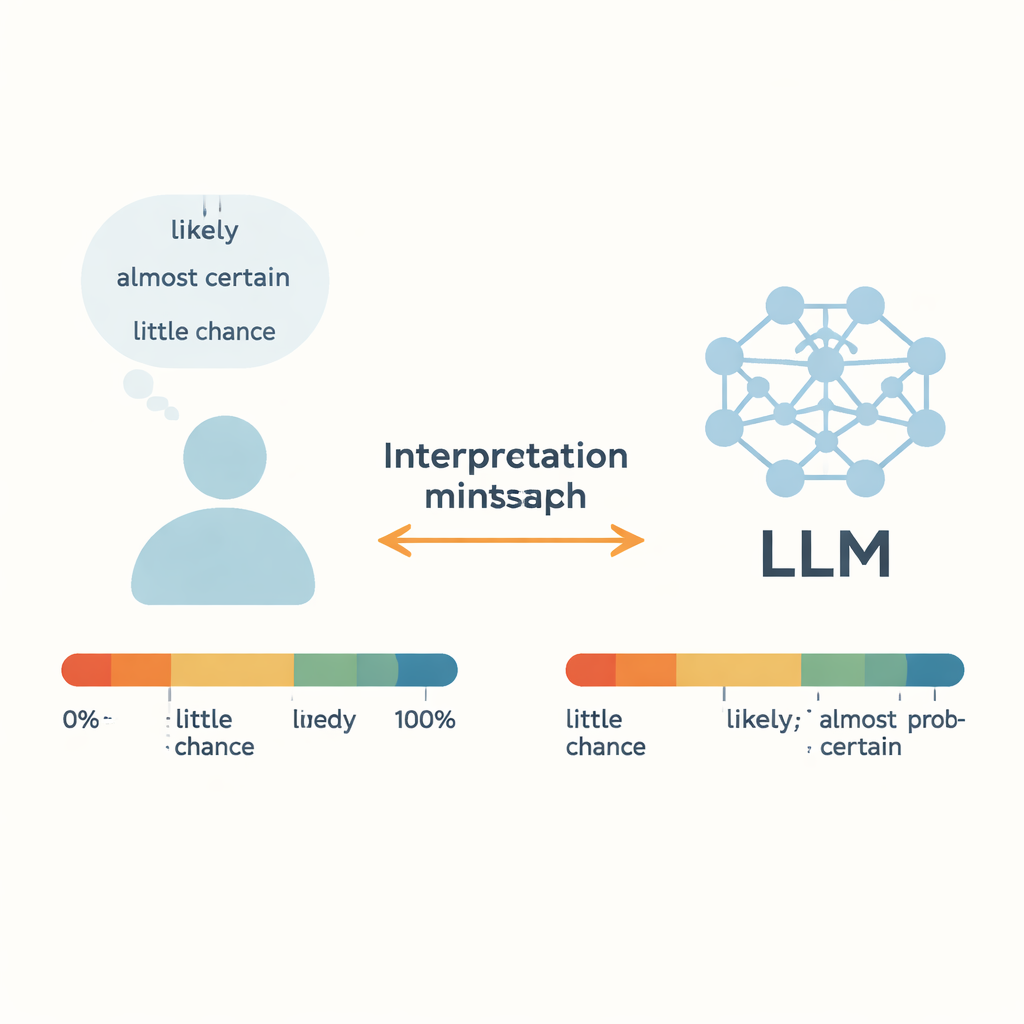
Когда врач говорит, что лечение «вероятно» сработает, или синоптик предупреждает о «малой вероятности» урагана, мы полагаемся на эти расплывчатые формулировки при принятии реальных решений. Сегодня большие языковые модели (LLM), например онлайн-чатботы, начинают использовать ту же лексику. В этом исследовании задаётся простой, но ключевой вопрос: означает ли «вероятно», произнесённое ИИ, то же самое, что и для нас — и может ли модель надёжно превращать числовые данные в повседневные слова неопределённости?
Разбор повседневной неопределённости под микроскопом
Авторы сосредоточились на «словах оценочной вероятности» (WEP) — терминах вроде «почти наверняка», «вероятно» и «маловероятно», которые люди используют вместо точных процентов. Ранние работы, восходящие к аналитикам разведки 1960-х годов, пытались связать эти слова с числовыми вероятностями путём опросов. В этом исследовании авторы сравнили человеческие оценки с выводами пяти современных LLM, включая GPT-3.5, GPT-4, модели Llama от Meta и китайскую систему ERNIE-4.0. Для 17 распространённых слов неопределённости каждой модели предлагались короткие, похожие на рассказы подсказки на английском или китайском языках, и просили ответить числовой вероятностью от 0 до 100 процентов. Повторив это в разных контекстах, авторы построили полные распределения вероятностей для каждого слова и каждой модели, а затем сравнили их с данными опросов людей.
