Clear Sky Science · ru
Улучшение предсказания kcat с помощью механизмов внимания, учитывающих остатки, и предобученных представлений
Почему важны быстрые предсказания активности ферментов
Ферменты — это крошечные работяги, которые поддерживают работу клеток и целых отраслей промышленности. Они ускоряют химические реакции, обеспечивающие наш метаболизм, производство лекарств и более экологичные технологии. Ключевой параметр, описывающий скорость работы фермента, — это число оборотов (turnover number), или kcat. Измерять kcat в лаборатории медленно и дорого, поэтому учёные обращаются к искусственному интеллекту, чтобы предсказывать его по последовательности и информации о реакции. В этой статье представлен PMAK — новая модель ИИ, которая не только точнее предсказывает kcat по сравнению с ранними инструментами, но и помогает определить, какие участки фермента наиболее важны для его активности.
От трудоёмкой лабораторной работы к умным предсказаниям
Традиционно определение kcat требует тщательного измерения скорости превращения субстрата в продукт при строго контролируемых условиях, таких как фиксированная температура и pH. Выполнять такие измерения для тысяч ферментов непрактично, что ограничивает возможности моделирования целых метаболических сетей и разработки новых биокатализаторов. Ранние компьютерные методы пытались восполнить этот разрыв, но многие из них опирались на вручную подобранные признаки или давали упрощённое представление о ферменте и единственном субстрате. Они часто работали хорошо только когда новые ферменты были очень похожи на те, что были в обучающей выборке, и испытывали трудности с действительно новыми ферментами, новыми реакциями или инженерными мутантами.
Обучение компьютеров «языку» ферментов и реакций
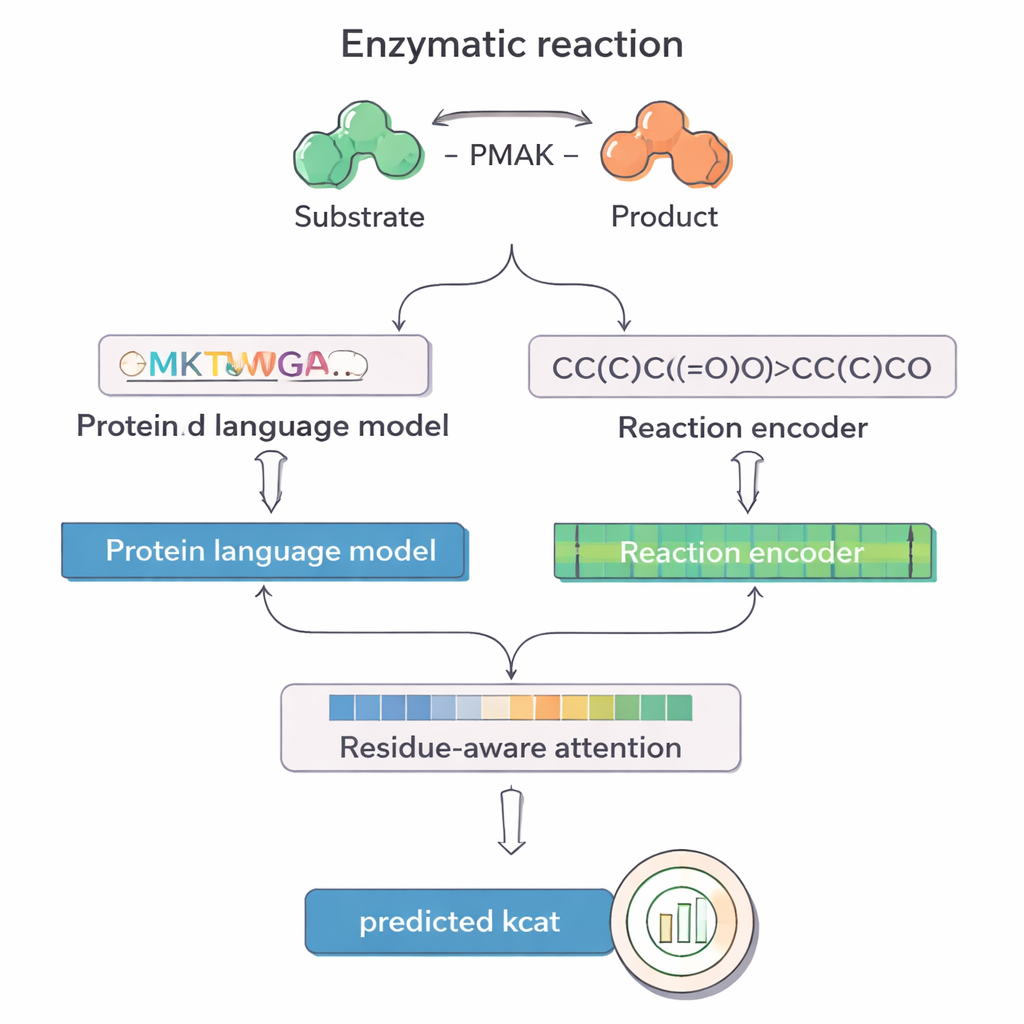
