Clear Sky Science · ru
Решение проблемы несбалансированных данных при машинном моделировании редких и разрушительных отключений
Почему вам важны более точные прогнозы штормов
Когда сильный шторм вызывает отключение электроэнергии, мы сталкиваемся с этим очень лично: нет света, нет отопления, продукты портятся, нарушается связь. Энергокомпании пытаются предсказывать такие отключения заранее, чтобы направить ремонтные бригады и обезопасить людей. Но самые разрушительные штормы редки, поэтому данных о них удивительно мало. В этой статье показано, как новый класс искусственного интеллекта может «представлять» реалистичные редкие штормы, заполняя пробелы в записях и делая прогнозы отключений точнее именно тогда, когда это наиболее важно.
Проблема обучения на редких катастрофах
Большинство отключений электроэнергии вызывается погодой, особенно ураганами, нор'истерами, снегопадами и ледяными бурями, а также сильными грозами. По мере потепления климата эти явления становятся более интенсивными, что увеличивает нагрузку на стареющие электрические сети. Тем не менее самые разрушительные штормы по определению встречаются редко. Традиционные статистические методы и модели машинного обучения лучше учатся на многочисленных слабых и умеренных штормах и испытывают трудности с небольшим числом действительно экстремальных случаев. Это несоответствие данных приводит к заниженным оценкам ущерба именно тогда, когда энергетическим компаниям нужна надежная информация.
Обучение компьютеров создавать новые штормы
Чтобы преодолеть эту несбалансированность, авторы создают систему, генерирующую синтетические штормы — то есть события, созданные на компьютере, которые выглядят и ведут себя как реальные штормы, но не являются копиями какого-либо одного прошлого случая. Они сосредотачиваются на штате Коннектикут, представляя каждый шторм в виде сетки из 8×15 ячеек (всего 815 клеток) с 19 типами информации в каждой ячейке, включая ветер, осадки, давление, турбулентность, растительность и планировку линий электропередачи. Сначала они группируют 294 исторических шторма в 12 кластеров на основе того, сколько и где возникали «проблемные места» — участки повреждений, которые должны были ремонтировать бригады. Редкие, сильно воздействующие штормы оказываются в четырех небольших кластерах, которые нуждаются в усилении.
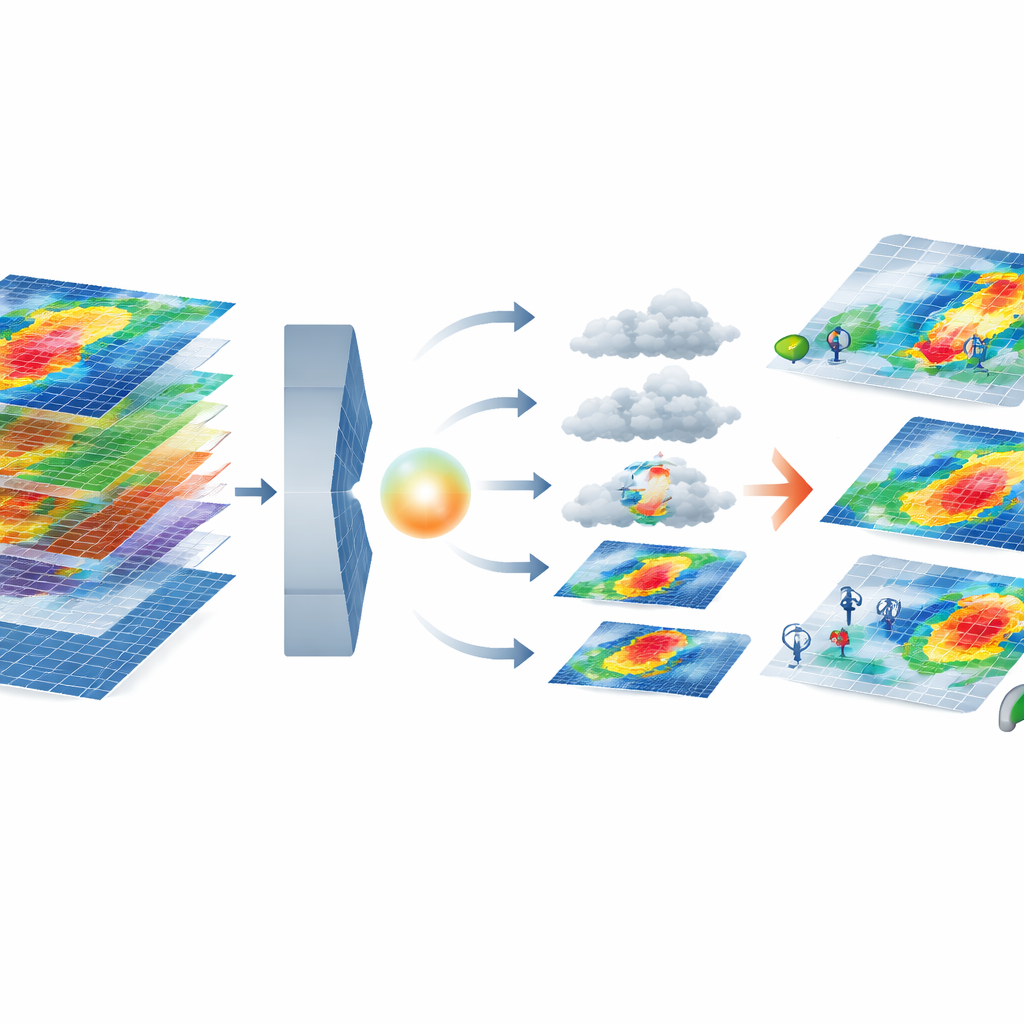
Как новая модель ИИ создаёт реалистичные экстремы
