Clear Sky Science · ru
Проектирование LNA‑блокеров на данных для эффективного удаления загрязнений в библиотеках Ribo‑Seq
Почему важно очищать данные секвенирования
Современная биология часто опирается на чтение миллионов коротких фрагментов РНК, чтобы понять, как клетки синтезируют белки. Но эти мощные измерения, особенно метод, называемый профилированием рибосом (Ribo‑Seq), могут быть захламлены нерелевантными фрагментами РНК, которые расходуют ресурс секвенирования и деньги. В этом исследовании описан простой, основанный на данных способ проектирования специализированных молекулярных «блокеров», которые селективно удаляют нежелательные фрагменты, почти вдвое увеличивая полезную информацию, получаемую в одном и том же эксперименте.
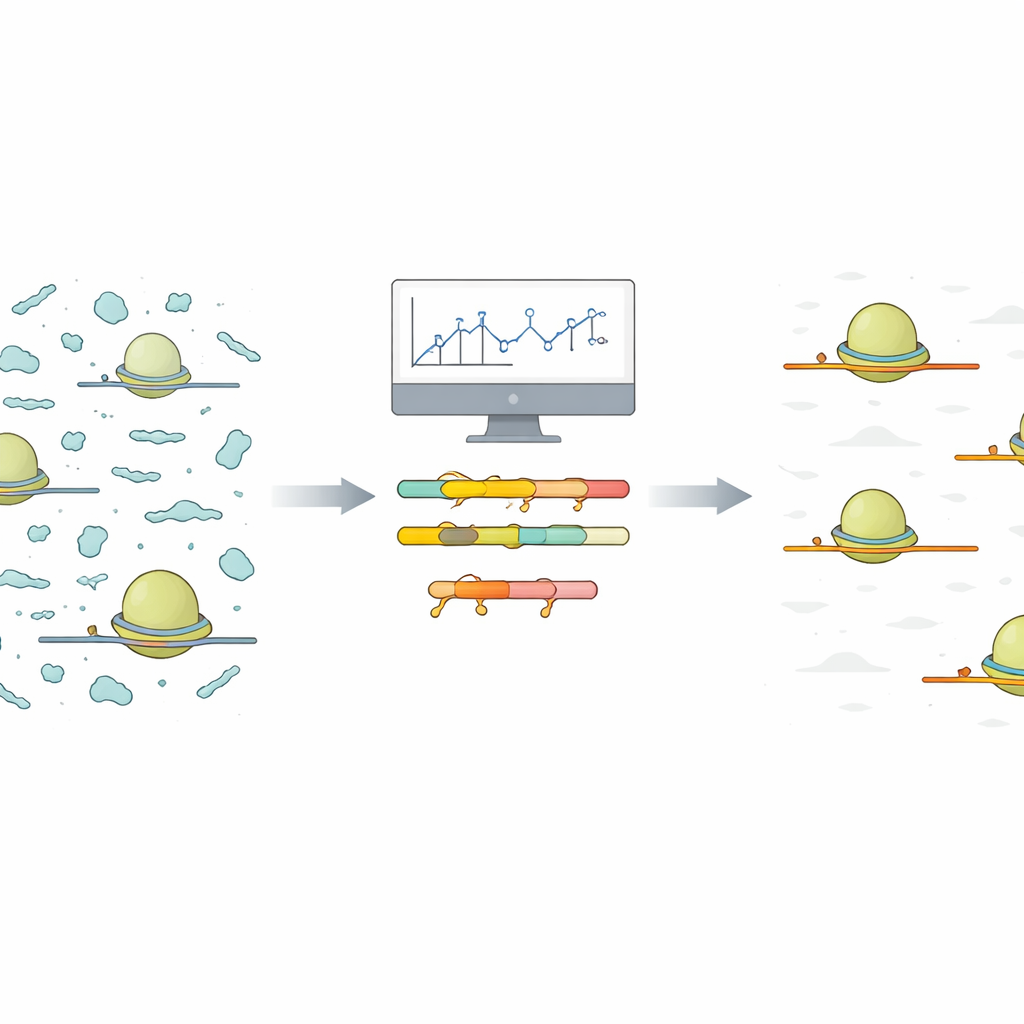
Проблема шумных снимков рибосом
Ribo‑Seq фиксирует покадровую картину того, какие сообщения в клетке в данный момент переводятся в белки. Для этого ученые выделяют рибосомы вместе с короткими участками мРНК, которые они защищают. Всё остальное расщепляют, а защищенные фрагменты секвенируют и сопоставляют с геномом. На практике же через этот процесс просачивается много других коротких некодирующих РНК. Поскольку эти фрагменты‑загрязнения многочисленны и сильно варьируют, они поглощают значительную долю прочтений секвенирования, оставляя меньше данных для настоящих сигналов кодирующих белки молекул, представляющих интерес для исследователей.