PMAK использует достижения в области «языковых моделей», изначально разработанных для текста, но дообученных на огромных наборах белковых последовательностей и химических реакций. Одна модель, называемая ProT5, превращает аминокислотную последовательность фермента в насыщенное числовое представление, которое захватывает шаблоны, выученные на миллионах белков. Другая модель, RXNFP, делает то же самое для целых реакций, записанных в формате SMILES, который кодирует все реагенты и продукты. PMAK подаёт эти два выученных представления в нейронную сеть, которая согласует их размерности и позволяет модели учитывать как фермент, так и полный контекст реакции вместе, вместо того чтобы рассматривать их по отдельности.
Выделение наиболее важных строительных блоков
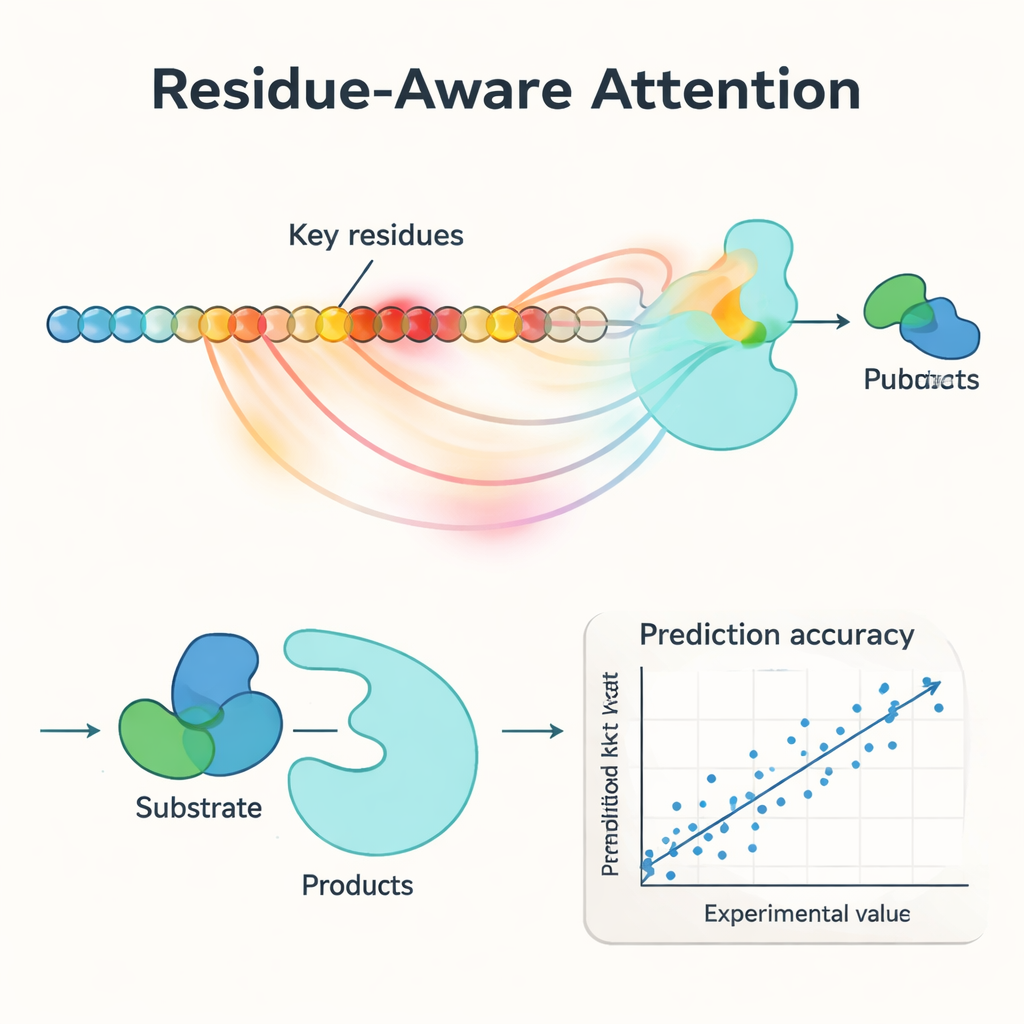
Ключевое новшество PMAK — механизм «внимания, учитывающий остатки» (residue‑aware attention). Вместо того чтобы рассматривать каждую аминокислоту как одинаково важную, модель учится придавать большие веса конкретным остаткам, имеющим наибольшее значение для данной реакции. Эти оценки внимания действуют как прожектор по последовательности: когда исследователи сравнивали их с известными активными и участками связывания, выделенными на структурах белков, они обнаружили, что PMAK систематически подсвечивает функциональные остатки значительно чаще, чем в случайном распределении. Модель также показала хорошие результаты, когда активные сайты определялись шире, включая соседние остатки в трёхмерном пространстве, что указывает на то, что она улавливает тонкие структурные и химические сигналы, важные для катализа.
Хорошие результаты на новых ферментах, новых реакциях и мутантах
