Clear Sky Science · ru
Модель на основе кластеризации и регрессии и анализ эффективности для раннего прогнозирования сердечных заболеваний
Почему важно выявлять проблемы с сердцем на ранней стадии
Сердечные заболевания часто развиваются бессимптомно в течение многих лет, и к моменту появления явных симптомов вред может уже быть нанесён. В этом исследовании рассматривается, как повседневные носимые датчики и интеллектуальная обработка данных могут совместно обнаруживать предупреждающие признаки раньше, давая врачам и пациентам больше времени для вмешательства. Объединяя два разных подхода к анализу медицинских данных, авторы стремятся повысить точность прогнозов, не усложняя технологию для использования в реальных клинических условиях.
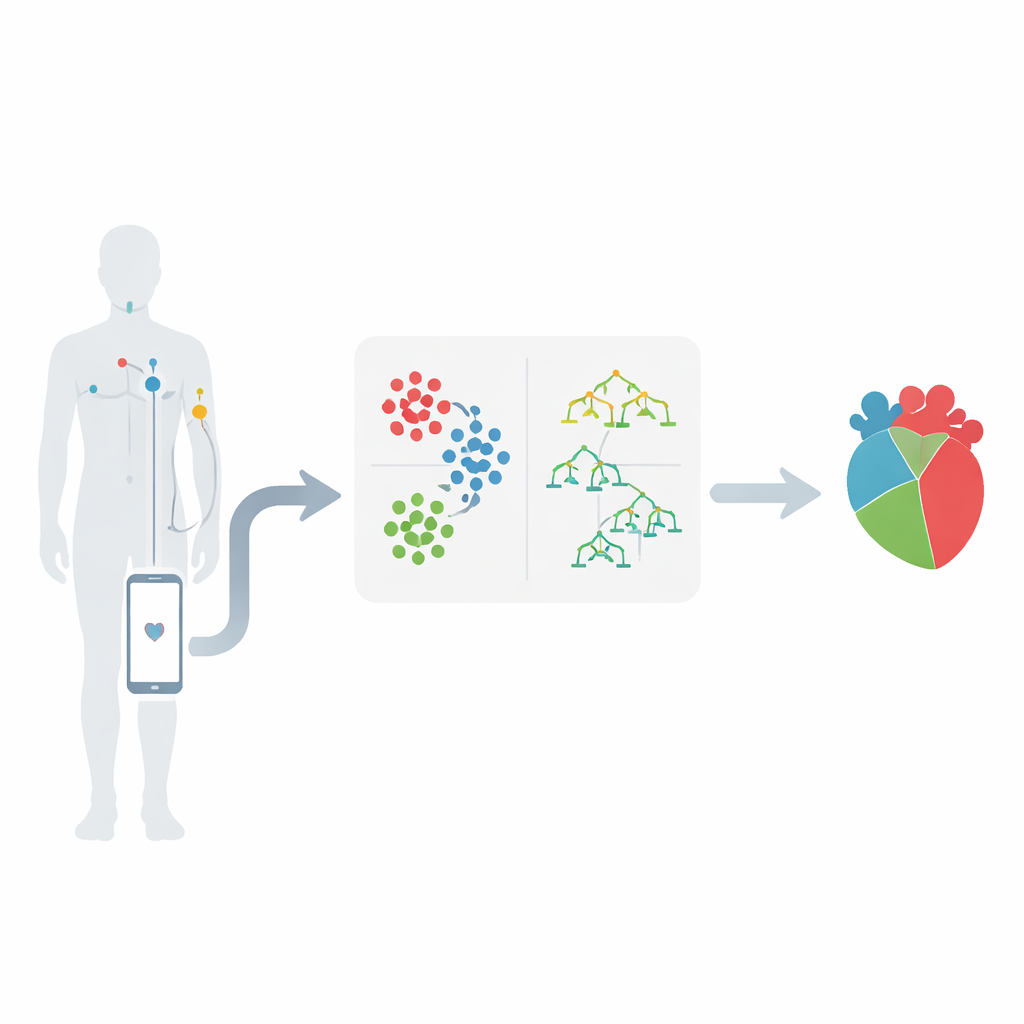
От датчиков на теле до умных предупреждений
Работа проводится в контексте беспроводных персональных сенсорных сетей, где небольшие датчики на коже отслеживают параметры, такие как частота сердечных сокращений, артериальное давление и электрическая активность сердца. Эти датчики передают измерения на мобильное устройство, которое пересылает их в медицинский центр для анализа. Ключевая идея заключается в том, что потоки таких численных данных могут выявлять закономерности, указывающие на развивающиеся сердечные проблемы задолго до кризиса. Авторы сосредотачиваются на известном наборе данных по сердечным заболеваниям, выбирая 12 важных признаков, включая тип боли в груди, артериальное давление, уровень холестерина, уровень сахара в крови, боль в груди, вызванную физической нагрузкой, и изменения, фиксируемые на электрокардиограмме.
