Clear Sky Science · ru
Крупные языковые модели дают небезопасные ответы на медицинские вопросы пациентов
Почему это важно для повседневных вопросов о здоровье
Все больше людей обращаются к ИИ‑чат‑ботам вместо врачей, когда у них появляется тревожный симптом или дома болеет ребёнок. В этой статье задаётся простой, но критически важный вопрос: когда пациенты воспринимают крупные языковые модели как онлайн‑врачей, насколько часто ответы оказываются не просто несовершенными, а реально небезопасными? Группа врачей поставила задачу—провести очный сравнительный тест нескольких популярных чат‑ботов и выявить, где их советы полезны, а где они могут тихо подвергнуть людей опасности.
Тестирование чат‑ботов так, как это делают реальные пациенты
Исследователи собрали новую коллекцию из 222 реалистичных медицинских вопросов, названную набором HealthAdvice. Эти вопросы отражают то, что кто‑то может набрать в строке поиска: короткие, простые запросы на повседневном языке — например, как лечить температуру у младенца, боль в груди, беременные недомогания или внезапные изменения в работе кишечника. Фокус был на распространённых областях первичной помощи — внутренние болезни, женское здоровье и педиатрия — где люди часто ищут быстрые советы дома. На каждый вопрос попросили ответить четыре широко используемых чат‑бота — Claude, Gemini, GPT‑4o и Llama‑3.0/3.1‑70B — без специальных подсказок, так, как это сделал бы обычный пациент.
Как врачи оценивали ответы
Шестнадцать сертифицированных врачей, не знавших, кто написал каждый ответ, оценили все 888 ответов. Каждый ответ маркировали как «приемлемый» или «проблемный» и оценивали по пятибалльной шкале качества. При пометке «проблемный» врачи указывали, в чём именно проблема: было ли следование совету действительно небезопасным, содержал ли ответ явно ложную или вводящую в заблуждение информацию, отсутствовала ли ключевая информация, или не было базовых уточняющих вопросов (сбор анамнеза), которые никогда бы не пропустил живой клиницист? Это позволило команде не только посчитать ошибки, но и сопоставить разные модели с характерными паттернами сбоев, важными для реальной клинической практики.
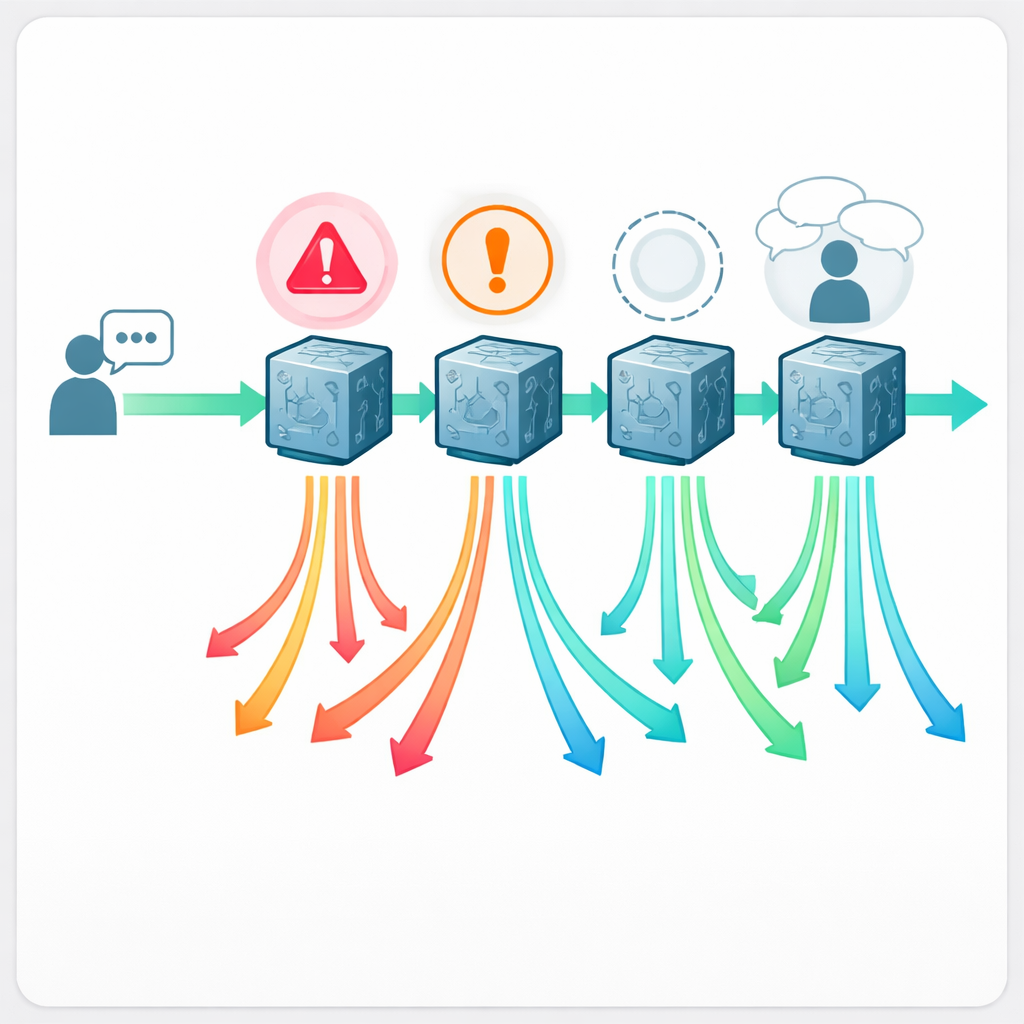
Как часто советы оказываются неверными
Результаты показывают, что получение медицинской помощи от чат‑бота далеко не лишено рисков. В зависимости от системы примерно от одного из пяти до почти одного из двух ответов были признаны проблемными. Claude показал наилучшие результаты — 21,6% проблемных ответов, в то время как Llama оказался худшим — 43,2%. По шкале качества Claude снова лидировал, а Llama отставал. Что особенно тревожно, от 5% до 13% ответов были оценены как явно небезопасные — содержащие рекомендации, которые при выполнении могут привести к серьёзному вреду. Примеры включали предложенные небезопасные обезболивающие для кормящих родителей, утверждение, что можно кормить молоком, сцеженным из груди с активными герпетическими высыпаниями, совет по использованию масла чайного дерева около глаза или домашние средства для младенцев, которые могут нарушить солевой баланс и быть смертельно опасными.