Почему существующие методы очистки недостаточны
Стандартные стратегии пытаются удалить обильные рибосомные и другие некодирующие РНК с помощью заранее разработанных захватных зондов или ферментов. Эти методы хорошо работают, когда целевые РНК цельные и предсказуемые, но в Ribo‑Seq РНК целенаправленно разрезают на множество фрагментов разной длины. Такое фрагментирование перемешивает сайты, на которые нацелены фиксированные наборы зондов, что значительно снижает эффективность истощения. Кроме того, точный состав загрязнений зависит от вида, условий роста и даже от используемого нуклеазы. Существующие рабочие протоколы очистки также часто включают множественные инкубации и этапы очистки, что занимает время и может приводить к потере образца или внесению смещения.
Индивидуальные блокеры, спроектированные по реальным данным
Авторы предлагают упрощенный подход, который начинается с небольшого и недорогого пилотного секвенирования при тех же условиях, что и планируемый основной эксперимент. Они предоставляют R‑скрипт, который берет выровненные прочтения из пилотного прогона и автоматически группирует похожие фрагменты‑загрязнения по последовательности. Для каждой группы скрипт выводит кратчайшую общую последовательность, присутствующую в фрагментах. Эти короткие общие участки являются идеальными целевыми сайтами для специализированных молекул — олигонуклеотидов с замкнутыми нуклеиновыми кислотами (LNA). LNA — короткие цепочки с химической модификацией, которая делает их очень плотно связывающимися с соответствующей РНК. Скрипт также генерирует наглядные тепловые карты и сводные графики, помогая пользователям увидеть, какие загрязнения доминируют и сколько LNA‑таргетов потребуется для существенной очистки.
Одноступенчатая очистка во время амплификации
Вместо физического удаления загрязнений из образца метод использует LNA‑олигонуклеотиды в качестве блокеров во время этапа амплификации ДНК, который формирует секвенирующую библиотеку. Авторы тестировали добавление этих блокеров либо во время начальной обратной транскрипции, либо в более поздней PCR‑амплификации. Они обнаружили, что добавление LNA во время амплификации было более эффективным и требовало меньших концентраций, снижая содержание тестового загрязнения более чем в тысячу раз и работая независимо от ориентации цепи. Практические рекомендации по проектированию включают чередование стандартных ДНК‑ и LNA‑строительных блоков, минимальную длину 14 нуклеотидов для растения Arabidopsis и модификацию хвостового конца, чтобы сам блокер не мог случайно удлиняться.