Ядро системы сочетает два современных инструмента ИИ. Вариационный автоэнкодер сжимает каждую многослойную карту шторма в пространство с меньшей размерностью — «латентное» представление, которое при этом сохраняет важные закономерности, например усиление ветров у побережья. В этом сжатом пространстве диффузионная модель учится начинать с случайного шума и постепенно превращать его в реалистичный шторм, обусловленный требуемым кластером степени повреждений. Затем система отбирает сгенерированные штормы с помощью набора метрик, сравнивающих их статистику с реальными событиями — проверяя не только отдельные характеристики вроде скорости ветра, но и совместное поведение признаков, зафиксированное в корреляционных шаблонах. Сохраняются только те синтетические штормы, которые тесно соответствуют физическому и статистическому поведению реальных штормов в данном кластере.
Проверка синтетических штормов в задаче прогноза
Авторы затем задают ключевой вопрос: действительно ли эти синтетические штормы помогают прогнозировать отключения? Они обучают существующую модель прогнозирования отключений дважды — сначала только на реальных штормах, а затем на тех же данных, обогащенных тщательно отобранными синтетическими событиями для редких, сильных кластеров. Оценку проводят с помощью строгого теста «оставь один шторм» (leave-one-storm-out), который имитирует прогнозирование новых, невиданных событий. С обогащением синтетикой структурная ошибка модели резко снижается, а общая подгонка улучшается. Для редких, наиболее разрушительных штормов среднеквадратичная ошибка снижается примерно на 45%, а сводные показатели качества, такие как эффективность Нэша–Сатклиффа, повышаются с уровней ниже эталона до явно полезных значений. Сравнение с «случайным» дополнением, при котором синтетические штормы добавляются без контроля качества, показывает гораздо меньший или даже отрицательный эффект, что подчеркивает важность строгой фильтрации.
Что это значит для будущих штормов
Проще говоря, исследование показывает, что позволив ИИ «придумывать» физически согласованные экстремальные штормы — и выборочно доверяя лишь тем из них, которые прошли проверку — можно сделать прогнозы отключений более надежными для тех событий, которые наносят наибольший ущерб. Обогащая скудные данные о редких, но разрушительных погодных явлениях, подход помогает энергетическим компаниям лучше предвидеть, сколько точек повреждения им предстоит устранить и где. Хотя демонстрация проведена для одного штата и одного типа опасности, ту же стратегию можно расширить на лесные пожары, наводнения и другие природные угрозы, предложив новый способ укрепления инфраструктурного планирования в мире растущих климатических экстремумов.
Цитирование: Azizi, M., Zhang, X., Yasenpoor, T. et al. Addressing the data imbalance issue in machine learning modeling of rare and disruptive outage events. Sci Rep 16, 8876 (2026). https://doi.org/10.1038/s41598-026-41838-z
Ключевые слова: синтетические данные штормов, прогнозирование отключений электроэнергии, диффузионные модели, экстремальная погода, несбалансированность данных