Clear Sky Science · ru
Крупные языковые модели повышают переносимость предсказаний на основе электронных медицинских карт между странами и кодировочными системами
Почему более разумный обмен медицинскими данными важен
Больницы и клиники по всему миру располагают настоящей сокровищницей информации: электронными медицинскими записями, которые фиксируют диагнозы, лечения и исходы пациентов на протяжении многих лет. В теории эти данные могли бы помочь врачам заранее выявлять людей с высоким риском серьёзных заболеваний, задолго до проявления очевидных симптомов. На практике современные компьютерные модели плохо «путешествуют» из одной страны или системы здравоохранения в другую, потому что в каждом месте медицинские данные записывают по‑разному. В этой работе представлено новое решение, названное GRASP, которое использует достижения в области искусственного интеллекта, чтобы преодолеть эти разрывы и позволить модели, натренированной в одной системе, надёжно работать в других.
Разные больницы — разные «языки»
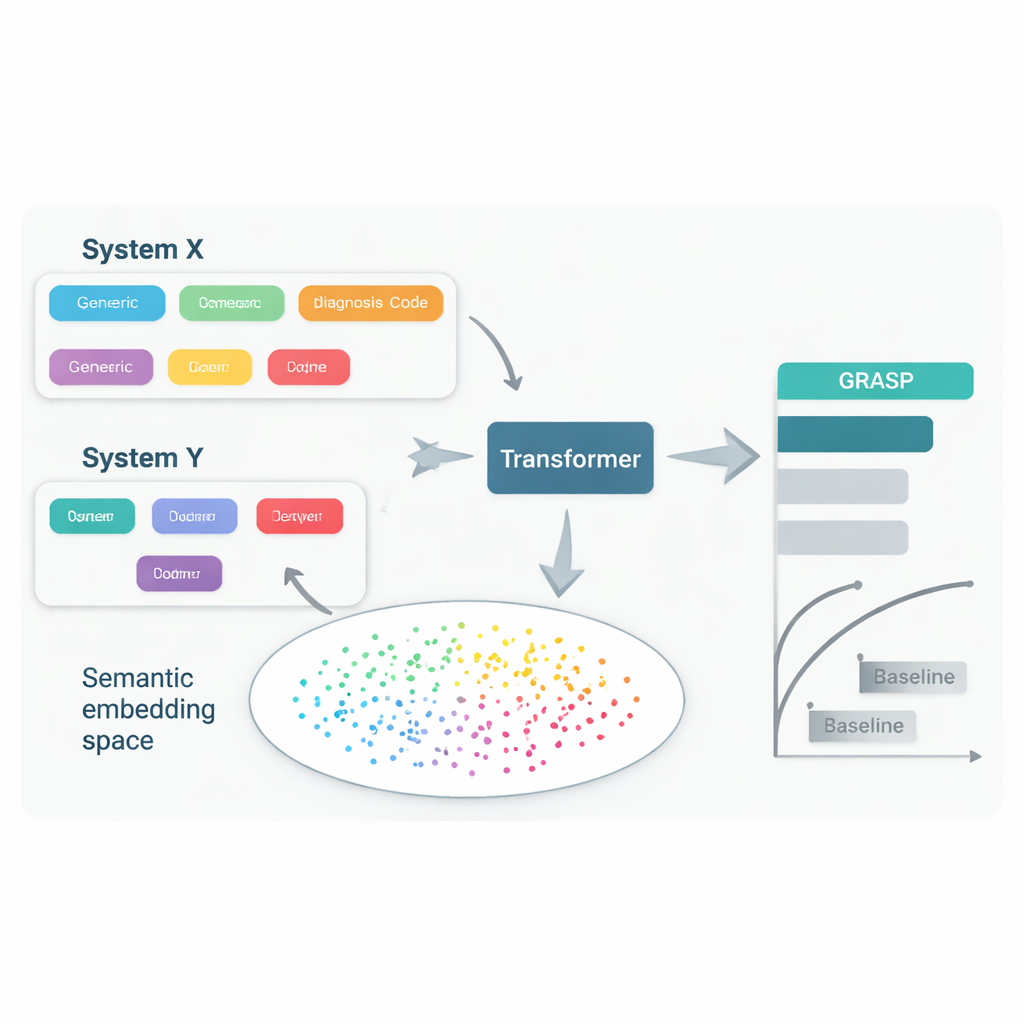
Даже при лечении одного и того же заболевания врачи часто пользуются разными системами кодирования и локальными привычками при внесении записей в медицинскую карту. В одной больнице «высокий уровень сахара в крови» может храниться под одним кодом, в другой — под кодом «гипергликемия», а в третьей используется совсем иная система. Попытки привести всех к единому международному стандарту полезны, но идут медленно, дорого и всё равно оставляют важные различия. В результате модель, предсказывающая болезни по записям в одной стране, может терять точность при применении в другой, что ограничивает круг тех, кто может извлечь пользу из таких инструментов.