Где люди и ИИ говорят на одном языке
Для самых крайних выражений — например, «почти наверняка» в верхнем диапазоне и «почти нет шансов» в нижнем — LLM и люди согласуются удивительно хорошо. И люди, и модели склонны группировать эти фразы в узкие диапазоны высоких или низких вероятностей, что говорит о том, что такие сильные термины имеют относительно стабильное значение в разных контекстах. То же верно для «примерно поровну», которое большинство людей и модели рассматривают как примерно 50/50. Статистические тесты показывают незначительные отличия между распределениями людей и моделей именно для этих слов, что подразумевает, что LLM способны захватывать явные случаи почти-вероятности или почти-невозможности с человеческой точностью.
Где значения тихо расходятся
Неоднозначные, промежуточные слова рассказывают иную историю. Для выражений вроде «вероятно», «правдоподобно», «мы сомневаемся» и «маловероятно» числовые интерпретации моделей значительно отличаются от человеческих оценок. GPT-4, несмотря на общую большую способность по сравнению с GPT-3.5, часто показывает более крупные расхождения. Авторы предполагают, что это может быть потому, что такие слова смешивают две вещи: ощущение вероятности и позицию или отношение говорящего. В реальных беседах «вероятно» может звучать осторожно или уверенно в зависимости от интонации и контекста, а «мы сомневаемся» может выражать скептицизм, а не точную вероятность. Обученные на огромном, смешанно-жанровом тексте из интернета, LLM могут усреднять противоречивые употребления, размывая эти нюансы. В результате возникает скрытое несоответствие: люди и ИИ могут слышать одно и то же предложение и неявно приписывать одной и той же фразе разные числа.
Пол, язык и культурные отзвуки
Исследователи также тестировали, как гендерные формулировки и разные языки формируют эти слова вероятности. Когда в подсказках использовались «он» или «она» вместо гендерно-нейтральных субъектов, GPT-3.5 и GPT-4 часто выдавали менее вариативные, более «зафиксированные» оценки вероятности, иногда сводящиеся к единственному значению. Это указывает на то, что модели могли усвоить жёсткие шаблоны из стереотипов в обучающих данных, хотя средние значения по мужским и женским подсказкам в целом были схожи. Сравнение английских и китайских подсказок показало заметные сдвиги в интерпретации одних и тех же слов неопределённости у моделей GPT. ERNIE-4.0, обученная главным образом на китайских текстах, была ближе к китайскоязычным людям по многим терминам, но всё же переоценивала или недооценивала отдельные выражения. Эти результаты подчёркивают, что то, как ИИ говорит об неопределённости, зависит не только от выбранного слова, но и от языковых и культурных закономерностей, заложенных в его обучении.
