Clear Sky Science · ru
Гибридное эволюционно‑градиентное обучение улучшает долгосрочное прогнозирование временных рядов
Почему важны более точные долгосрочные прогнозы
От потребления электроэнергии и дорожного потока до валютных курсов и местной погоды — наша жизнь зависит от систем, которые меняются во времени. Точное прогнозирование этих закономерностей на дни или недели вперед помогает экономить энергию, снижать заторы и повышать устойчивость бизнеса. Но чем дальше мы заглядываем в будущее, тем сложнее современным инструментам искусственного интеллекта справляться со смещениями условий, шумными измерениями и ограниченными вычислительными ресурсами. В этой работе представлен новый подход к обучению моделей прогнозирования, который помогает им оставаться точными и стабильными даже когда окружающий мир постоянно меняется.
Учиться у многих моделей вместо одной
Большинство современных предикторов временных рядов опираются на одну глубокую нейронную сеть, обучаемую методом градиентного спуска — стандартным способом постепенной настройки параметров для уменьшения ошибки. Это хорошо работает при стабильном поведении данных, но даёт сбои при дрейфе условий, шумных измерениях или жёстких ограничениях по времени обучения. Авторы вместо разработки новой архитектуры предлагают рамочный метод обучения Evolutionary‑Guided Module Fusion with Gradient Refinement (EGMF‑GR), который можно «надеть» поверх существующих моделей. Ключевая идея — поддерживать небольшую «популяцию» моделей с одинаковой структурой, но разными начальными параметрами. В процессе обучения эти модели исследуют разные способы аппроксимации данных, а лучшая в данный момент служит ориентиром для улучшения остальных.
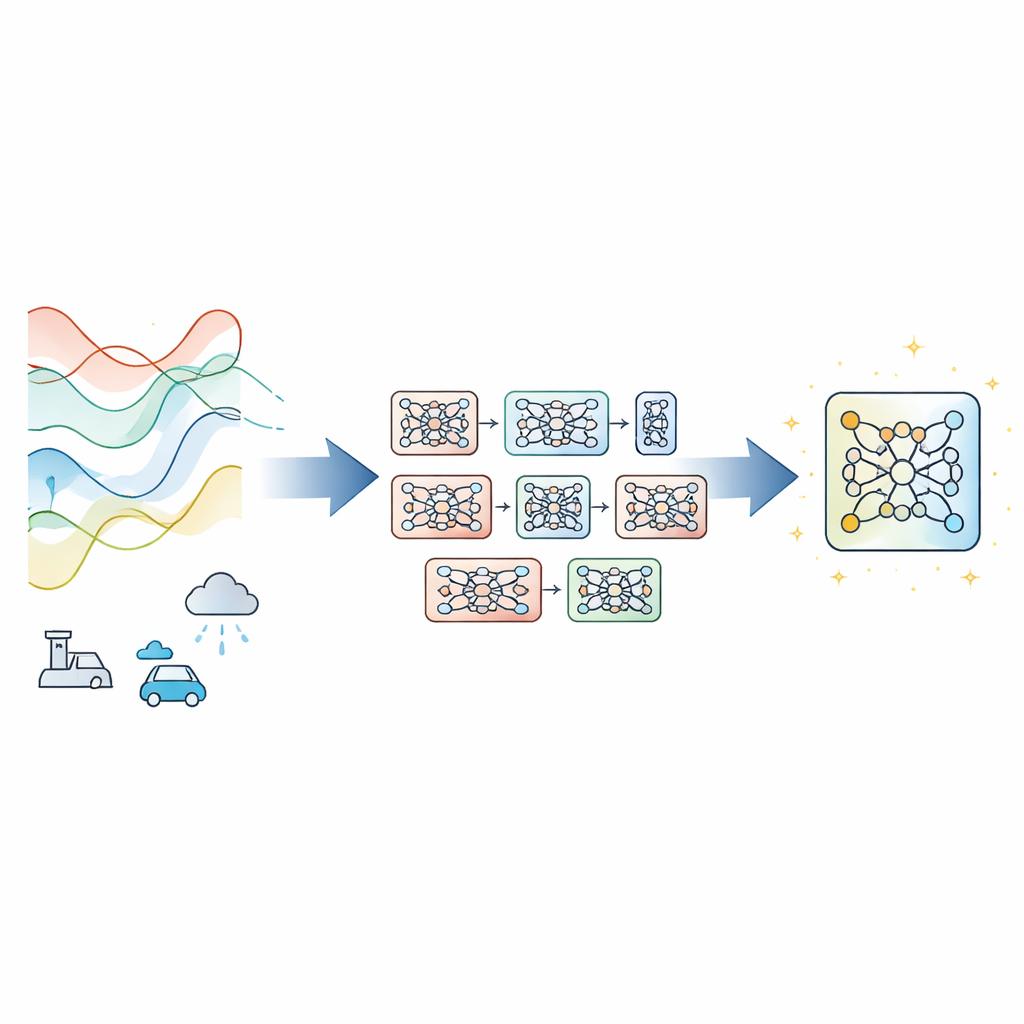
Заем хороших частей, сохраняя полезное разнообразие
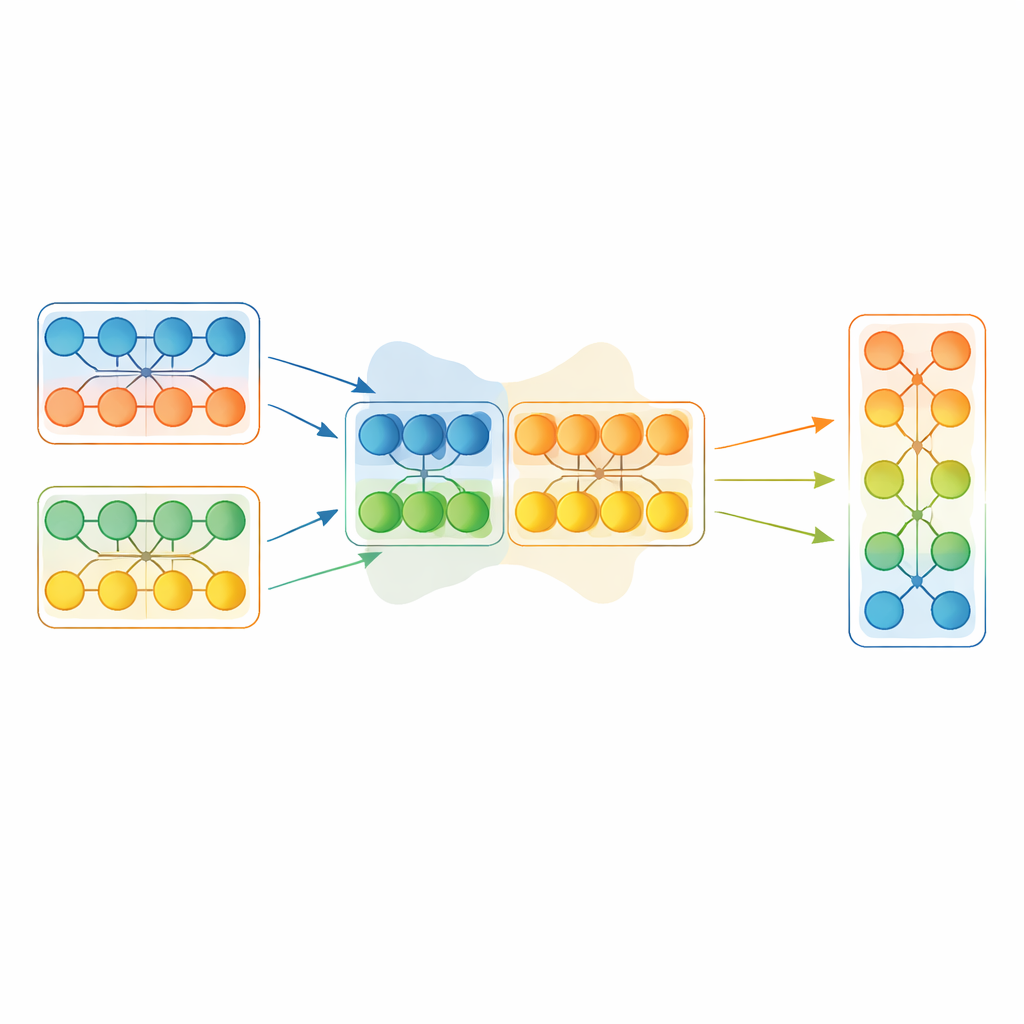
Вместо слепого копирования целой победившей модели EGMF‑GR действует на уровне модулей — повторяющихся строительных блоков сети, например стеков слоёв. Для каждой модели в популяции фреймворк выравнивает соответствующие модули с модулями текущей лучшей модели и сравнивает их внутренние сигналы при обработке одной и той же мини‑партии входных данных. Используются несколько простых мер различия, учитывающих как форму активности, так и её амплитуду. Эти модульные расхождения обобщаются, и обновлению подвергаются только те модули, поведение которых выглядит как сильные выбросы относительно сверстников. В таком случае отстающий модуль подтягивают к соответствующему модулю лучшей модели с помощью взвешенного смешения параметров и небольшого случайного возмущения для сохранения разнообразия.
