Clear Sky Science · ru
Метод машинного обучения на основе kNN для автоматизации оценки причинно‑следственной связи неблагоприятных явлений
Почему это важно для людей, принимающих лекарства
Когда новое лекарство выходит на рынок, его история только начинается. Миллионы людей будут использовать его в реальной практике, и у некоторых появятся проблемы со здоровьем, которые могут быть связаны с препаратом или иметь другое происхождение. Выявление реакций, действительно связанных с лекарством, жизненно важно для безопасности пациентов, но сейчас эта работа выполняется медленно, сложно и в значительной мере вручную. В этом исследовании изучается, как простая, но эффективная форма искусственного интеллекта может помочь экспертам быстрее и более последовательно анализировать сообщения о безопасности, не заменяя при этом человеческое суждение, которое в конечном счёте защищает пациентов.
Как истории о безопасности превращаются в данные
Фармакопроизводители и регуляторы опираются на индивидуальные отчёты о безопасности случаев, которые представляют собой структурированные краткие описания реального опыта людей с лекарствами. Каждый отчёт может включать, что пошло не так (например, головная боль или проблемы с печенью), насколько серьёзно это было, какие другие лекарства и заболевания имелись, и какое мнение исходный рецензент высказал о связи с препаратом. Для более чем 800 000 таких отчётов по шести реализованным препаратам медицинские рецензенты компании уже решили, связано ли каждое нежелательное явление с лекарством, не связано или невозможно оценить из‑за нехватки или противоречивости информации. Исследователи использовали этот богатый исторический массив в качестве обучающего материала для компьютерной модели, которая должна была научиться воспроизводить эти человеческие решения для новых случаев.

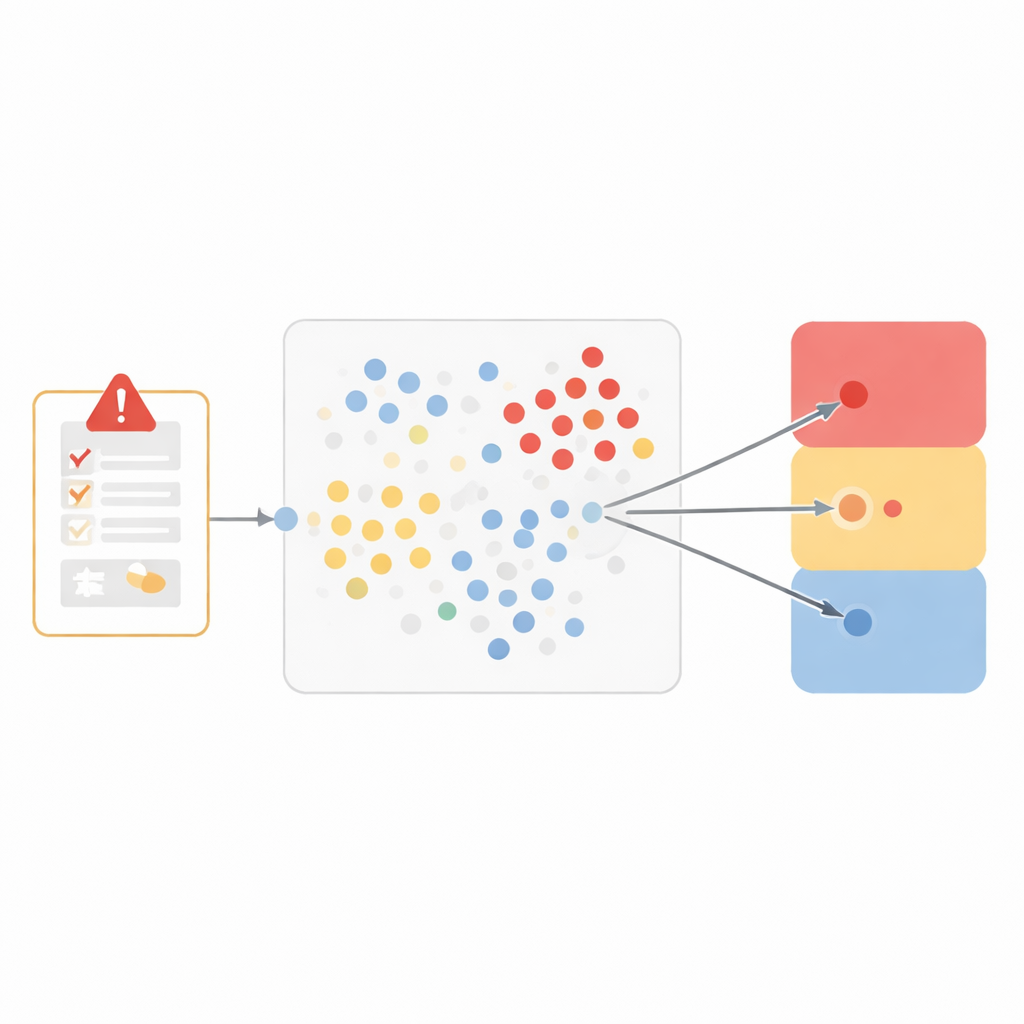
Обучение компьютера распознаванию похожих случаев
Вместо создания чёрного ящика команда выбрала особенно прозрачный метод, называемый «ближайшие соседи». Идея интуитивна: если два случая выглядят очень похоже, то, вероятно, они приводят к одинаковому выводу о том, вызвало ли проблему лекарство. Чтобы зафиксировать похожесть, исследователи представили каждое нежелательное явление в виде семичастного профиля, включающего медицинский термин явления, что происходило при отмене и возобновлении препарата, ожидалось ли такое для данного лекарства, мнение докладчика, другие принимаемые лекарства, анамнез и степень серьёзности события. Затем они измеряли близость любых двух случаев в этом семимерном пространстве, давая больший вес признакам, наиболее важным для причинности, таким как точное событие и то, что происходило при изменении лечения.
От близости к трёхвариантному решению