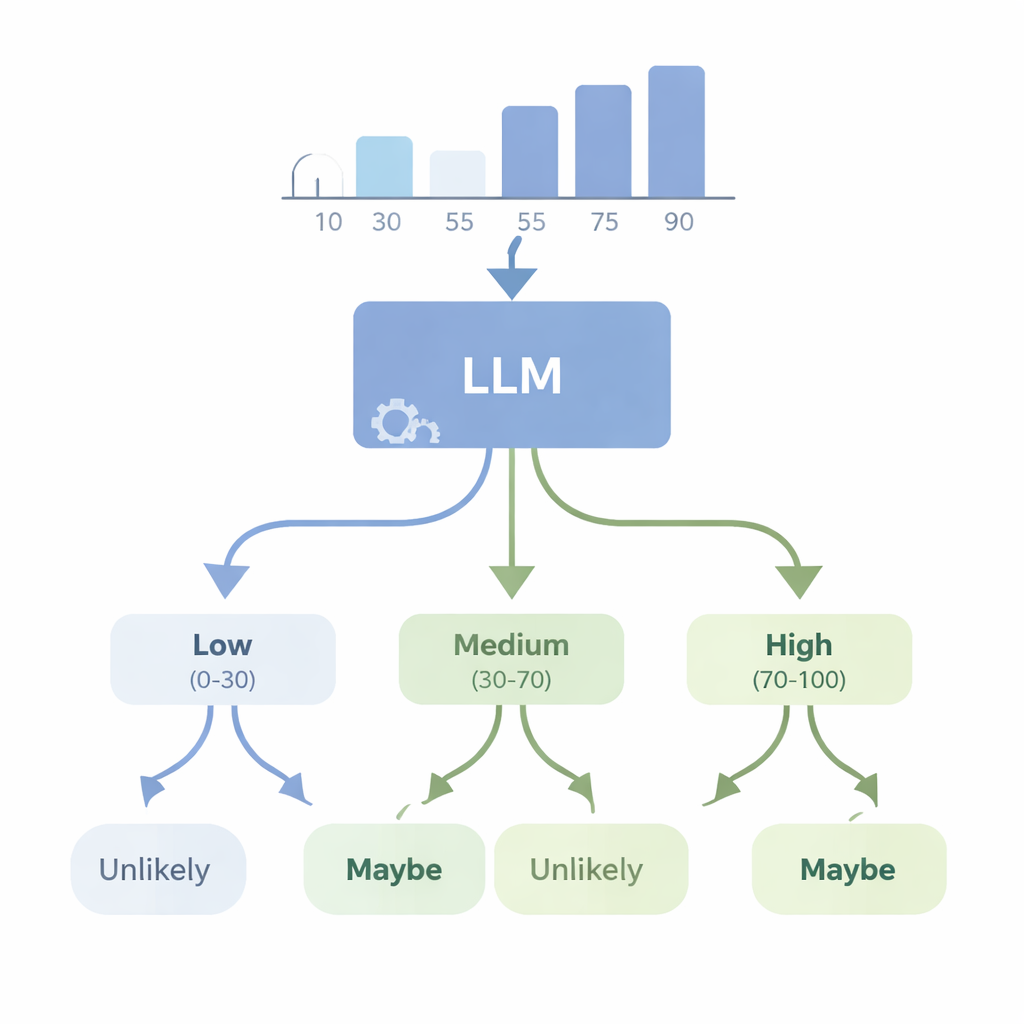
Могут ли ИИ превращать числа в понятное сомнение?
Во втором наборе экспериментов авторы рассматривали обратную задачу: может ли продвинутая модель вроде GPT-4, начиная с числовых данных, выбрать подходящее слово неопределённости? Они давали модели простые наборы данных — например, списки ростов или тестовых баллов — и просили выбрать наиболее подходящее WEP (например, «почти наверняка», «вероятно», «возможно», «маловероятно» или «почти наверняка нет») для утверждений о будущих исходах. Затем GPT-4 оценивали по четырём новым «оценкам согласованности», которые проверяют, логичны ли её выборы слов, когда вероятности повышаются или понижаются, когда описываются дополняющие события и когда исходные числа контролируемо изменяются. GPT-4 справлялась гораздо лучше случайного угадывания и часто могла отслеживать грубые изменения в вероятности, но заметно не дотягивала до идеальной согласованности. В некоторых тестах она реагировала почти одинаково при разных уровнях уверенности, что указывает на то, что иногда модель трактует эти слова как широкие ярлыки, а не как тонко настроенную шкалу, связанную с реальными данными.
Что это значит для реальных решений
Для читателей посыл осторожный, но не панический. LLM уже могут имитировать наши наиболее сильные выражения уверенности и невозможности, и часто способны суммировать данные в разумные утверждения вроде «вероятно» или «маловероятно». Но это исследование показывает, что для многих повседневных слов неопределённости их внутренняя калибровка не полностью совпадает с человеческой интуицией, и их отображение чисел в язык может быть непоследовательным. В областях вроде медицины, политики или научной коммуникации — где небольшие сдвиги в формулировках риска или уверенности могут иметь значение — «вероятно» модели может не совпадать с вашим «вероятно». Авторы утверждают, что чтобы безопасно использовать эти системы, нужно рассматривать слова неопределённости как общий кодекс, который всё ещё требует тщательной настройки, тестирования и, возможно, явной числовой поддержки, а не полагаться по умолчанию на то, что человек и машина понимают друг друга одинаково.
Цитирование: Tang, Z., Shen, K. & Kejriwal, M. An evaluation of estimative uncertainty in large language models. npj Complex 3, 8 (2026). https://doi.org/10.1038/s44260-026-00070-6
Ключевые слова: неопределённость язык, большие языковые модели, слова вероятности, взаимодействие человека и ИИ, интерпретация риска