Clear Sky Science · ru
Система многопользовательского поиска с сохранением приватности для мультимодального искусственного интеллекта
Почему важно сохранять приватность интеллектуальных поисков
Многие из нас теперь полагаются на облачный искусственный интеллект, чтобы просеивать фотографии, документы и даже медицинские снимки. Эти системы мощны, потому что понимают и изображения, и текст, но они также ставят серьёзный вопрос: как пользоваться этим удобством, не передавая смысл самых чувствительных данных на удалённые серверы? В этой статье представлен PMIRS — новая система, призванная позволить множеству пользователей выполнять поиск по смешанным коллекциям изображений и текста, одновременно скрывая их информацию от облачных машин, которые обрабатывают запросы.
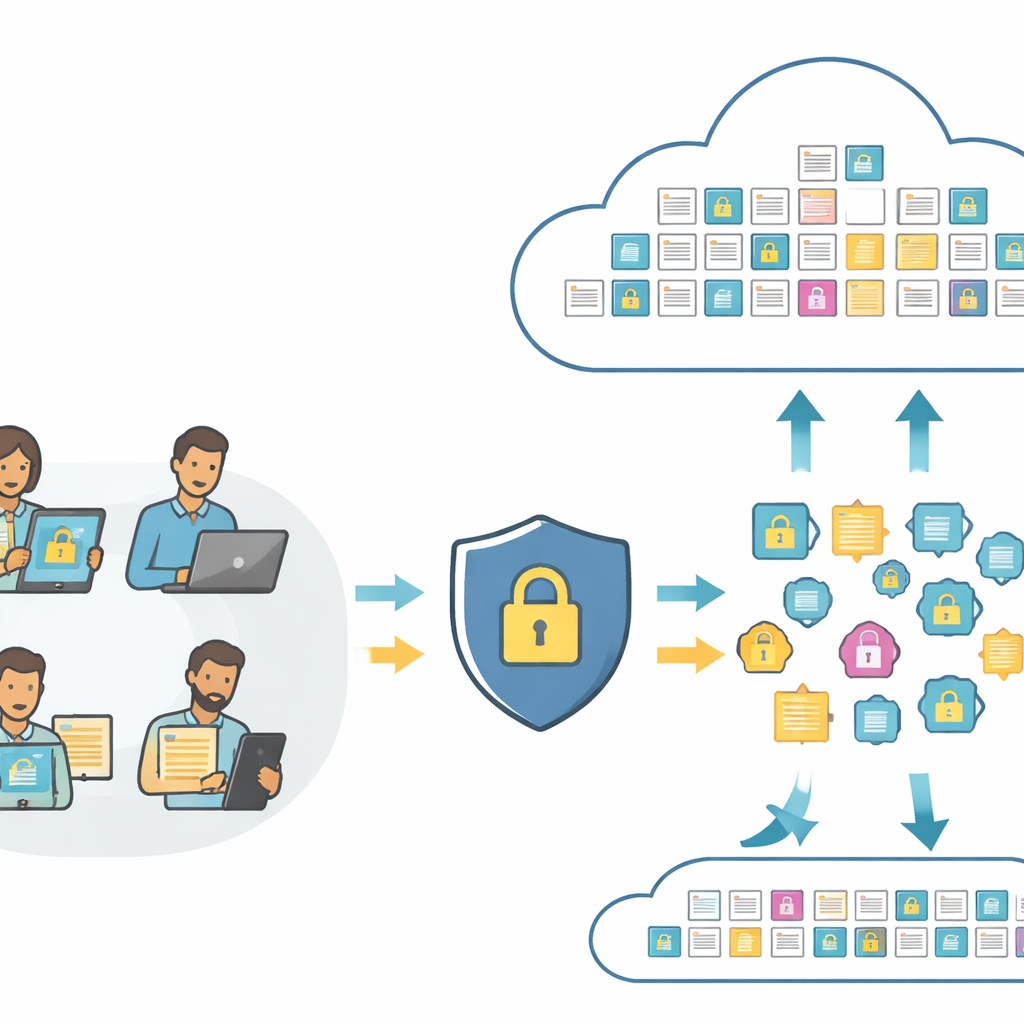
Поиск по картинкам и тексту без раскрытия их смысла
В основе современных средств поиска лежат «встраивания» (embeddings) — числовые отпечатки, которые фиксируют содержание фотографии или предложения, чтобы компьютер мог их сравнивать. Стандартные системы отправляют эти отпечатки прямо в облако, где их можно анализировать или даже злоупотреблять ими. PMIRS перестраивает этот процесс. Пользователи сначала отправляют свои необработанные изображения и тексты в локальный слой, который превращает их в отпечатки с помощью компактной модели, работающей с изображением и языком. Прежде чем что‑либо покинет устройство пользователя, отпечатки целенаправленно перемешиваются и затем шифруются. Облако видит только эти защищённые отпечатки и полностью зашифрованные копии хранимых данных, но при этом всё ещё способно выполнять сопоставление и возвращать лучшие совпадения.
