Clear Sky Science · ru
CMT-Unet: использование поэтапной гибридной архитектуры для повышения точности и эффективности сегментации медицинских изображений
Более четкий взгляд внутрь тела
Современная медицина во многом опирается на такие исследования, как КТ и МРТ, чтобы заглянуть внутрь организма, но превращение этих размытых оттенков серого в четкие контуры органов и тканей по‑прежнему вызывает трудности. Врачам нужны точные границы для планирования операций, отслеживания функции сердца или оценки реакции опухоли на лечение. В этой статье представлен новый подход компьютерного зрения, названный CMT-Unet, разработанный для более точной и эффективной выделки таких границ, что приближает автоматизированный анализ изображений к повседневному клиническому применению.
Почему контуры изображений важны
Перед операцией или сложным лечением клиницистам часто требуется поксельная карта органов или структур на снимке — процесс, известный как сегментация. Традиционно специалисты обводили эти области вручную, что отнимало много времени и было уязвимо к вариабельности между наблюдателями. За последнее десятилетие методы глубокого обучения взяли на себя большую часть этой работы, особенно модели на основе сверточных нейронных сетей и механизмов внимания в стиле Transformer. Сверточные модели хорошо улавливают локальные тонкости, такие как края, тогда как Transformers особенно эффективны в захвате более широкого контекста по всему изображению. Однако у каждого подхода есть свои ограничения: свертки могут упускать дальние зависимости, а Transformers часто требуют значительных вычислительных ресурсов и оперативной памяти.
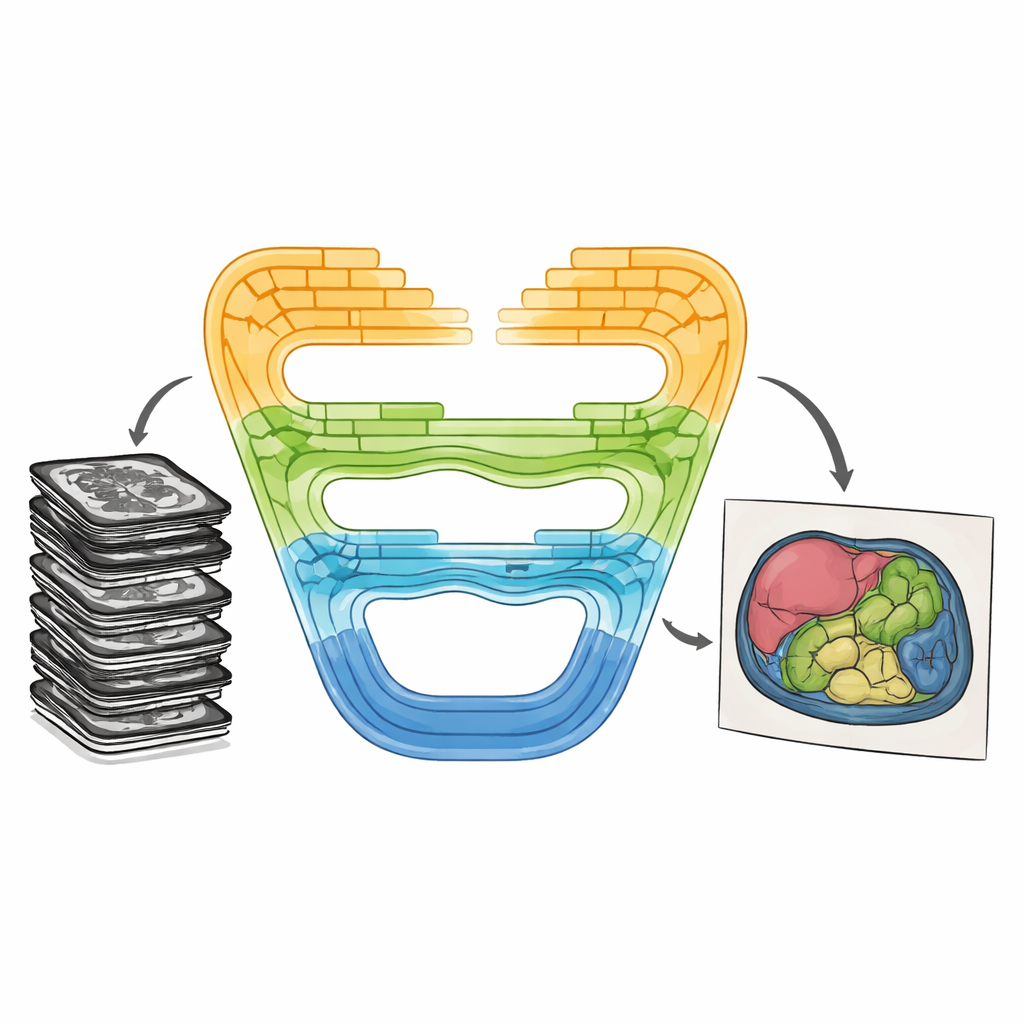
Новая комбинация сильных сторон
