Clear Sky Science · ru
IMFLKD: механизм вознаграждения для децентрализованного федеративного обучения на основе дистилляции знаний
Почему совместный обмен может быть безопасным и справедливым
Современный искусственный интеллект питается данными, однако большая часть нашей информации хранится на личных телефонах, серверах больниц или в облаках компаний и не может быть просто скопирована и передана. Федеративное обучение позволяет многим устройствам обучать общий модель, не раскрывая свои исходные данные, но существующие системы всё ещё подвержены утечкам приватности, централизованным точкам отказа и несправедливому распределению вознаграждений для наиболее вкладывающихся участников. В этой статье представлен новый фреймворк IMFLKD, который объединяет три мощные идеи — блокчейн, дистилляцию знаний и оценку репутации — чтобы сделать коллективное обучение более приватным, более устойчивым и более справедливым в долгосрочной перспективе.
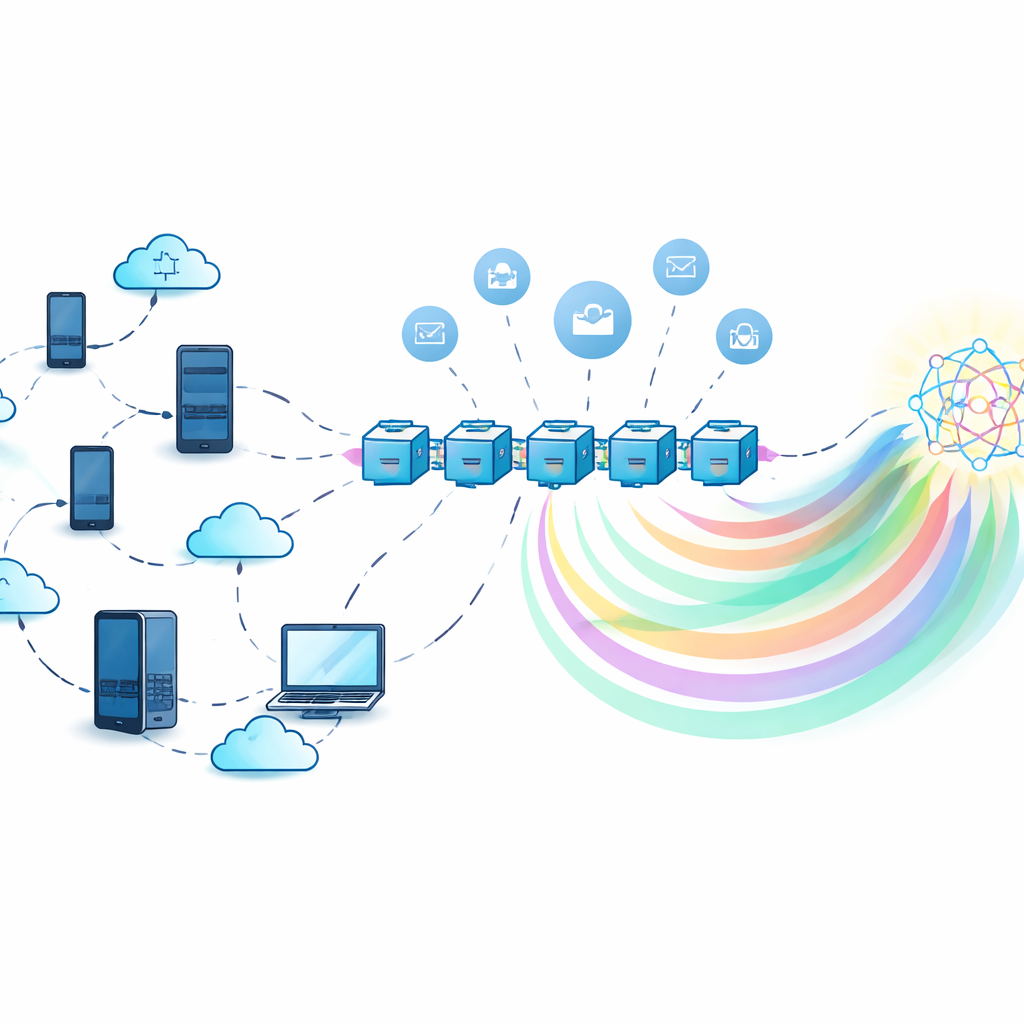
Обучение вместе без обмена секретами
В классическом федеративном обучении центральный сервер собирает обновления моделей от многих участников и объединяет их. Это предотвращает передачу сырых данных, но сам сервер становится привлекательной целью: при его сбое система останавливается, а если сервер ненадёжен, он может неправомерно использовать или раскрыть информацию, скрытую в обновлениях модели. Авторы вместо этого используют децентрализованный блокчейн-реестр для координации обучения. Каждый участник обучает локальную модель на своих данных и взаимодействует со смарт-контрактами в блокчейне, которые фиксируют вклады, агрегируют информацию и распределяют вознаграждения — всё это происходит без опоры на единую центральную власть.