Когда поступает новый отчёт, модель просматривает исторические данные и находит десять наиболее похожих случаев. Затем она проверяет, как эти соседи были классифицированы, и позволяет им «проголосовать» среди трёх широких исходов: вероятно связано с лекарством, не связано или маловероятно, и невозможно оценить. Такое трёхвариантное разделение балансирует клинические тонкости и надёжность работы. При тестировании на более чем 250 000 ранее не встречавшихся событий модель близко соответствовала решениям человеческих рецензентов для случаев, считавшихся связанными, и для тех, что признаны неоценимыми, с низкими уровнями ошибок и высокими показателями, сочетающими точность и полноту. Больше трудностей возникало с меньшей группой явно несвязанных событий, что отражает проблему, с которой сталкиваются системы машинного обучения при редкой встречаемости одного типа примеров.
Снижение тумана «нельзя сказать»
Практическая проблема в реальной работе по безопасности в том, что метка «неоценимо» может стать универсальным ярлыком, когда информации мало или она неоднозначна, что затрудняет выявление истинных паттернов безопасности. Исследователи добавили инструмент настройки, который делает модель более осторожной при присвоении этой метки. Вместо того чтобы выбирать «неоценимо», когда оно получает простое большинство среди похожих случаев, модель теперь требует более высокого процента поддерживающих соседей для такого выбора. Повышая этот порог, команда смогла резко сократить частоту присвоения метки «неоценимо» и улучшить работу по двум другим категориям, ценой некоторого увеличения расхождений для самых трудных для оценки случаев. Веб‑панель управления позволяет медицинским рецензентам регулировать этот порог по продукту, мгновенно видеть, как смещается баланс исходов, и сосредоточить внимание на случаях, где модель и люди расходятся.
Что это значит для будущей безопасности лекарств
Для выборки недавних случаев, которые человеческие рецензенты пометили как неоценимые, система выделила сотни, где её вывод отличался. Когда старшие рецензенты пересмотрели эти случаи, они согласились с моделью более чем в двух третях случаев, что показывает: такие инструменты могут выявлять пропущенные закономерности и поддерживать контроль качества, а не заменять экспертов. Работа демонстрирует, что прозрачный подход на основе похожести может внедрить искусственный интеллект в фармаконадзор таким образом, чтобы он был объяснимым, настраиваемым и согласованным с медицинской практикой. По мере накопления данных и добавления текстовых описаний с помощью современных языковых технологий подобные системы могут помочь обнаруживать возникающие риски раньше, сохраняя за клиницистами окончательное решение.
Цитирование: Ren, J., Carroll, H., McCarthy, K. et al. A kNN based machine learning approach to automating causality assessment of adverse events. Sci Rep 16, 9140 (2026). https://doi.org/10.1038/s41598-026-40267-2
Ключевые слова: фармаконадзор, нежелательные реакции на лекарства, оценка причинности, машинное обучение, k ближайших соседей