CMT-Unet решает эти компромиссы, объединяя три типа блоков поэтапно, вместо того чтобы полагаться на один тип по всей сети. В начале системы инвертированный остаточный сверточный блок быстро обучается локальным шаблонам — четким границам и текстурам, которые помогают различать соседние ткани. В средних стадиях модуль на основе так называемых моделей состояния пространства, адаптированный из недавней архитектуры Mamba, передаёт информацию по последовательностям признаков изображения так, чтобы быть контекстно‑осведомлённым и при этом вычислительно экономным. Глубже в сети блоки Transformer, усиленные вниманием HiLo, разделяют информацию на высокочастотные и низкочастотные компоненты, что позволяет модели уловить как мельчайшие детали, так и общие формы органов, прежде чем снова их объединить. Такая многослойная схема отражает естественный переход от сырых пикселей к абстрактному смыслу при обработке изображений.
Как работает новая модель внутри
На практике CMT-Unet следует знакомой U-образной структуре, популярной в медицинской визуализации: кодировщик сжимает информацию в более богатые признаки, декодер восстанавливает предсказание в исходном размере, а пропуски (skip connections) передают пространственные детали. Ключевое отличие — какие модули используются на каждой глубине. Ранний сверточный блок обрабатывает мелкомасштабную структуру, которую блоки Mamba и Transformer могли бы размыть. Модифицированный блок MambaVision улучшает контекст среднего радиуса, смешивая пространственную информацию через специально разработанные двумерные операции, избегая высокой стоимости полного внимания и при этом охватывая область шире локальных патчей. HiLo‑внимание на этапе Transformer явно разделяет острые края и гладкие фоновые паттерны, комбинируя их таким образом, чтобы сохранять границы. Наконец, двойной модуль апсемплинга в декодере помогает восстановить чистые, непрерывные контуры и одновременно уменьшить типичные артефакты, такие как шахматный узор.
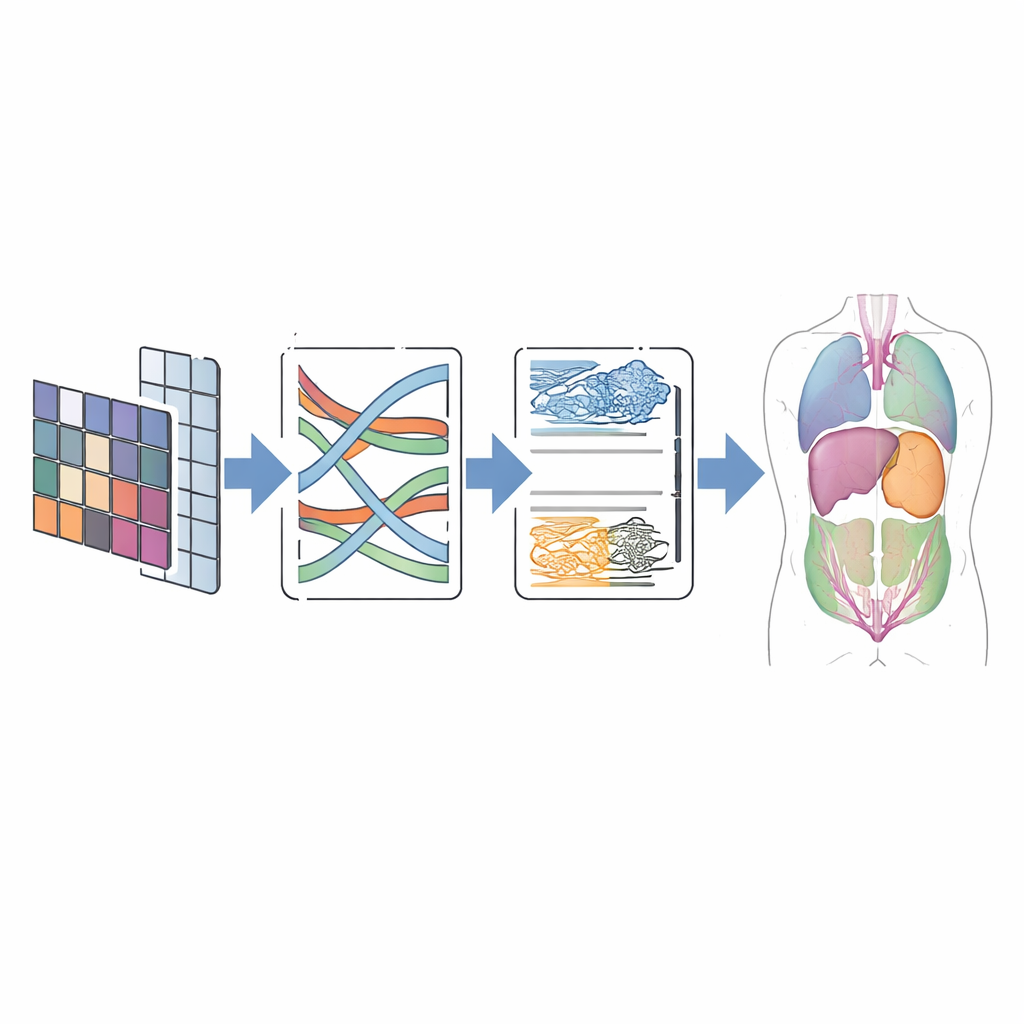
Тестирование на реальных снимках