Обмен знаниями, а не тяжёлыми моделями
Чтобы снизить затраты на коммуникацию и дополнительно защитить приватность, фреймворк опирается на дистилляцию знаний. Вместо передачи полных параметров модели каждый участник отправляет только «мягкие метки» — предсказанные моделью вероятности для набора общих входов — которые гораздо легче и раскрывают меньше о данных отдельного участника. Поскольку реальный общий датасет может отсутствовать, система использует генеративную модель — условный вариационный автоэнкодер — для создания синтетического «псевдо-публичного» набора данных, который в целом повторяет распределение меток, не раскрывая исходные записи. Участники обучаются на собственных данных, делают предсказания на этом синтетическом наборе и затем уточняют свои модели с помощью агрегированного сигнала, полученного из объединённых знаний всех участников.
Измерение реального вклада
Ключевая задача в любой совместной системе — решить, кто заслуживает признания. IMFLKD решает это с помощью двухэтапного метода оценки вклада на основе агрегации меток. Сначала лёгкий байесовский алгоритм анализирует предсказания всех участников и выводит как наиболее вероятную истинную метку для каждого образца, так и оценку качества каждой модели, обновляя эти оценки по мере поступления новых заданий. Такой подход работает в режиме онлайн, без хранения прошлых данных, и справляется с шумными или злонамеренными участниками, понижая вес моделей, которые часто расходятся с формирующимся консенсусом. Эксперименты показывают, что эта агрегация меток улучшает точность примерно на 10 процентов по сравнению с простым большинственным голосованием, оставаясь при этом достаточно быстрой для крупномасштабных сред с ограниченными ресурсами.
Преобразование качества в вознаграждения и репутацию
Когда качество вклада становится известным, IMFLKD применяет схему стимулов, называемую взвешенной «peer truth serum», чтобы превратить его в вознаграждения. Участников сравнивают с консенсусом сверстников, взвешенным по качеству: те, чьи предсказания совпадают с высококачественными сверстниками, получают больше, а те, кто отклоняется или часто не согласен, наказываются. Это делает честную отчётность наиболее выгодной стратегией в долгосрочной перспективе, даже при попытках сговора. Кроме того, система формирует многомерный рейтинг репутации для каждого участника, объединяя качество данных, уровень активности и поведенческую стабильность, при этом более старое поведение корректируется фактором временного затухания. Репутация затем возвращается в последующие раунды, влияя на вес предсказаний участника и на его отбор для будущих заданий.
