Clear Sky Science · ru
Когда большие языковые модели надёжны для оценки эмпатической коммуникации
Почему машинная эмпатия важна для вас
Все чаще люди обращаются к чат‑ботам и цифровым ассистентам, когда испытывают стресс, одиночество или стоят перед трудным выбором. Эти системы могут звучать заботливо и понимающе — но способны ли они также судить, действительно ли сообщение было поддерживающим и добрым? В этой статье рассматривается, в каких случаях большие языковые модели (БЯМ), лежащие в основе многих чат‑ботов, могут надёжно оценивать, насколько эмпатичным кажется письменный ответ, и что это означает для повседневных инструментов вроде приложений для благополучия, виртуальных терапевтов и сервисных ботов. 
Изучение поддерживающих бесед
Исследователи проанализировали 200 реальных текстовых разговоров, в которых один человек описывал личную проблему — например, рабочий стресс, семейный конфликт, финансовые трудности или проблемы с психическим здоровьем — а другой пытался ответить поддерживающе. Эти разговоры взяты из четырёх существующих наборов данных, каждый из которых связан с разным набором вопросов для оценки эмпатии. Некоторые фокусировались на том, показывал ли ответчик понимание или оказывал эмоциональное утешение; другие спрашивали, давал ли он практические советы, поощрял ли говорящего рассказать больше, или, наоборот, переключал ли внимание на себя. В совокупности эти рамки разбивают «быть эмпатичным» на 21 конкретное поведение, которое можно оценивать по шкалам, подобно опросу удовлетворённости клиентов.
Эксперты, толпа и машины
Чтобы понять, насколько хорошо БЯМ справляются с оценкой эмпатии, команда сравнила три типа судей: экспертов по коммуникации, онлайн‑выполнителей задач и современные языковые модели. Три опытных исследователя в области эмпатической коммуникации независимо оценили каждый разговор по всем 21 поведению. Толпа — обычные интернет‑пользователи — уже предоставляла оценки для тех же сообщений в предыдущих исследованиях. Наконец, три ведущие языковые модели были тщательно настроены с помощью инструкций на простом языке и примерных оценок экспертов, затем им предложили присвоить баллы каждому разговору по тем же шкалам. Такая схема позволила авторам измерить, насколько близко каждая группа совпадает не просто с «правильным» ответом, но и друг с другом. 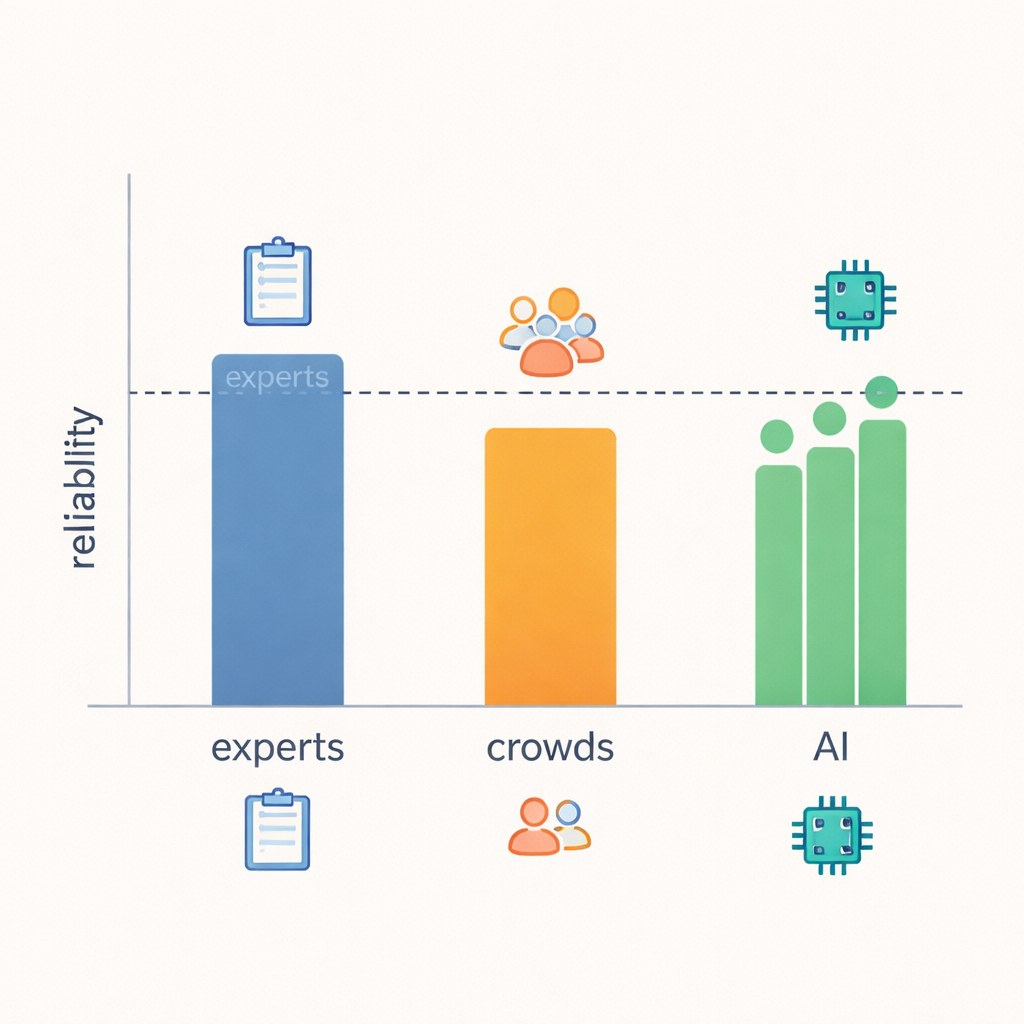
Насколько близко они сходятся?
