Clear Sky Science · ru
Модели машинного обучения для прогнозирования взаимодействий между лекарствами: от вычислительных открытий до клинического применения
Почему комбинация препаратов может быть рискованной
Современная медицина часто предполагает одновременный прием нескольких лекарств — при раке, заболеваниях сердца, инфекциях или просто для контроля множества состояний, сопутствующих старению. Но когда препараты встречаются в организме, они могут изменять эффекты друг друга, иногда снижая эффективность лечения или делая его опасным. В этом обзоре рассматривается, как искусственный интеллект, особенно современные методы машинного обучения, применяется для прогнозирования таких взаимодействий заранее, чтобы врачи могли выбирать более безопасные сочетания и адаптировать терапию под конкретного пациента.
От метода проб и ошибок к основанной на данных безопасности
Традиционно опасные сочетания лекарств выявлялись трудным путем — в поздних клинических испытаниях или уже после выхода препарата на рынок, когда пострадали пациенты. Лабораторные тесты на клетках, животных и добровольцах остаются золотым стандартом, но они медленны, дороги и неприменимы ко всем многочисленным потенциалным парам препаратов. Авторы утверждают, что вычислительное прогнозирование предлагает выход из этого узкого места. Обучаясь на огромных цифровых коллекциях данных о лекарствах — таких как химические структуры, мишени в организме, известные побочные эффекты и реальные сообщения о неблагоприятных реакциях — системы машинного обучения могут заранее помечать рискованные пары задолго до того, как они достигнут большого числа пациентов.
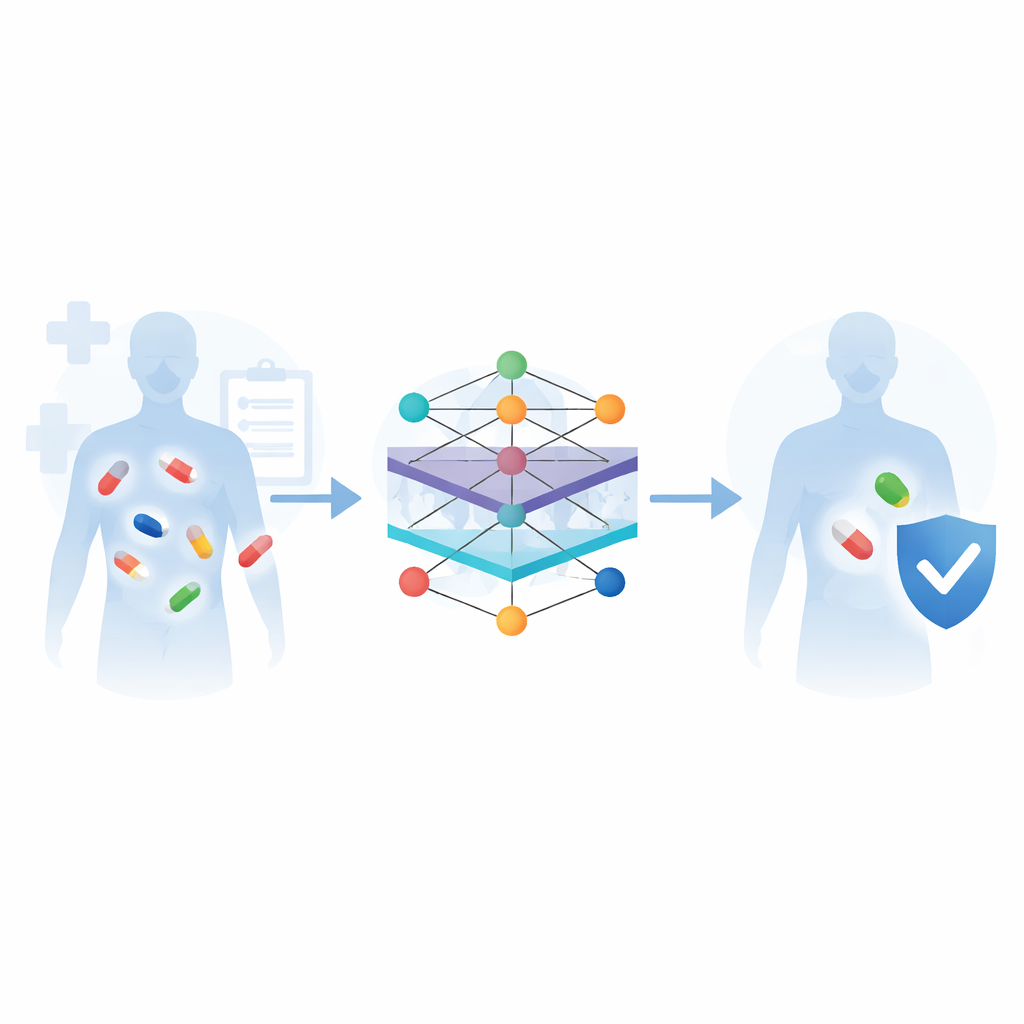
Как машины учатся на разных типах данных о лекарствах
Обзор описывает типичный рабочий процесс для таких систем прогнозирования. Сначала информация собирается из основных биомедицинских баз данных: химических библиотек, описывающих внешний вид каждой молекулы; карт путей метаболизма, показывающих, как препараты обрабатываются в организме; и курируемых списков известных взаимодействий и побочных эффектов. Затем алгоритмы преобразуют эти сырые данные в числовые представления, понятные компьютеру — например, путем оценки сходства двух