Поиск скрытых групп в данных пациентов
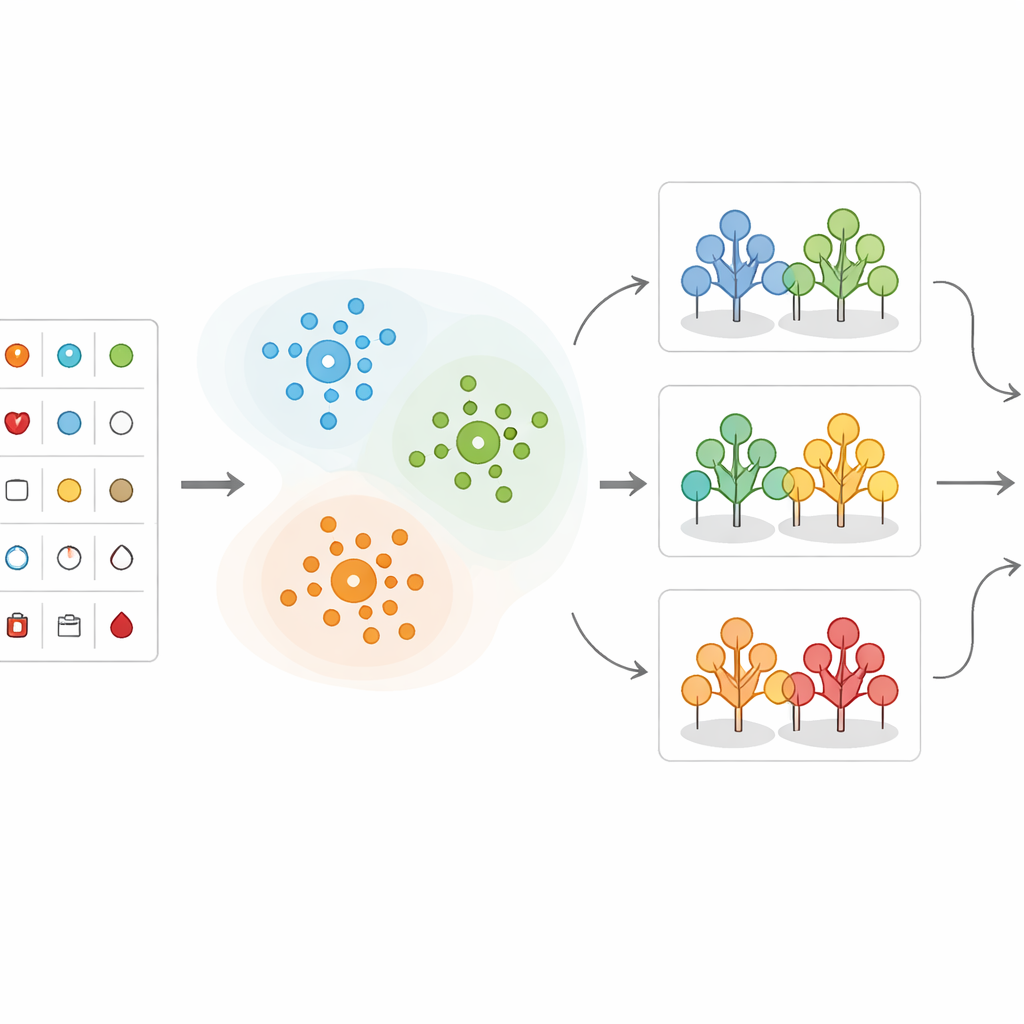
Вместо того чтобы подавать все записи пациентов напрямую в одну формулу прогнозирования, команда сначала группирует похожих пациентов. Они используют метод K-средних (K-means), который распределяет людей по кластерам на основе сходства их измерений, при этом возраст занимает центральное место. Например, пациенты естественно разделяются на группы с очень высоким кровяным давлением, высоким уровнем холестерина или с определёнными паттернами в результатах сердечных тестов. Этот шаг кластеризации помогает выделить комбинации измерений, которые особенно тревожны. Он также показывает, что определённые диапазоны — такие как артериальное давление выше 150, холестерин выше 300 или характерные изменения на кардиограмме — как правило, связаны с существенно повышенным риском.