Чтобы оценить, оправдывает ли это дизайн себя, авторы протестировали CMT-Unet на двух широко используемых публичных наборах данных. Первый, Synapse, содержит абдоминальные КТ‑сканы с разметкой восьми органов, включая печень, почки и желудок. Второй, ACDC, включает кардиальные МРТ‑изображения с метками камер сердца и миокарда. По этим бенчмаркам CMT-Unet показал показатели сегментации сопоставимые или лучшие по сравнению с ведущими сверточными, Transformer‑ и гибридными моделями, при умеренном числе параметров и сопоставимом объёме вычислений. Визуальные сравнения продемонстрировали более плавные и анатомически согласованные границы, особенно в сложных областях, таких как камеры сердца, что важно для оценки функции и планирования вмешательств.
Что это значит для пациентов и клиник
Для неспециалистов главный вывод в том, что CMT-Unet предлагает более умный способ обводить структуры на медицинских изображениях, тщательно подбирая подходящий инструмент для каждой стадии обработки. Балансируя локальную детализацию и глобальный контекст, модель способна выдавать точные, чистые контуры органов без необходимости суперкомпьютерных ресурсов. Хотя в текущей работе акцент сделан на двухмерных снимках и ограниченном наборе публичных данных, подход обещает перспективы для дальнейшего расширения на трёхмерную визуализацию и более широкие клинические сценарии. При дополнительной валидации такие лёгкие и точные методы сегментации могли бы ускорить диагностику, повысить надёжность планирования лечения и обеспечить оперативную поддержку в загруженных больничных условиях.
Цитирование: Wang, R., Liu, H. & Wang, G. CMT-Unet: leveraging stage-wise hybrid framework for enhanced accuracy and efficiency in medical image segmentation. Sci Rep 16, 10079 (2026). https://doi.org/10.1038/s41598-026-40572-w
Ключевые слова: сегментация медицинских изображений, глубокое обучение, гибридные нейронные сети, модели состояния пространства, медицинская визуализация