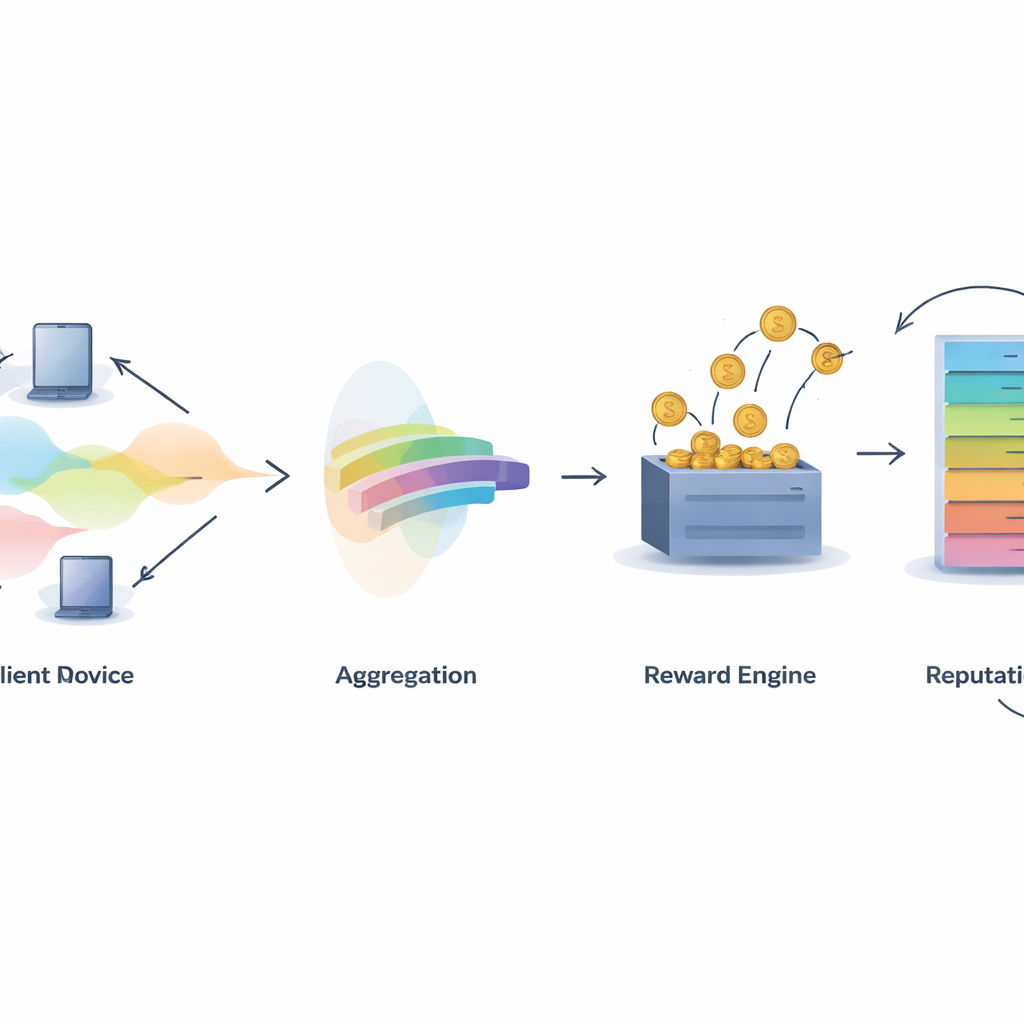
Построение доверия в коллективном разуме
В целом фреймворк IMFLKD демонстрирует, что можно координировать обучение между множеством независимых устройств эффективно, с учётом приватности и устойчиво к фрилодерам и атакующим. Сочетая генерацию синтетических данных, строгую оценку вклада, теоретически обоснованные схемы вознаграждений и динамическое отслеживание репутации на блокчейне, система стимулирует участников действовать честно и последовательно в течение многих раундов обучения. Для непрофессионала главный вывод таков: мы можем использовать коллективную силу распределённых данных — например, медицинских записей, показаний датчиков или личных устройств — не передавая всё одной компании или серверу, при этом обеспечивая, чтобы наибольшую выгоду получали те, кто предоставляет наиболее полезную информацию.
Цитирование: Ying, X., Yan, K., Gao, X. et al. IMFLKD: an incentive mechanism for decentralized federated learning based on knowledge distillation. Sci Rep 16, 10567 (2026). https://doi.org/10.1038/s41598-026-46234-1
Ключевые слова: федеративное обучение, блокчейн, дистилляция знаний, механизмы поощрения, системы репутации