Позволяя ИИ читать смысл, а не только коды
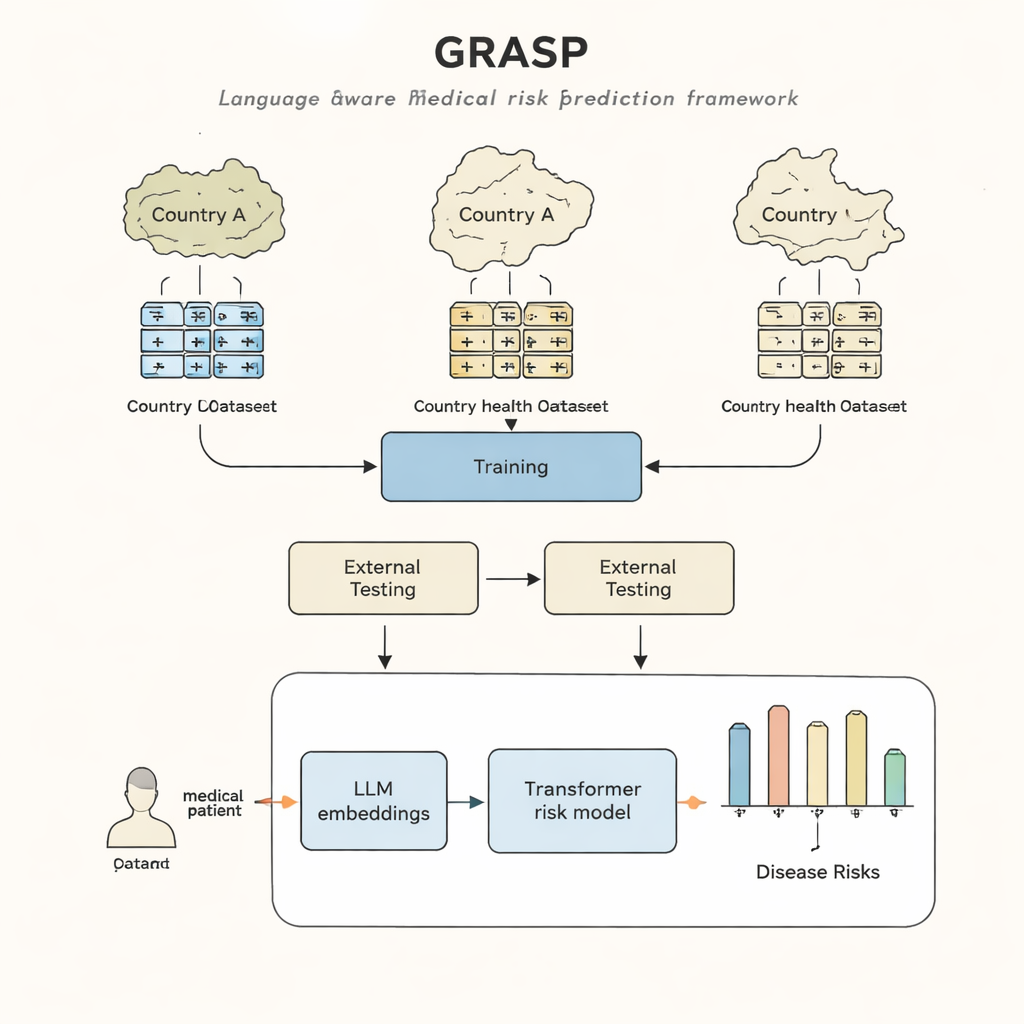
Подход GRASP исходит из простой идеи: вместо того чтобы рассматривать каждый медицинский код как бессмысленный идентификатор, позволить крупной языковой модели прочитать человекочитаемое описание, например «острая инфекция верхних дыхательных путей», и преобразовать этот смысл в числовое «встраивание» (embedding). Такие встраивания располагают родственные понятия близко друг к другу в общем пространстве, даже если они исходят из разных систем кодирования или стран. GRASP заранее вычисляет встраивания для миллионов стандартных медицинских терминов и сохраняет их в таблице поиска. Медицинская история пациента затем представляется как последовательность этих насыщенных векторов, которые подаются в трансформер — тип нейронной сети, хорошо подходящий для обработки набора разнообразных входов — чтобы оценить риск 21 крупного заболевания, а также общий риск смерти.
Тестирование в разных странах и системах записей
Исследователи обучили GRASP на данных почти 400 000 участников UK Biobank, затем протестировали его без дообучения в двух очень разных условиях: в проекте FinnGen в Финляндии и в крупной сети больниц в Нью‑Йорке. GRASP сопоставимо или лучше выступал по сравнению с сильными альтернативами, включая популярный метод XGBoost и похожий трансформер, который не использовал языковые встраивания. В Финляндии GRASP показал особенно хорошие результаты, продемонстрировав явные улучшения для таких состояний, как астма, хроническая болезнь почек и сердечная недостаточность. Примечательно, что даже когда данные американских больниц оставляли в другой системе кодирования вместо перевода в общий стандарт, GRASP по‑прежнему давал лучшие прогнозы, чем только демография, поскольку мог согласовывать коды, опираясь исключительно на понимание текстовых описаний.
Больше за счёт меньшего объёма данных