Позволить градиентам навести порядок после крупных перестановок
Смешивание частей разных сетей может приводить к резким изменениям. Чтобы не дестабилизировать обучение, каждая модель после слияния проходит короткую традиционную фазу градиентного спуска на тренировочных данных. Этот этап уточнения позволяет сети плавно адаптироваться к новой внутренней конфигурации, сохранив преимущества заимствованного знания. Общая процедура циклична: выбрать текущую лучшую модель по отложенному фрагменту данных, избирательно перенести модули этого лидера в остальные модели популяции и кратко дообучить всех градиентами. Важно, что метод также синхронизирует внутренние служебные состояния, такие как скользящие средние, используемые некоторыми слоями — их часто игнорируют в более простых схемах слияния моделей, хотя они сильно влияют на стабильность.
Доказательства преимуществ на множестве реальных сигналов
Для проверки фреймворка авторы применили EGMF‑GR к нескольким популярным бэбонам для прогнозирования, включая модели в духе Transformer и недавнюю сверточную архитектуру, не меняя их базовой структуры. Оценка проводилась на восьми публичных бенчмарках, охватывающих потребление энергии, потоки трафика, валютные курсы и погоду, а также на разных горизонтах прогнозирования — от нескольких часов до нескольких дней. При строго сопоставимом бюджете дорогостоящих обратных проходов гибридное обучение последовательно снижало ошибки прогнозов и сглаживало поведение обучения для большинства сочетаний моделей и наборов данных, особенно в высокоразмерных или шумных условиях. Команда также сравнила свой подход с обычными приёмами для одной модели, такими как экспоненциальные скользящие средние и стохастическое усреднение весов, и обнаружила, что популяционное слияние модулей даёт дополнительные преимущества сверх простого сглаживания весов.
Оставаться надёжным, когда условия ухудшаются
Реальные системы редко ведут себя как чистые учебные примеры, поэтому авторы проверяли робастность в более жёстких сценариях: искусственно искажённые входы, пропуски фрагментов данных и периоды, когда базовая динамика внезапно меняется. EGMF‑GR однозначно помогал при шумных или частично отсутствующих входных данных, что говорит о том, что заимствование стабильного поведения модулей у текущей лучшей модели может компенсировать локальные сбои. При резких сменах режима преимущество было меньше, что указывает на то, что слишком сильное выравнивание иногда замедляет адаптацию к новым паттернам. Это открывает путь для будущих улучшений, где сила слияния будет ослабляться при высокой нестабильности среды.
Что это значит для повседневных инструментов прогнозирования
Проще говоря, исследование показывает: обучение множества кооперативных версий одной и той же модели прогнозирования и разрешение им обмениваться лишь действительно выдающимися частями может сделать долгосрочные предсказания точнее и стабильнее без переработки самих моделей. EGMF‑GR работает как дисциплинированная командная игра: участники время от времени перенимают сильные приёмы друг друга, а затем немного практикуются самостоятельно, чтобы лучше соответствовать текущей «игре». Для практиков это даёт подключаемую стратегию обучения, которая может усилить существующие системы прогнозирования в финансах, энергетике, транспорте и климатических приложениях, особенно когда данные шумные, а вычислительный бюджет ограничен.
Цитирование: Zhao, L., Chen, Z., Wu, N. et al. Hybrid evolutionary-gradient training improves long-term time series forecasting. Sci Rep 16, 10697 (2026). https://doi.org/10.1038/s41598-026-45017-y
Ключевые слова: прогнозирование временных рядов, эволюционное обучение, нейронные сети, слияние моделей, смещение распределения