Clear Sky Science · ru
Переосмысление инженерии контекста с использованием архитектуры на основе внимания
Почему умные программные помощники важны
Каждый ваш клик в бизнес-приложении — вход в систему, загрузка файла, запуск отчёта — оставляет след. Если бы программное обеспечение могло надёжно предсказывать ваш следующий шаг, оно могло бы заранее подгружать данные, предлагать сокращения и отвечать почти мгновенно. В этой статье рассматривается новый способ научить компьютеры понимать такие последовательности действий настолько хорошо, чтобы цифровые ассистенты могли предугадывать, что вы сделаете дальше, чего вы пытаетесь достичь и когда собираетесь завершить работу.
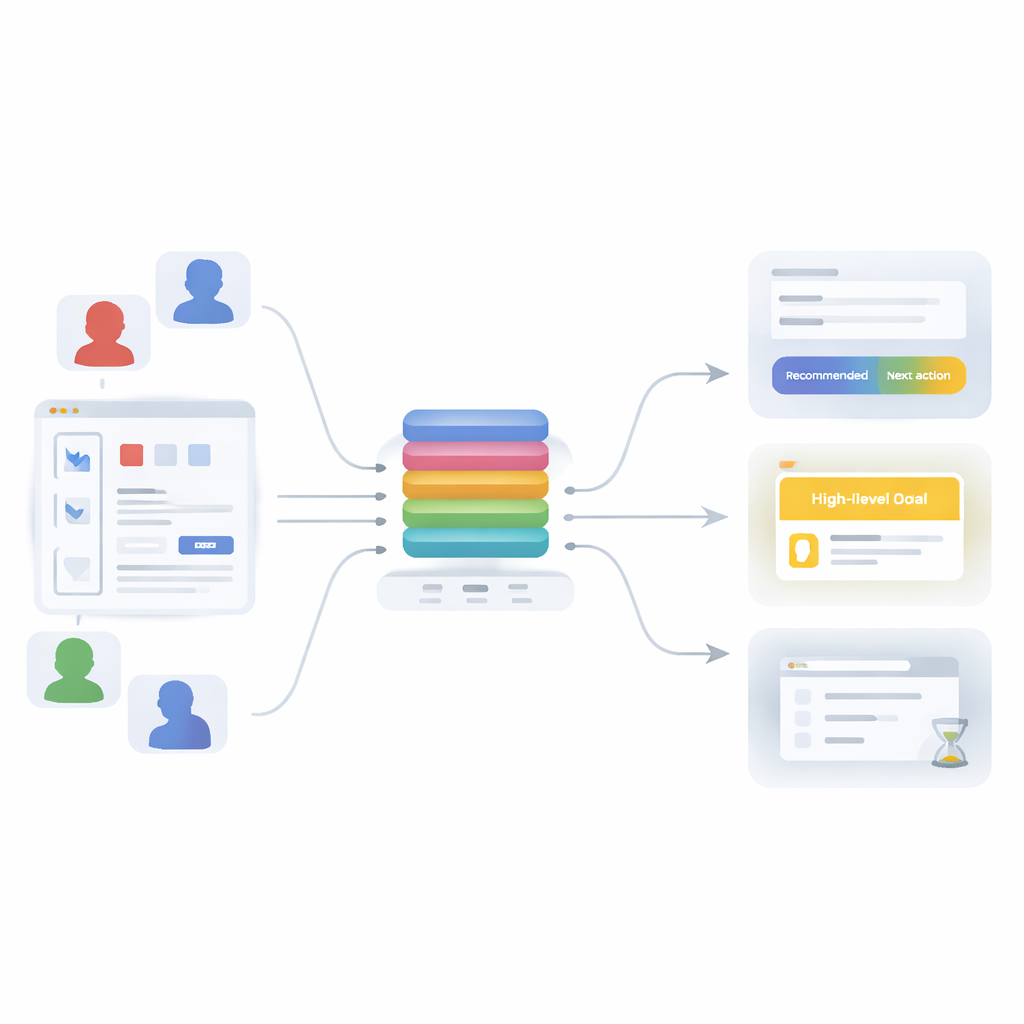
От простых цепочек к богатым шаблонам
Многие существующие системы, угадывающие следующий шаг пользователя, опираются на цепи Маркова — классический математический инструмент, который учитывает только последнее действие при прогнозе следующего. Хотя такой подход быстрый и удобный, он оказывается несостоятелен в реальных рабочих условиях, где задачи вроде построения конвейера машинного обучения или подготовки дашборда разворачиваются на многих шагах и включают разные инструменты. Авторы утверждают, что подобные простые модели упускают дальнюю структуру, способны решать лишь одну задачу прогнозирования за раз и трудно сопоставимы между исследованиями, поскольку обычно зависят от приватных логов и непрозрачных решений по очистке данных.