Обучение моделей оценивать риск
После группировки данных исследователи применяют несколько методов машинного обучения, которые учатся на прошлых случаях и прогнозируют, является ли новый пациент склонным к значимой сердечной болезни. Они сравнивают различные подходы, включая решающие деревья, метод k ближайших соседей, опорные векторы, логистическую регрессию, наивный байесовский классификатор и случайный лес. В их гибридной схеме каждый новый пациент сначала назначается в ближайший кластер; затем модель случайного леса, обученная специально на этом типе пациентов, делает окончательный прогноз риска. Данные тщательно очищаются, масштабируются и разделяются на обучающую и тестовую выборки, а дисбаланс классов (больше здоровых, чем больных) учитывается, чтобы модели не смещались в пользу большинства.
Насколько хорошо работает гибридная модель
Для оценки успеха исследование рассматривает не только общую точность, но и то, как часто модель правильно отмечает больных пациентов (полнота), правильно подтверждает здоровье у здоровых (специфичность) и балансирует обе цели (F1‑мера и ROC–AUC). Ранние исследования на похожих данных часто достигали примерно 85% точности и испытывали трудности с улучшением этих более тонких метрик. Здесь подход, сочетающий кластеризацию и случайный лес, достигает около 91% точности, с высокой полнотой и очень высокой специфичностью. Интервалы доверия для этой модели не перекрываются с интервалами более простых методов, что указывает на то, что улучшение вряд ли объясняется случайностью. При этом время вычислений остаётся в практичном диапазоне — от миллисекунд до секунд — что подходит для систем мониторинга в реальном или близком к реальному времени.
Что это значит для пациентов и врачей
Проще говоря, исследование показывает, что если дать компьютерам сначала распределить пациентов по значимым группам, а затем применять адаптированные правила прогнозирования, можно повысить точность раннего выявления сердечных заболеваний. Метод особенно перспективен для систем непрерывного мониторинга, где носимые датчики незаметно собирают данные в фоновом режиме. Хотя результаты получены на умеренно большом структурированном наборе данных, а не на полных клинических записях, и авторы предупреждают о возможных смещениях, посыл ясен: более умное использование имеющихся измерений может дать врачам более надёжную систему раннего предупреждения. При дальнейшем развитии и использовании более крупных и богатых данных такие гибридные подходы могут превратить сырые показания датчиков в своевременные персонализированные сигналы, которые предотвратят инфаркты и другие серьёзные события до их наступления.
Цитирование: Tolani, M., AlZahrani, Y., Suman, G. et al. Clustering-cum-regression based model and performance analysis for early prediction of heart disease. Sci Rep 16, 9494 (2026). https://doi.org/10.1038/s41598-026-40626-z
Ключевые слова: прогнозирование сердечных заболеваний, носимые медицинские датчики, машинное обучение, кластеризация медицинских данных, модель случайного леса