препаратов или представления каждого препарата как узла в сети, связанного с его мишенями, путями и предыдущими реакциями. Различные модели машинного обучения обучаются распознавать, какие пары препаратов склонны вызывать проблемы, а их производительность проверяется на эталонных наборах данных с помощью стандартных показателей точности.
Разные семейства алгоритмов решают задачу по‑своему
Поскольку взаимодействия между препаратами сложны, ни один тип модели не является оптимальным для всех случаев. Одни подходы опираются на традиционные классификаторы с вручную созданными признаками, другие учатся прямо на структуре молекул или на сети связей между препаратами и биологическими сущностями. Особенно успешны графовые и глубокие методы: они рассматривают препараты и их взаимосвязи как сеть, позволяя алгоритму «размышлять» над цепочками связей, невидимых для более простых моделей. Другие стратегии передают информацию между смежными задачами, например одновременно прогнозируют, взаимодействуют ли два препарата и какой эффект они производят, что полезно при дефиците данных. Статья также выделяет новые направления, такие как большие языковые модели, читающие научные тексты и клинические заметки, и генеративные модели, изучающие возможные паттерны взаимодействий в очень больших разреженных наборах данных.
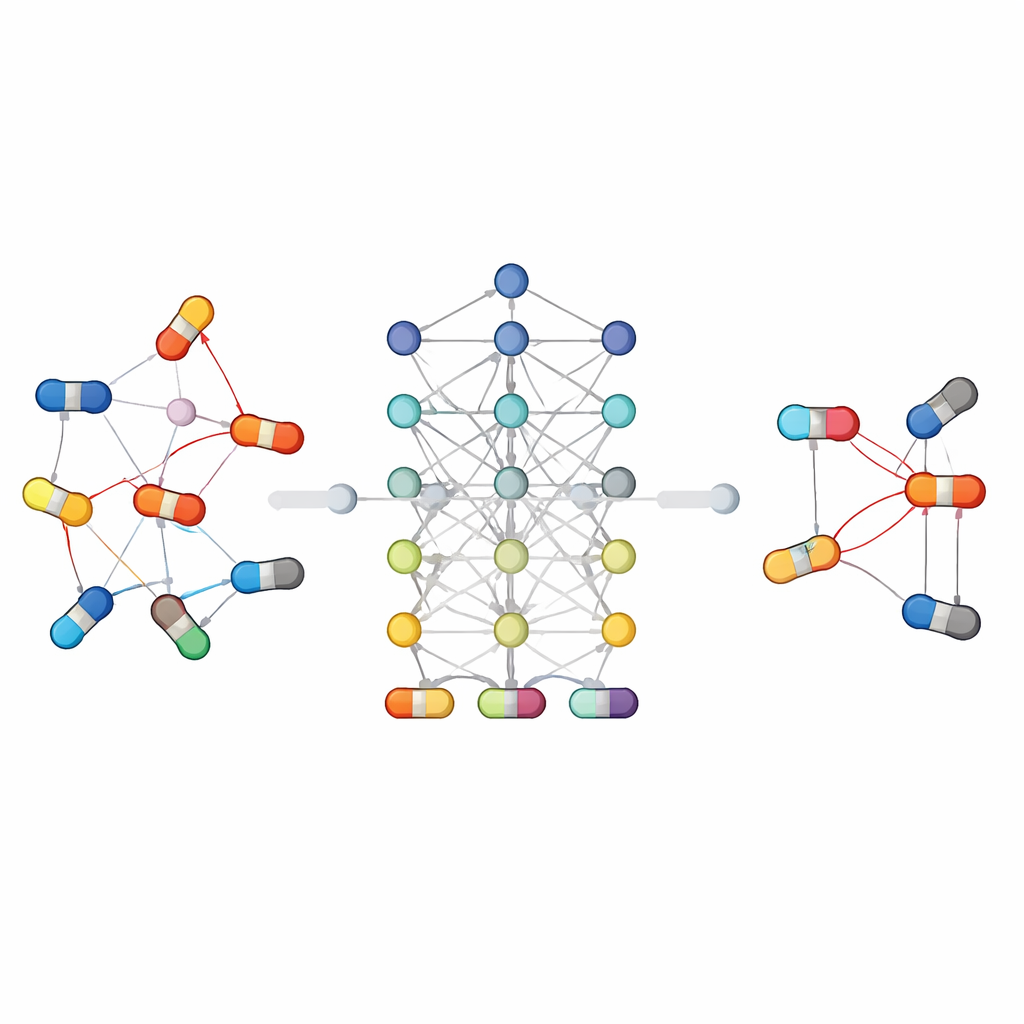
Связь компьютерных прогнозов с реальными пациентами
Помимо методов, статья подчеркивает, как эти инструменты могут поддерживать реальную клиническую практику. Авторы обсуждают, как модели, обученные на курируемых базах данных и клинических записях, могут предупреждать врачей о опасных сочетаниях у постели пациента, помогать разрабатывать более безопасные схемы многопрепаратной терапии в онкологии, кардиологии и лечении инфекций, а также приоритизировать, какие прогнозируемые взаимодействия следует проверить в лаборатории. Они также приводят классические клинические примеры — например, как антибиотики изменяют уровни статинов, как обезболивающие могут блокировать эффекты друг друга или как фруктовые соки неожиданно повышают концентрацию препаратов — чтобы показать множество путей возникновения взаимодействий. Системы машинного обучения, улавливающие эти закономерности, могут выступать в роли ранних предупреждений, особенно у пожилых пациентов, принимающих множество лекарств.
