Clear Sky Science · ru
Совмещение федеративного обучения и «путешествующей» модели повышает эффективность и открывает возможности для цифрового здравоохранения с равным доступом
Почему важно делиться медицинскими выводами, не передавая данные
Современная медицина всё больше опирается на искусственный интеллект для поиска закономерностей в снимках и медицинских записях. Однако данные пациентов конфиденциальны и часто не могут покидать больницу, где они были собраны. Это создаёт противоречие: как больницам по всему миру объединиться для обучения мощных ИИ‑инструментов, не отправляя исходные данные пациентов через границы или в большие центральные серверы? В этом исследовании предложен новый подход, направленный не только на точность, но и на справедливость между хорошо обеспеченными больницами и небольшими, слабо оснащёнными клиниками.
Два способа обучить ИИ, не перемещая данные
Сегодня существуют две основные стратегии, позволяющие больницам совместно обучать ИИ, оставляя данные на месте. В федеративном обучении каждая больница параллельно обучает свою локальную копию модели; эти локальные модели затем объединяются в общий «глобальный» модель на центральном сервере. В подходе с путешествующей моделью существует одна модель, которая перемещается от больницы к больнице и обучается последовательно на каждом сайте. Оба метода защищают приватность, но у каждого есть недостатки. Федеративному обучению трудно, когда у некоторых больниц очень мало данных или они не видят всех типов пациентов; объединение слабых или несбалансированных локальных моделей может привести к глобальной модели, в основном отражающей данные крупных, богатых центров. Путешествующая модель более устойчива к таким дисбалансам, но может быть медленнее и сложнее в управлении.
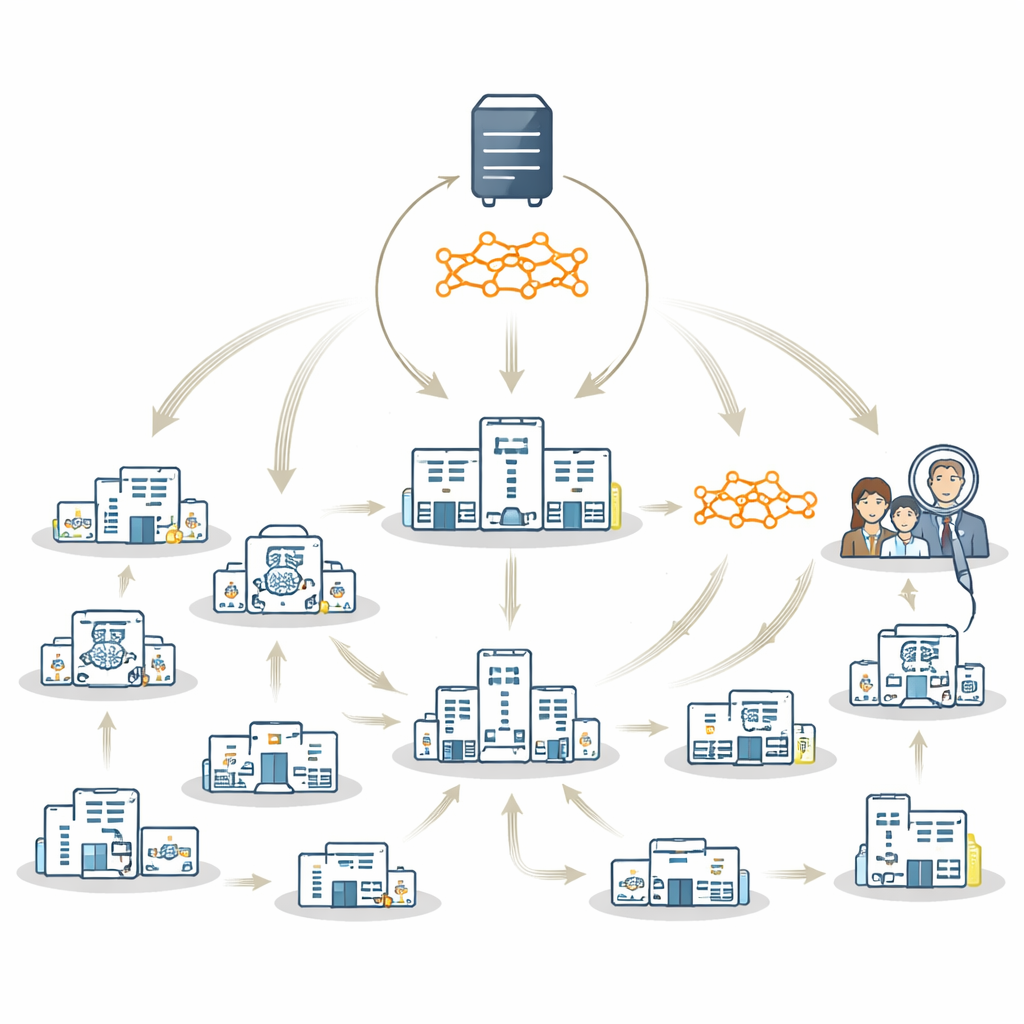
Гибридная стратегия, использующая лучшее из обоих подходов
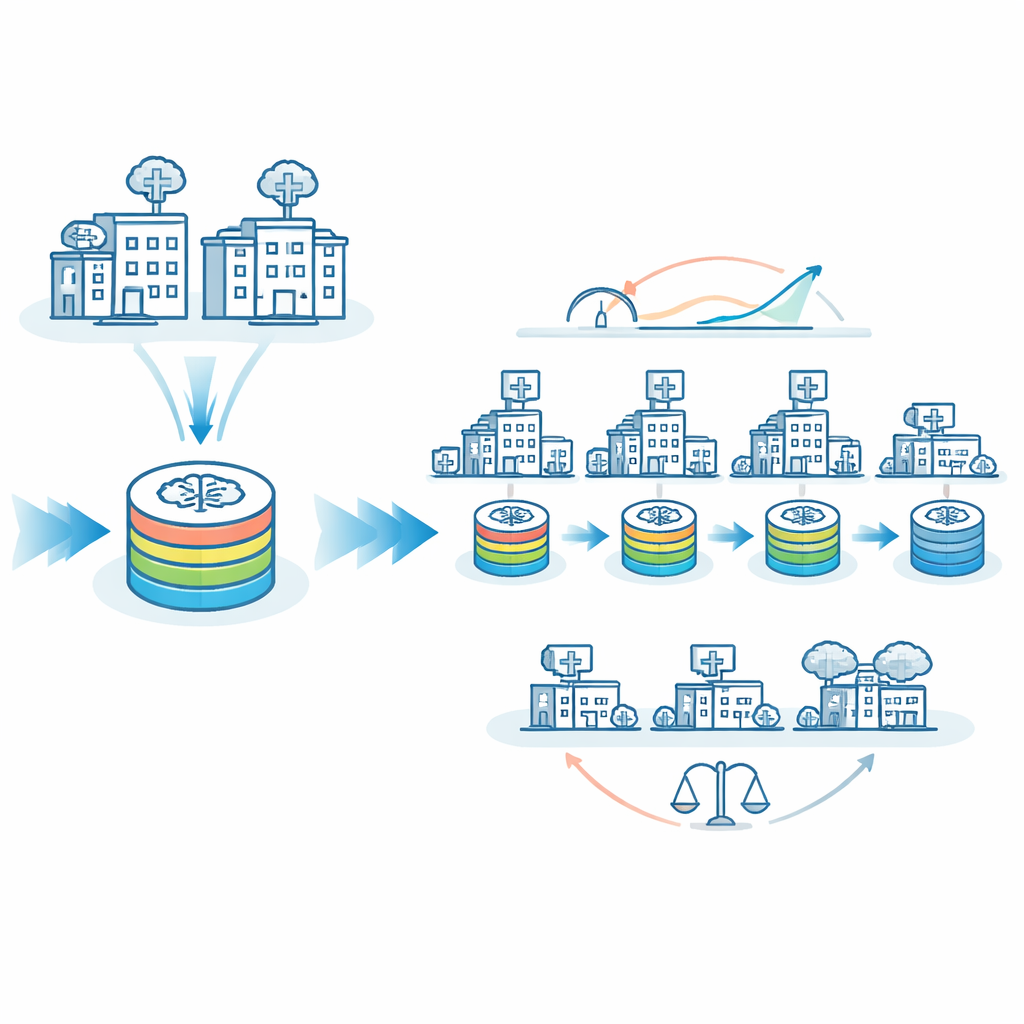
Авторы предлагают FedTM — гибридную схему обучения, которая сочетает сильные стороны федеративного обучения и путешествующей модели. Обучение проходит в два этапа. Сначала идёт «разогревающий» этап, где только крупнейшие больницы с более полными и сбалансированными наборами данных параллельно обучают модель с использованием стандартных методов федеративного обучения. Это создаёт сильную стартовую модель. Затем следует этап «доработки», когда разогретая модель посещает каждый сайт по очереди, включая очень мелкие клиники, где может быть всего несколько снимков мозга или даже один пациент. На втором этапе модель постепенно обновляется по мере путешествия, аккумулируя знания с каждого сайта, не требуя при этом вывоза их данных из‑под локального контроля.