Ключевой вывод состоит в том, что БЯМ оказались удивительно близки к надёжности уровня экспертов. Когда исследователи измеряли, как часто оценки совпадают и насколько велики разногласия, модели в большинстве из 21 поведения соответствовали или почти соответствовали экспертам и явно превосходили толпу. В областях с чёткими наблюдаемыми признаками — например, давал ли ответ практический совет, задавал ли уточняющие вопросы или возвращал ли внимание к говорящему — эксперты, БЯМ и даже толпа склонялись к большему согласию. Но при оценке более расплывчатых понятий, таких как действительно ли ответ «проявлял понимание» или каковы были намерения ответчика, даже эксперты чаще расходились во мнениях, и надёжность БЯМ снижалась вместе с этим. Это указывает на то, что некоторые аспекты эмпатии просто труднее точно определить по тексту, независимо от того, кто выполняет оценку.
Почему простые метрики могут вводить в заблуждение
Многие исследования ИИ сообщают об успехе, используя привычные метрики классификации — принимая каждую экспертную оценку как бесспорную истину и измеряя, как часто модель с ней совпадает. Авторы показывают, что такой подход может создавать искажённую картину при работе с тонкими человеческими суждениями. Например, система может демонстрировать хорошие результаты, в основном угадывая преобладающую оценку на несбалансированной шкале, даже если она плохо справляется с редкими, но важными случаями. Аналогично, метод, который чаще даёт «почти правильные» оценки — отличающиеся всего на один балл, — может выглядеть плохо при строгой метрике точного совпадения, хотя фактически ведёт себя очень похоже на человека‑эксперта. Сосредоточившись на межэкспертной надёжности — насколько последовательно разные судьи оценивают одно и то же — исследование предлагает более честную картину того, что люди и машины действительно способны оценить надёжно.
Что это значит для повседневного ИИ
Для непрофессионала вывод одновременно обнадёживающий и предостерегающий. Хорошо настроенные БЯМ теперь могут помогать проверять, соответствуют ли письменные ответы — от человеческих помощников или других ботов — экспертным стандартам эмпатической коммуникации, и они часто делают это более последовательно, чем необученные человеческие оценщики. Это может облегчить мониторинг и улучшение чат‑ботов, используемых в здравоохранении, образовании и службах поддержки. В то же время исследование предупреждает, что не все «тесты на эмпатию» одинаково хороши: расплывчатые или перекрывающиеся вопросы приводят к хрупкому согласию людей и, как следствие, к ненадёжным оценкам машин. Прежде чем доверять ИИ оценку чего‑то столь тонкого, как эмоциональная поддержка, следует сначала убедиться, что сами эксперты могут договориться о том, как выглядит «хорошо», и использовать эту эталонную точку для решения, где машины могут безопасно помогать, а где незаменимо человеческое суждение.
Цитирование: Kumar, A., Poungpeth, N., Yang, D. et al. When large language models are reliable for judging empathic communication. Nat Mach Intell 8, 173–185 (2026). https://doi.org/10.1038/s42256-025-01169-6
Ключевые слова: эмпатическая коммуникация, большие языковые модели, ИИ‑компаньоны, поддержка психического здоровья, взаимодействие человек–ИИ