Clear Sky Science · ru
Динамический подход машинного обучения для прогнозирования нагрузки в облачных средах
Почему важно умное предсказание трафика
Каждый раз, когда вы смотрите видео по сети, следите за крупным спортивным событием онлайн или делаете покупки во время распродажи, тысячи других пользователей могут нажимать на ссылки в тот же самый момент. За кулисами облачные центры обработки данных стараются поддерживать высокую скорость работы сайтов, не тратя деньги на простаивающие машины. В этой статье рассматривается простой, но чрезвычайно практичный вопрос: как облачные системы могут предвидеть внезапные всплески веб‑трафика достаточно заранее, чтобы включать и выключать серверы вовремя, а не полагаться на догадки и переплачивать?
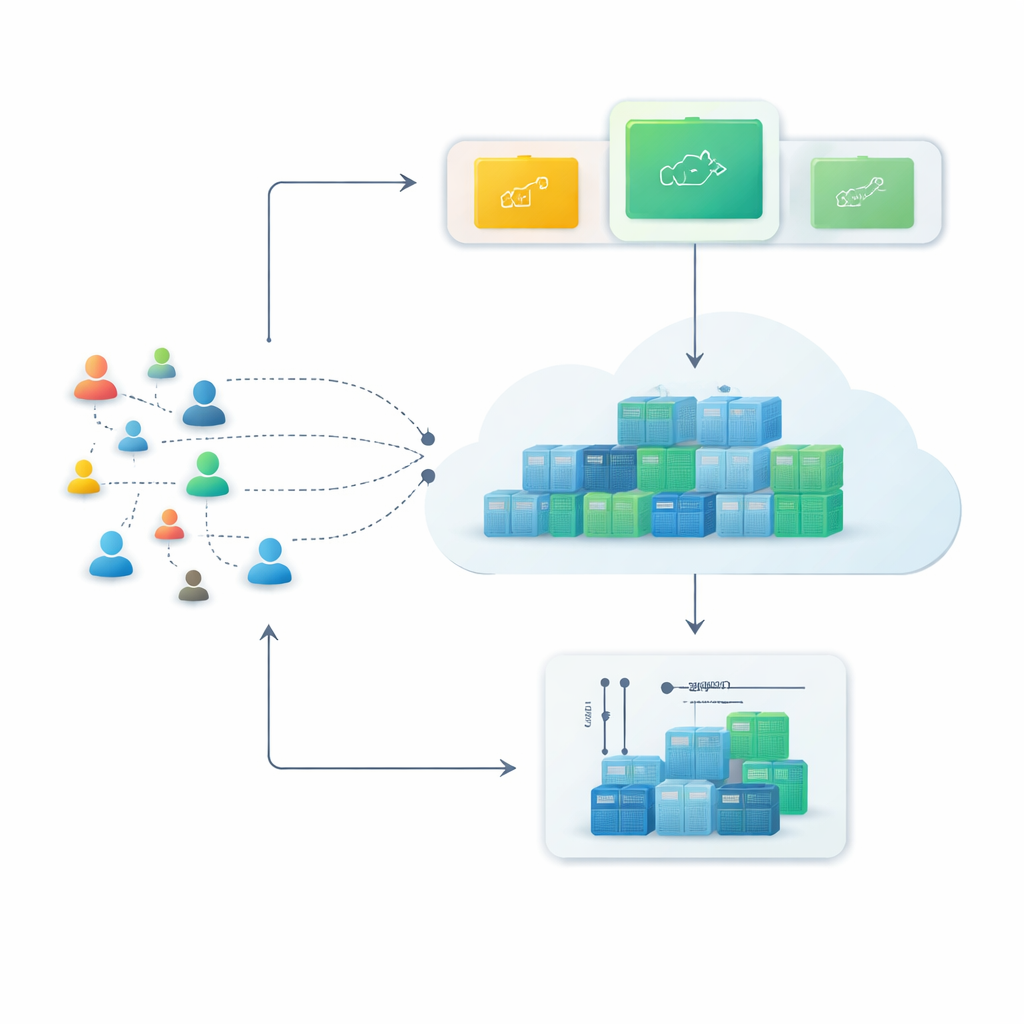
От жестких серверов к гибким контейнерам
Современные облачные платформы всё чаще опираются на контейнеры — небольшие программные пакеты, которые можно запускать или останавливать за считанные секунды. По сравнению с традиционными виртуальными машинами контейнеры легче и их можно плотнее упаковать, что делает их идеальными для сервисов, которым нужно быстро расти в часы пик и затем сокращаться. Однако эта гибкость окупается лишь в том случае, если система умеет предвидеть проблемы — если она способна предсказать, сколько веб‑запросов придёт в ближайшие минуты, и приготовить нужное количество контейнеров заранее.