Обучение на данных многих пользователей без их объединения
Для обучения хорошей модели изображения–текста обычно требуется собрать огромные объёмы размеченных примеров в одном месте — явный риск для приватности. PMIRS вместо этого использует федеративное обучение. В этой схеме базовая модель, адаптированная от известной архитектуры CLIP, распространяется на множество устройств. Каждое из них обучается локально на своих приватных парах изображение–текст и отправляет обратно лишь обновлённые веса модели, которые сами по себе зашифрованы. Центральный сервер усредняет эти обновления, чтобы улучшить общую модель, не видя при этом никаких исходных фотографий или описаний пользователей. Авторы дополнительно сокращают и дообучают модель через поэтапный процесс «дистилляции», который удаляет лишние части при сохранении точности, делая систему достаточно лёгкой для практического развёртывания.
Скрытие смысла внутри перемешанных отпечатков
PMIRS защищает запросы двумя уровнями. Сначала каждый отпечаток разбивается на блоки, и каждый блок преобразуется секретной матрицей с добавлением специально сконструированного шума. Это перемешивание скрывает исходную структуру данных, но устроено так, что когда два связанных элемента оба преобразованы, их сходство сохраняется. Затем результат шифруется с помощью широко применяемого метода AES, причём ключи никогда не передаются в открытом виде по сети. В ситуациях, когда один человек должен искать в данных другого — например, врач, консультирующийся со специалистом — система использует протокол обмена ключами Диффи–Хеллмана, чтобы стороны могли согласовать общие секреты, не раскрывая их прослушивающим.
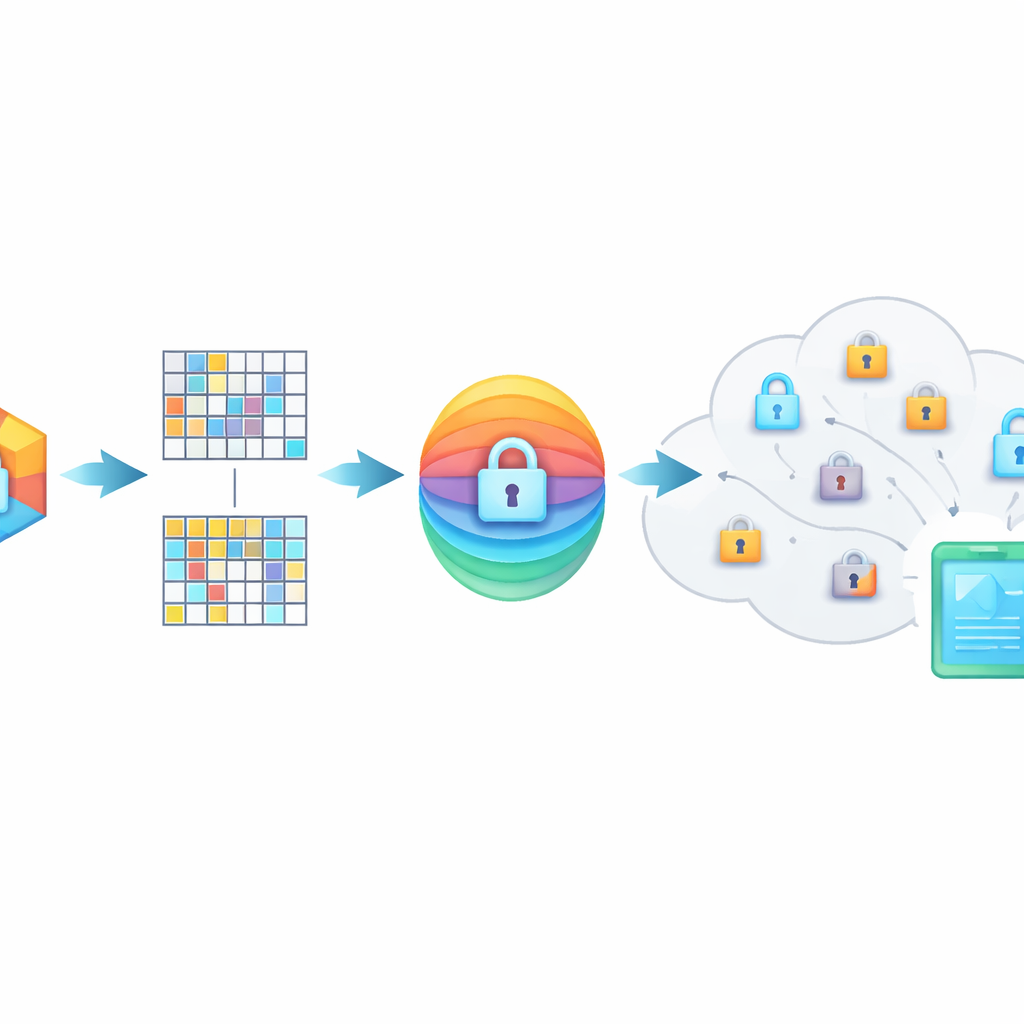
Как система работает на практике
