Clear Sky Science · ru
Точные коллизии признаков в нейронных сетях
Когда разные изображения обманывают умную машину
Современные системы искусственного интеллекта умеют распознавать лица, анализировать медицинские снимки и управлять самоуправляемыми автомобилями. Уже известно, что их можно обмануть крошечными, тонко подобранными изменениями изображения. В этой работе показано нечто ещё более неожиданное: те же самые сети могут не замечать крупные, очевидные изменения, относя разные изображения как будто к одному и тому же. Понять, как и почему это происходит, критично, если мы хотим доверять системам ИИ по-настоящему.
От мелких правок к большим слепым пятнам
Глубокие нейронные сети лежат в основе современных прорывов в области зрения, языка и многих других областей. Ранние исследования адверсариальных примеров показали, что едва заметное изменение изображения может заставить сеть с высокой уверенностью ошибочно классифицировать его. Более поздние работы выявили обратную проблему: некоторые сети почти не реагируют на большие, очевидные изменения и продолжают выдавать почти одинаковые предсказания. В таких случаях внутренние признаки, извлечённые из двух очень разных изображений, «сталкиваются», то есть сеть представляет их почти одинаково. Это исследование идёт дальше, доказывая, что в распространённых сетях возможны не только приближённые коллизии, но и точные коллизии признаков, когда два различные входа отображаются в точно одинаковые внутренние сигналы.
Как внутри сети возникают коллизии
Чтобы объяснить эти коллизии, авторы заглядывают под капот нейронных сетей и фокусируются на матрицах весов — обученных числах, которые связывают один слой с другим. Коллизия признаков происходит, когда два разных входа дают одинаковый выход на некотором слое; как только это случается, все последующие слои также видят одно и то же и поэтому не могут различить входы. Математически это происходит, когда разность двух входов лежит в «нуль-пространстве» матрицы весов слоя: направления в пространстве входов, которые слой полностью игнорирует. Авторы показывают, что всякий раз, когда матрица весов имеет нулевое собственное значение или отображает пространство более высокой размерности в пространство меньшей размерности, такие игнорируемые направления обязательно существуют. Поскольку большинство реальных архитектур, включая популярные модели для классификации, сегментации и детекции объектов, используют много таких слоёв, коллизии — это не редкие пограничные случаи, а почти неизбежное свойство этих сетей.
Новый способ строить коллидирующие входы
Опираясь на это наблюдение, работа предлагает практический рецепт под названием «поиск нуль-пространства». Вместо того чтобы полагаться на метод проб и ошибок или градиентные приёмы, этот метод напрямую использует нуль-пространство первой матрицы весов. Начиная с любого изображения, авторы вычисляют вектор, которого первый слой не замечает, затем добавляют к изображению масштабированную версию этого вектора. Поскольку это направление невидимо для слоя, внутренние признаки сети — и итоговое предсказание — остаются точно теми же, даже если само изображение человеку кажется сильно исказённым. Та же идея распространяется на сверточные слои и, в принципе, на более поздние слои. Авторы исследуют множество стандартных моделей и находят, что у большинства есть в избытке таких игнорируемых направлений, значит можно сгенерировать бесчисленное множество коллидирующих изображений для широкого круга задач.