Тестирование метода на снимках мозга при болезни Паркинсона
Чтобы проверить FedTM, исследователи использовали 1 817 МРТ‑снимков мозга из 83 центров по всему миру для обучения ИИ, отличающего людей с болезнью Паркинсона от здоровых участников. Это особенно сложная задача: более половины сайтов внесли менее десяти снимков, только около трети имели данные и по пациентам, и по здоровым контрольным, а протоколы сканирования сильно различались. В таких реальных условиях чистое федеративное обучение не справилось с задачей, тогда как чистая путешествующая модель показала лучшие результаты, но оставляла пространство для улучшений. FedTM, особенно когда этап разогрева включал семь крупнейших и наиболее сбалансированных сайтов, явно превзошла оба подхода: площадь под ROC‑кривой, стандартная мера качества классификации, выросла с 77% при применении только путешествующей модели до примерно 82% при использовании FedTM, с аналогичным улучшением и по другим клинически важным метрикам, таким как чувствительность, специфичность и F1‑score.
Сделать ИИ справедливее для больших и маленьких больниц
Ключевая проблема в медицинском ИИ — это равенство: работает ли модель так же хорошо для пациентов небольших, сельских или слабо оснащённых больниц, как и для пациентов крупных академических центров? Команда проанализировала, как часто ИИ допускал ошибочные предсказания в «больших» и «малых» сайтах. При использовании только путешествующей модели уровень ошибок различался между этими группами примерно на 8 процентных пунктов. При правильной настройке FedTM показатели ошибок для больших и маленьких сайтов стали почти одинаковыми, около 26%. Другими словами, модель стала не только точнее в целом, но и более справедливой. FedTM также перенёс большую часть тяжёлых вычислительных задач на этап разогрева в более обеспеченные сайты, сократив число циклов обучения, которые должны были выполнять маленькие сайты, почти вдвое, при этом сохранив общее время обучения на сопоставимом уровне.
Что это значит для глобального цифрового здравоохранения
FedTM предлагает практический путь к созданию ИИ‑инструментов, которые уважают приватность, улучшают качество и справедливее распределяют выгоды по всему миру. Позволяя даже сайтам с очень небольшим объёмом данных влиять на итоговую модель, эта схема помогает обеспечить, чтобы люди в слабо оснащённых или удалённых условиях не оставались в стороне при разработке новых диагностических инструментов. Хотя исследование было сосредоточено на одном типе снимков мозга и одном заболевании, подход в принципе может быть адаптирован к многим другим медицинским задачам. По мере того как системы здравоохранения всё активнее внедряют мобильные устройства и носимую электронику, а регуляции подчёркивают суверенитет данных, гибридные стратегии вроде FedTM могут стать ключом к построению надёжного, инклюзивного и ответственного медицинского ИИ.
Цитирование: Souza, R., Stanley, E.A.M., Ohara, E.Y. et al. Combining federated learning and travelling model boosts performance and opens opportunities for digital health equity. npj Digit. Med. 9, 294 (2026). https://doi.org/10.1038/s41746-026-02483-y
Ключевые слова: федеративное обучение, путешествующая модель, болезнь Паркинсона, ИИ для медицинской визуализации, справедливость в здравоохранении