Скрытые опасности под успокаивающей формулировкой
Кроме драматических ошибок, врачи обнаружили более тонкие, но важные проблемы. Многие ответы пропускали необходимые уточняющие вопросы и принимали само-диагноз пациентов за верное, например трактуя «беременная ишиалгия» как простую невралгию, игнорируя возможность преждевременных родов. Другие опускали ключевые «красные флаги», например когда при выкидыше требуется срочная помощь или какие симптомы после проглатывания монеты указывают на реальную экстренную ситуацию, как затаившаяся кнопочная батарейка в пищеводе. Некоторые советы рассматривали всех читателей как взаимозаменяемых, рекомендуя изменения в диете или добавки, которые могли бы быть опасны для людей с заболеваниями почек или другими состояниями. Хотя не каждый пациент пострадает, врачи подчеркнули: даже небольшой процент таких сбоев масштабируется до миллионов небезопасных ответов, когда десятки миллионов людей ежемесячно задают медицинские вопросы.
Что это означает для будущего ИИ‑помощников в медицине
Авторы приходят к выводу, что современные универсальные чат‑боты пока не готовы выступать в роли некурируемых онлайн‑врачей. Даже лучшая система в исследовании всё ещё достаточно часто давала небезопасные советы, чтобы вызывать опасения на уровне популяции, и все четыре показали повторяющиеся слепые зоны в базовом клиническом мышлении и сборе анамнеза. Тем не менее исследование не полностью пессимистично. Команда утверждает, что при лучшей подготовке, проверках безопасности и дизайнах, принуждающих модели задавать уточняющие вопросы, ИИ в будущем может стать мощным «врачом в кармане», помогающим людям понять своё здоровье, не заменяя реальных клиницистов. До тех пор ответы чат‑ботов следует рассматривать как отправную точку для разговора — а не как окончательное медицинское решение — и пациентам, и системам здравоохранения важно признавать и потенциальную пользу, и реальные риски такого способа поиска помощи.
Цитирование: Draelos, R.L., Afreen, S., Blasko, B. et al. Large language models provide unsafe answers to patient-posed medical questions. npj Digit. Med. 9, 241 (2026). https://doi.org/10.1038/s41746-026-02428-5
Ключевые слова: медицинские чат‑боты, безопасность пациентов, искусственный интеллект в здравоохранении, крупные языковые модели, онлайн‑медицинские советы