Ещё одним преимуществом GRASP является эффективность. Поскольку языковая модель уже усвоила, что многие медицинские концепции взаимосвязаны, сети для предсказания не нужно заново открывать эти связи с нуля. Когда авторы обучали GRASP на гораздо меньших поднаборах данных UK Biobank — вплоть до всего 10 000 человек — он всё равно превосходил конкурирующие модели, обученные на тех же ограниченных выборках, как в Великобритании, так и при переносе за рубеж. Оценки риска по GRASP также более тесно коррелировали с наследственным генетическим риском по нескольким заболеваниям, что указывает на то, что модель улавливает более глубокие аспекты восприимчивости к болезням, а не просто запоминает шаблоны в одном наборе данных.
Что это значит для будущей медицины
Для неспециалистов главный вывод таков: GRASP показывает, как современные языковые методы ИИ могут помочь разным системам здравоохранения «говорить на одном языке» без принудительного перехода на жёсткую единообразную схему кодирования. Читая смысл медицинских терминов, GRASP способен делать прогнозы риска заболеваний, которые лучше обобщаются между странами и форматами записей, и при этом требовать меньше примеров пациентов. Хотя метод ещё нуждается в тщательной проверке, перекалибровке и оценке справедливости перед применением в повседневной практике, он указывает путь к будущему, в котором мощные инструменты оценки риска, созданные в одном месте, можно безопасно и эффективно разделять с больницами и клиниками по всему миру.
Цитирование: Kirchler, M., Ferro, M., Lorenzini, V. et al. Large language models improve transferability of electronic health record-based predictions across countries and coding systems. npj Digit. Med. 9, 177 (2026). https://doi.org/10.1038/s41746-026-02363-5
Ключевые слова: электронные медицинские записи, прогнозирование риска заболеваний, крупные языковые модели, обмен медицинскими данными, ИИ в здравоохранении