Новый план многозадачного обучения
Чтобы преодолеть эти ограничения, в статье предлагается модель трансформера на основе внимания — та же семья методов, что лежит в основе современных языковых инструментов — переосмысленная для поведения пользователей. Вместо обучения только одной задаче модель обучают решать одновременно три взаимосвязанные задачи: предсказывать следующее действие (какой API вызовет пользователь), определять общую цель сессии (например, запуск конвейера машинного обучения, анализ данных, управление пользователями или создание быстрой визуализации) и решать, вероятно ли, что текущий шаг является последним в сессии. Все три задачи разделяют общий «каркас», который превращает короткую историю недавних действий в единое, богатое представление происходящего, а затем передаёт его в три небольших предиктивных модуля.
Создание реалистичного тестового стенда in silico
Поскольку реальные журналы активности предприятий часто чувствительны и трудно поддаются обмену, авторы создают продвинутую симулированную среду, которая имитирует, как специалисты по данным используют большую внутреннюю платформу. Они определяют 100 различных API, сгруппированных в 10 функциональных областей, включая аутентификацию, ввод данных, обработку, обучение моделей, визуализацию, экспорт и администрирование. Четыре пользовательских персоны — дата-сайентисты, бизнес-аналитики, разработчики и продвинутые пользователи — следуют характерным, но нестрогим рабочим процессам с вероятностями, отражающими как рутинное поведение, так и случайные отклонения. Полученный набор данных содержит 2000 пользовательских сессий и 20 000 обращений к API, с целями сессий вроде «конвейер машинного обучения» и «быстрая визуализация», приводящими к узнаваемым путям: вход в систему, загрузка данных, их обработка, построение графика и экспорт результата.
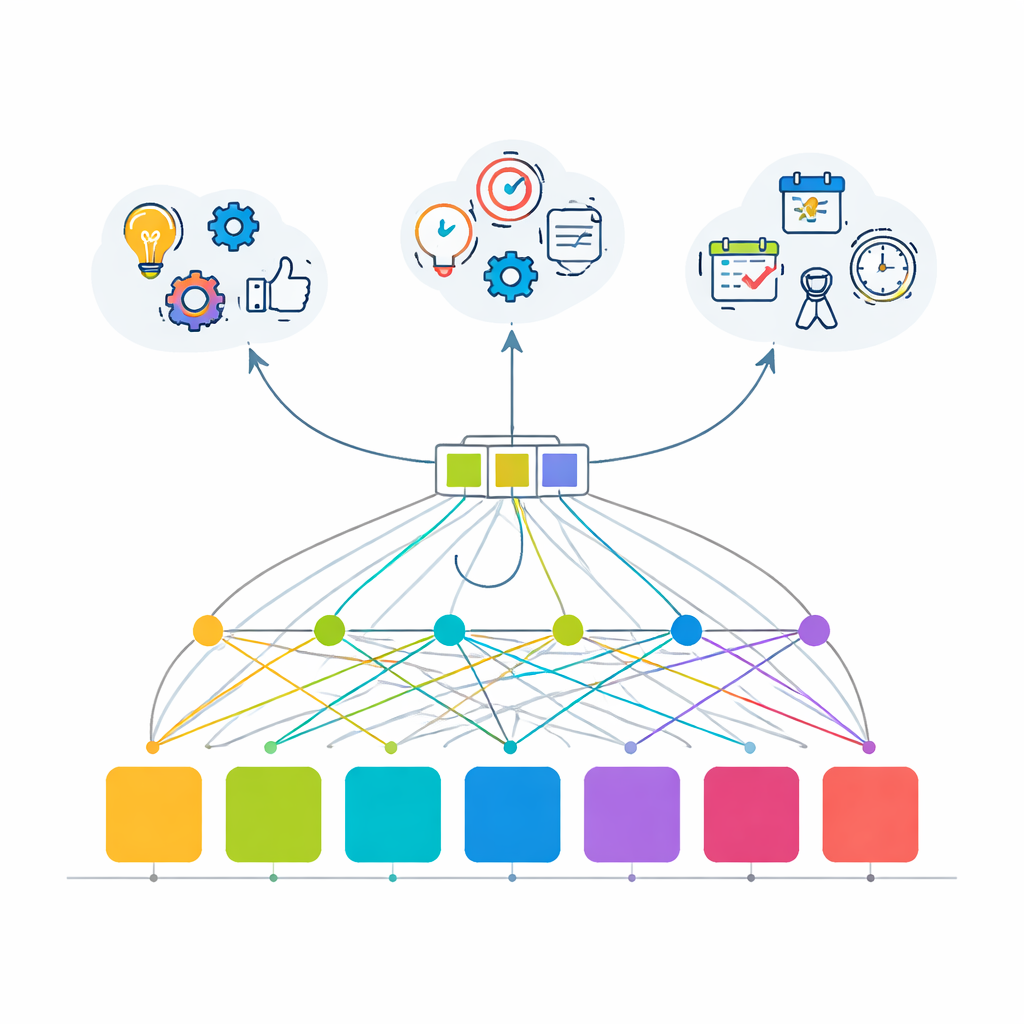
Насколько хорошо модель учится предвосхищать
Обученный в этой структурированной, но разнообразной среде, трансформер показывает, что обучение на основе внимания может захватывать скрытые закономерности в поведении пользователей гораздо лучше, чем старые методы. Для основной задачи — угадать следующий вызов API среди 100 вариантов — он даёт точный ответ почти в 80% случаев и помещает правильный вариант в топ‑5 более чем в 