Почему универсальные прогнозы не работают
Ранее в исследованиях пробовали множество подходов к прогнозированию веб‑трафика — от классической статистики до глубоких нейронных сетей. Одни методы хорошо работают при плавных суточных изменениях спроса; другие показывают себя лучше при внезапных скачках, например во время матча чемпионата мира. Проблема в том, что ни один метод не является лучшим всегда. Если операторы выберут одну модель и будут пользоваться только ей, точность может резко упасть при смене поведения пользователей, что приводит либо к медленной работе сайтов, либо к ряду недозагруженных машин, тихо потребляющих деньги и энергию.
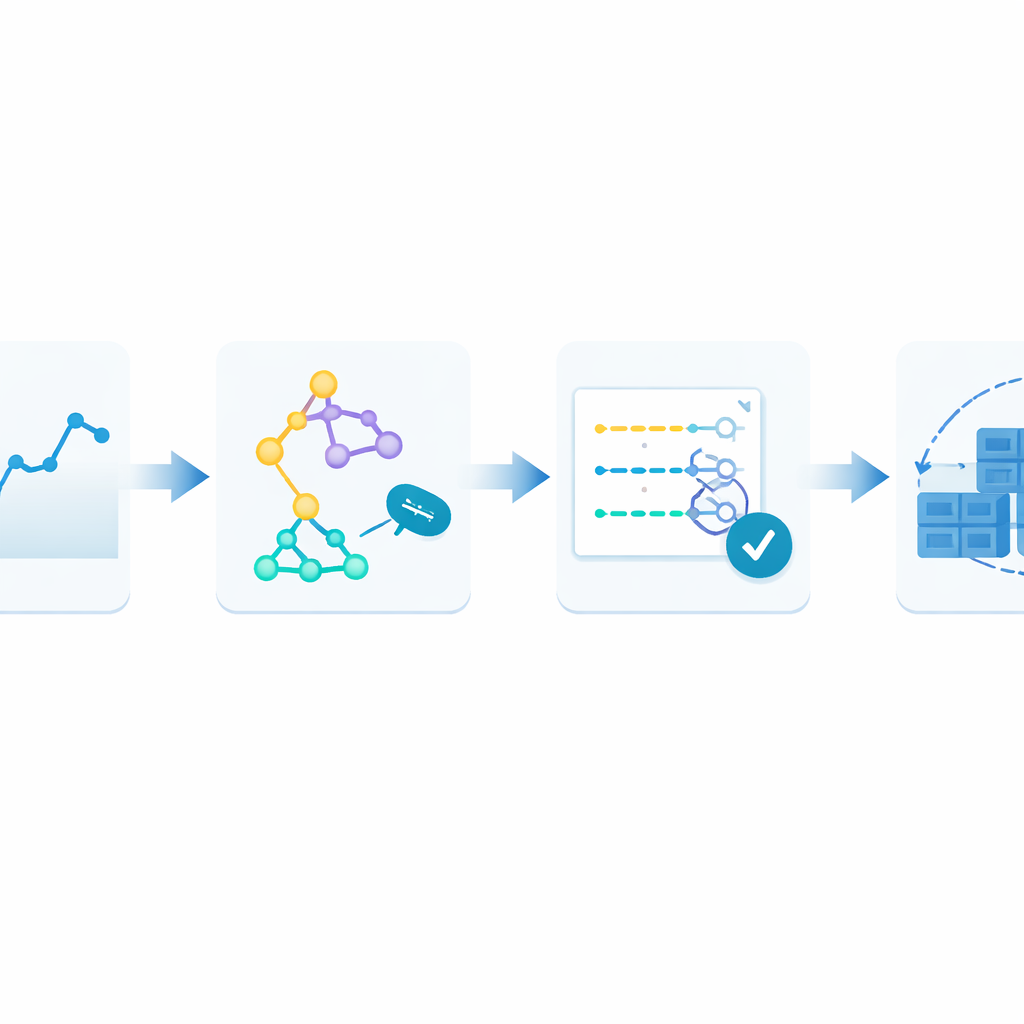
Цикл обучения, который никогда не перестаёт адаптироваться
Чтобы преодолеть это, авторы предлагают замкнутую структуру, которую они называют Монитор‑Тренировка‑Тест‑Развёртывание. Идея в том, чтобы рассматривать само прогнозирование как живой процесс. Сначала система непрерывно записывает входящие веб‑запросы с метками времени в историю. Затем параллельно обучаются несколько различных методов прогнозирования, каждый пытается выучить закономерности в этой недавней истории. Далее кандидаты тестируются на самых свежих данных и оцениваются по тому, насколько их прогнозы отклоняются от реальности. В эксплуатацию выводится только лучшая модель, которая отвечает за живые прогнозы и определяет, сколько контейнеров запускать. По мере поступления нового трафика цикл повторяется: если ошибки прогнозирования растут сверх допустимого уровня два раза подряд, система автоматически переобучается и может передать управление другой модели.
Проверка фреймворка на практике
Исследователи оценили этот подход на синтетических и реальных записях веб‑активности. Они сгенерировали несколько идеализированных шаблонов — плавные колоколообразные кривые, устойчиво растущие нагрузки с разной скоростью и крайне неустойчивый трафик — а также использовали данные с официальных сайтов чемпионата мира 1998 и 2018 годов, где интерес резко всплывал. Для каждого случая они сравнивали три‑четыре знакомых инструмента прогнозирования, включая статистический