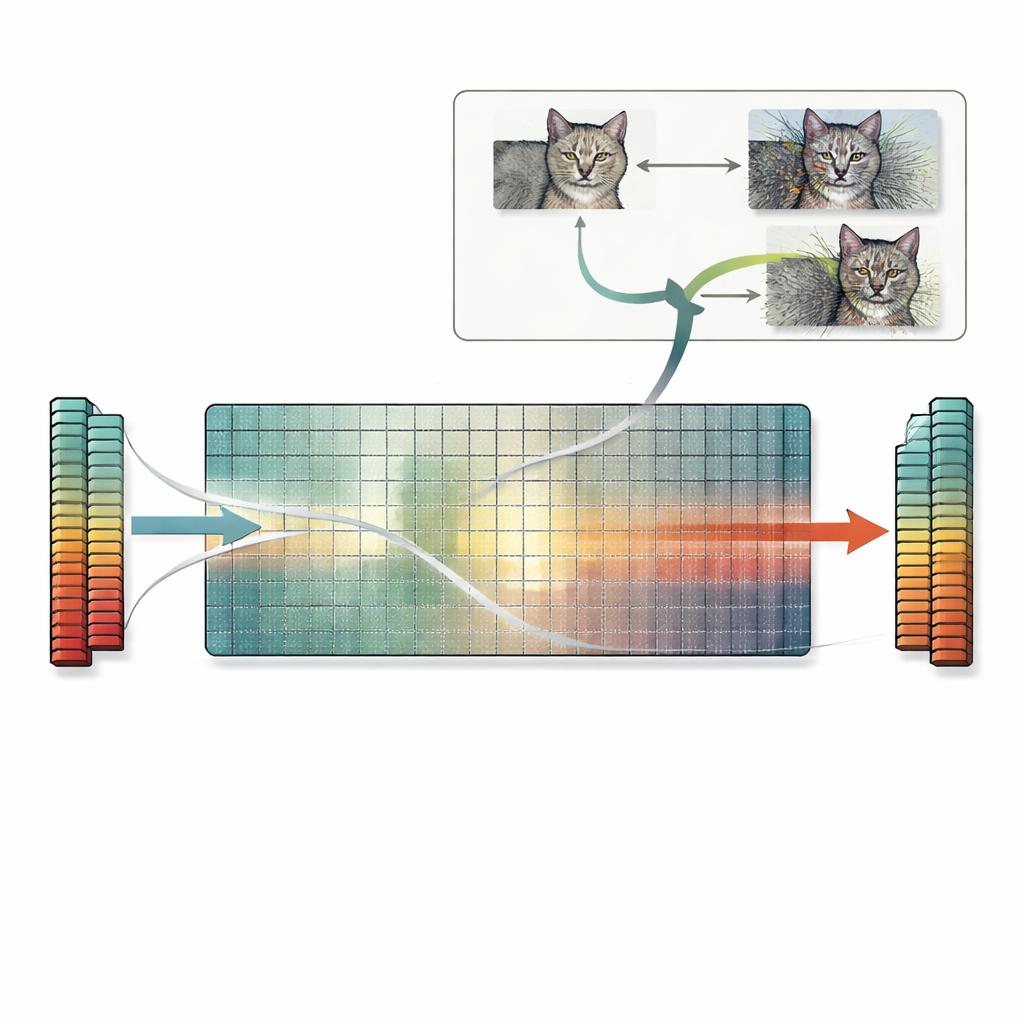
Скрытые риски для мер сходства, объяснений и безопасности
Эти точные коллизии признаков имеют далеко идущие последствия. Два изображения с коллидирующими признаками не только будут иметь одинаковое предсказание, но часто также получат одинаковые карты объяснений, выдаваемые популярными инструментами интерпретируемости. Это может сделать неузнаваемое, сильно искажённое изображение выглядящим столь же убедительно подтверждённым, как и чистое, подрывая доверие к методам объяснения. Проблема также затрагивает меры сходства на основе признаков, которые полагаются на нейронные сети: такие метрики могут признать сильно повреждённое изображение «идентичным» оригиналу, потому что признаки совпадают точно, хотя простые пиксельные метрики правильно укажут на большие различия. Наконец, поиск нуль-пространства можно сочетать со стандартными адверсариальными атаками, порождая множество различных адверсариальных изображений, которые все дают одинаковое неправильное предсказание и остаются в пределах стандартных ограничений возмущений, что усугубляет существующие проблемы безопасности.
Что это означает для создания более безопасного ИИ
Проще говоря, эта работа показывает, что современные нейронные сети часто выбрасывают информацию предсказуемыми способами, оставляя целые направления в пространстве входов, которые никак не влияют на их решения. Злоумышленники могут эксплуатировать эти слепые пятна, создавая странные или адверсариальные изображения, которые сеть считает идентичными нормальным. Авторы предлагают использовать простые счёты таких игнорируемых направлений как меру уязвимости модели и утверждают, что более «тонкие», лучше регуляризованные сети с меньшими нуль-пространствами могут быть более устойчивыми. Хотя на практике ещё многое нужно проверить, центральное послание ясно: если мы хотим надёжный ИИ, нужно обращать внимание не только на то, на что сети реагируют, но и на то, что они игнорируют.
Цитирование: Ozbulak, U., Rao, S., De Neve, W. et al. Exact feature collisions in neural networks. Sci Rep 16, 10139 (2026). https://doi.org/10.1038/s41598-026-40605-4
Ключевые слова: нейронные сети, атаки-адверсари, коллизии признаков, устойчивость моделей, поиск нуль-пространства