Авторы тщательно протестировали PMAK на кураторской базе данных более чем 4000 значений kcat, охватывающей почти 3000 ферментов и 2800 реакций. В условиях «тёплого старта» — когда похожие ферменты и реакции встречаются как в обучающей, так и в тестовой выборках — PMAK соответствовал или превосходил лучшие существующие модели. Ещё более впечатляюще, в тестах «холодного старта», где в тестовой выборке присутствовал фермент или реакция, никогда ранее не встречавшиеся модели, PMAK обошёл ряд ведущих методов. Он оставался полезным даже для ферментов с очень низким сходством последовательностей с обучающими данными и для реакций, существенно отличавшихся от тех, на которых модель училась. PMAK также улучшал прогнозы в реалистичных приложениях, таких как оценка того, как клетки распределяют ограниченные белковые ресурсы, и прогнозирование эффектов мутаций в наборах данных по инженерии ферментов.
Что это означает для биологии и биотехнологии
Для неспециалистов PMAK можно воспринимать как умного помощника, который, обучившись на массивных «библиотеках» белков и реакций, умеет оценивать, насколько быстро конкретный фермент будет работать в заданной реакции — и объяснять, какие аминокислоты определяют это поведение. Сочетая высокую точность с анализом на уровне остатков, такой подход может помочь исследователям проектировать лучшие ферменты, строить более надёжные метаболические модели и изучать, как мутации влияют на функцию, не выполняя каждый эксперимент в лаборатории. По мере расширения подобных моделей на другие кинетические характеристики они могут стать ключевыми инструментами для разработки более чистых промышленных процессов, оптимизации микробов для устойчивого производства и углубления нашего понимания того, как молекулярные машины жизни достигают своих выдающихся скоростей.
Цитирование: Cai, Y., Ge, F., Zhang, C. et al. Enhancing kcat prediction through residue-aware attention mechanism and pre-trained representations. Commun Biol 9, 273 (2026). https://doi.org/10.1038/s42003-026-09551-9
Ключевые слова: кинетика ферментов, глубокое обучение, предсказание kcat, инжиниринг белков, моделирование метаболизма