99.9% случаев, что превышение более чем в четыре раза по сравнению с базовой цепью Маркова. При этом модель правильно определяет общую цель сессии примерно в 82% случаев и почти идеально обнаруживает моменты завершения сессии. Авторы также подчёркивают, что модель относительно компактна и эффективна, что делает возможным её использование в реальном времени для живых ассистентов, которые должны реагировать без заметной задержки.
Инструменты для повторного использования и расширения
Чтобы их подход стал не разовым экспериментом, авторы выпускают пакет с открытым исходным кодом под названием context-engineer вместе с полным симулированным набором данных. С этими ресурсами другие исследователи и практики могут воспроизвести заявленные результаты, протестировать альтернативные модели на общем бенчмарке или подключить собственные внутренние логи, преобразовав действия и метки сессий в простой числовой формат. Такая открытость устраняет основную преграду в области, где многие прошлые системы нельзя было справедливо сравнить или повторно использовать из‑за отсутствия данных и кода.
Что это значит для повседневных пользователей
Для неспециалиста главный вывод в том, что статья предлагает практический рецепт, как сделать цифровые инструменты более «на шаг впереди». Совместно обучаясь понимать, что люди пытаются сделать, что они, вероятно, нажмут дальше и когда завершают работу, предлагаемая система на основе трансформера превращает историю пользователя в форму контекстной осведомлённости. В реальных приложениях это может означать чат‑ботов, которые готовят следующий отчёт ещё до вашего запроса, аналитические платформы, предлагающие разумные шаги для продолжения, и корпоративные дашборды, которые незаметно сокращают время ожидания. Хотя текущее исследование основано на симулированных данных и требует проверки на реальных логах, оно закладывает ясную, воспроизводимую основу для создания более умных и предвосхищающих программных помощников на разных цифровых платформах.
Цитирование: Yin, Y. Rethink context engineering using an attention-based architecture. Sci Rep 16, 8851 (2026). https://doi.org/10.1038/s41598-026-43111-9
Ключевые слова: прогнозирование поведения пользователя, последовательные рекомендации, трансформер на основе внимания, проактивные цифровые ассистенты, инженерия контекста