метод, модель опорных векторов, ансамбль деревьев решений и, в более поздних экспериментах, популярный тип рекуррентной нейронной сети. Ключевой вывод состоял в том, что «победитель» менялся в зависимости от ситуации: простые статистические модели превосходили при стабильном спросе, тогда как методы обучения показывали явное преимущество при диком, прерывистом трафике.
Улучшение точности и эффективности
Постоянно переключаясь на ту модель, которая в данный момент лучше соответствовала наблюдаемому поведению, фреймворк сократил ошибки прогнозирования примерно до 15 процентов по сравнению с фиксацией на любой одной модели. Не менее важно то, что это было достигнуто без одновременного запуска всех моделей. Во время работы в реальном времени активен только один предсказатель; остальные переобучаются и проверяются периодически, что сохраняет вычислительную нагрузку умеренной. Авторы также вводят постепенно ужесточающийся порог для переобучения, так что система становится менее терпимой к повторяющимся ошибкам, снижая риск длительных периодов некачественного прогнозирования.
Что это значит для обычных пользователей облака
Практически это исследование показывает, что облачные платформы можно сделать умнее, позволяя моделям прогнозирования соревноваться и адаптируя их выбор со временем. Для пользователей это может означать более плавный онлайн‑опыт во время крупных событий и меньше замедлений при внезапном наплыве посетителей. Для провайдеров это обещает более бережное использование вычислительных ресурсов, более низкие эксплуатационные расходы и меньшие энергозатраты. Вместо того чтобы ставить на одну «умную» модель, работа выступает за гибкую управляющую петлю, которая постоянно учится, тестирует и корректирует способы предвидения спроса в всё более непредсказуемом цифровом мире.
Цитирование: Nashaat, M., Moussa, W., Rizk, R. et al. Dynamic machine learning approach for workload prediction in cloud environments. Sci Rep 16, 10983 (2026). https://doi.org/10.1038/s41598-026-40777-z
Ключевые слова: прогнозирование нагрузки в облаке, автоскейлинг, контейнеры, машинное обучение, временные ряды