Чтобы проверить, не слишком ли высокая цена за эти защиты, исследователи создали эталонный набор, сопоставляющий повседневные изображения с короткими фразами на естественном языке — ближе к тому, как люди действительно описывают вещи, чем одиночные метки. Они сравнили PMIRS со стандартным поиском на базе CLIP по трём темам: природные сцены, производственные объекты и действия или пейзажи. При разных размерах репозиториев PMIRS последовательно обеспечивал лучшую сбалансированность между полнотой (recall) и точностью (precision), что приводило к среднему F1‑скорью — комбинированной метрике точности — примерно на 7,7% выше, чем у базовой модели. Важно, что время отклика оставалось ниже примерно 180 миллисекунд — достаточно быстро для интерактивного использования — и зачастую было слегка быстрее, чем у небезопасного эталона, несмотря на дополнительные шаги защиты.
Что это значит для обычных пользователей
Проще говоря, PMIRS показывает, что можно создать облачные поисковые инструменты, которые хорошо понимают изображения и текст, обслуживают много пользователей одновременно и при этом не дают провайдеру облака доступа к смыслу личных данных. Объединяя локальное обучение, интеллектуальное перемешивание отпечатков, надёжное шифрование и безопасный обмен ключами, система предлагает сквозной конвейер защиты приватности, а не охрану только одной стадии. Хотя она ещё не покрывает все возможные атаки и потребует доработки и полевых испытаний, эта работа указывает путь к будущим сервисам — таким как поиск по медицинским изображениям, боты поддержки клиентов или корпоративные архивы — где люди смогут пользоваться мощным мультимодальным поиском с меньшими опасениями, что их личный контент будет раскрыт или использован неправомерно.
Цитирование: Gao, Y., Luo, W., Wang, C. et al. A privacy-preserving multi-user retrieval system for multimodal artificial intelligence. Sci Rep 16, 10348 (2026). https://doi.org/10.1038/s41598-026-40734-w
Ключевые слова: AI с сохранением приватности, мультимодальный поиск, федеративное обучение, шифрованный поиск, безопасные облачные вычисления