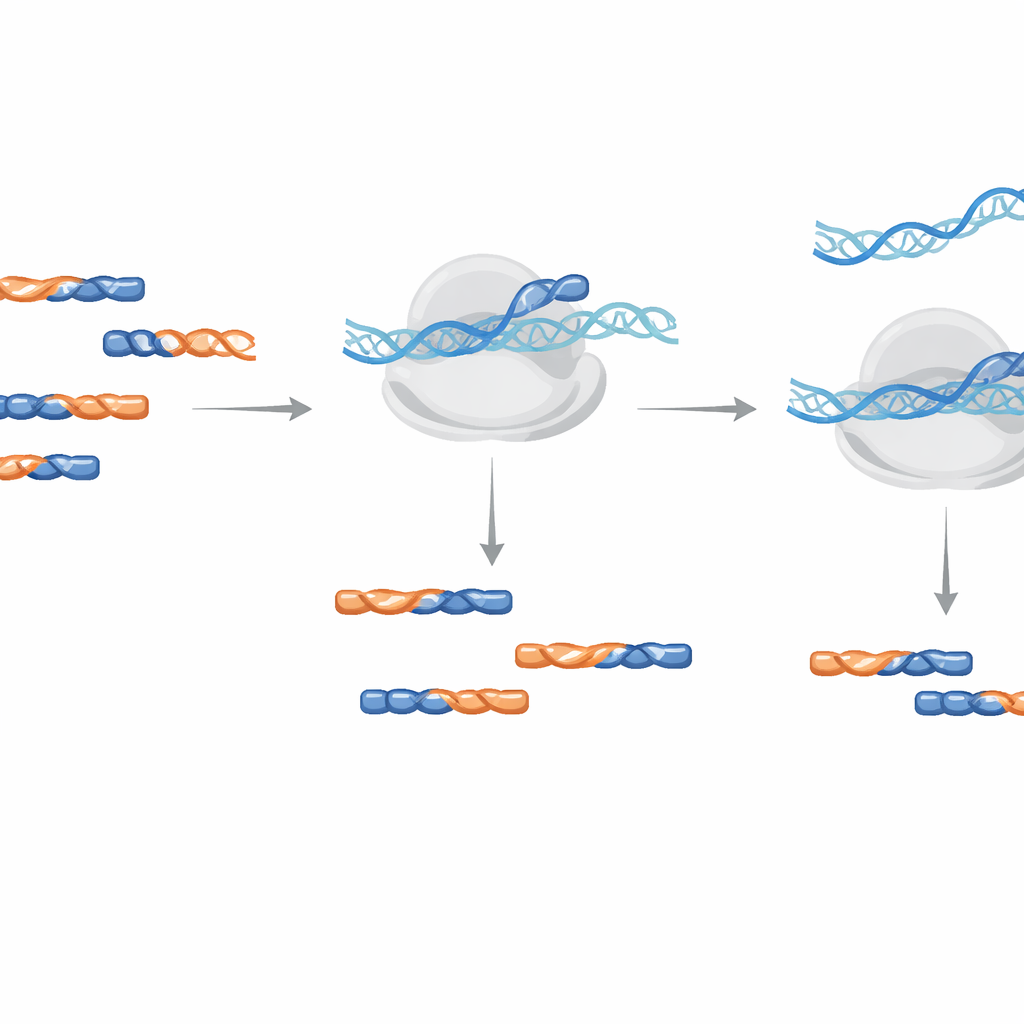
Больше полезных прочтений без искажения сигнала
Чтобы продемонстрировать работу в реальных условиях, команда спроектировала пять LNA‑блокеров, нацеленных на наиболее распространенные группы загрязнений, наблюдаемые при типичных условиях роста у Arabidopsis. При добавлении этой смеси во время амплификации библиотек доля идентифицированных загрязнений снизилась более чем на 30%, а число полезных прочтений, относящихся к кодирующим белки последовательностям, почти удвоилось. Важный момент: при сравнении подсчетов прочтений на уровне генов между библиотеками с LNA и без них значения почти полностью совпадали, что указывает на то, что блокеры удаляли мусорные фрагменты, не искажая биологический сигнал от истинных мРНК‑отпечатков.
Что это значит для будущих экспериментов
Эта работа показывает, что короткий пилотный эксперимент в сочетании с удобным скриптом анализа и небольшим набором индивидуальных LNA‑блокеров может превратить захламленные библиотеки Ribo‑Seq в гораздо более чистые и информативные наборы данных в один шаг пипетирования. Исследователи получают больше осмысленных прочтений за запуск, экономя средства и упрощая дизайн эксперимента, при этом сохраняя точность измерений трансляции генов. Авторы также предоставляют готовые профили загрязнений и проекты блокеров для обычных растительных условий и предполагают, что аналогичные ресурсы можно разработать для многих организмов, что сделает высококачественное профилирование рибосом более доступным для исследовательского сообщества.
Цитирование: Ricciardi, D.A., Peter, F.E. & Böhmer, M. Data-driven design of LNA-blockers for efficient contaminant removal in Ribo-Seq libraries. Sci Rep 16, 8565 (2026). https://doi.org/10.1038/s41598-026-43117-3
Ключевые слова: профилирование рибосом, загрязнения РНК, замкнутые нуклеиновые кислоты (LNA), очистка секвенирующих библиотек, регуляция трансляции