Проблемы на пути к надежному ИИ в медицине
Несмотря на впечатляющую точность на тестовых наборах, авторы подчеркивают, что текущие модели все еще сталкиваются с важными препятствиями, прежде чем их можно будет широко доверять в клинике. Многие из них — «черные ящики», которые дают мало понимания, почему конкретная пара признана рискованной, что затрудняет врачам оценку или объяснение рекомендации. Модели могут ошибаться при шумных или несбалансированных данных — например, когда вредные взаимодействия редки по сравнению с безопасными парами. Интеграция данных из химии, генетики, электронных медицинских карт и опубликованной литературы технически сложна, а регуляторные рамки требуют убедительных доказательств, прежде чем такие инструменты смогут влиять на назначение лекарств. Авторы считают, что будущее должно быть направлено на более интерпретируемые модели, лучшее управление смещенными и неполными данными, а также на системы, которые могут непрерывно учиться на новом клиническом опыте при соблюдении правил конфиденциальности и безопасности.
Что это означает для повседневного лечения
Проще говоря, обзор показывает, что искусственный интеллект становится мощным союзником в обеспечении безопасности комбинированной терапии. Просеивая горы цифровых данных, далеко превосходящие возможности любого отдельного эксперта, модели машинного обучения могут выявлять опасные сочетания, предлагать более безопасные альтернативы и поддерживать более персонализированные назначения. Эти инструменты не заменят клиническое суждение или тщательное лабораторное тестирование, но помогут гарантировать, что растущая сложность современной терапии не приводит к риску для пациентов.
Цитирование: Lu, Y., Chen, J., Fan, N. et al. Machine learning models for drug-drug interaction prediction from computational discovery to clinical application. npj Digit. Med. 9, 198 (2026). https://doi.org/10.1038/s41746-026-02400-3
Ключевые слова: взаимодействия лекарств, машинное обучение в медицине, графовые нейронные сети, клиническая фармакология, безопасность искусственного интеллекта