Clear Sky Science · ru
Стратегии ансамблевого машинного обучения для картирования перспективности минералов при дефиците данных
Поиск руды по малому количеству подсказок
Современное общество зависит от металлов, таких как свинец и цинк, для батарей, электроники и инфраструктуры, но самые простые месторождения уже обнаружены. В новых регионах у геологов часто есть лишь несколько подтверждённых находок, разрозненные химические пробы и фрагментарные карты. В этом исследовании показано, как использовать машинное обучение не для получения наивысшего балла на исторических данных, а для выдачи предсказаний, которым лица, принимающие решения, действительно могут доверять при нехватке информации.
Почему в реальном мире данных мало
Картирование перспективности минералов ставит целью выделить участки ландшафта, где с большей вероятностью может встречаться руда. Оно объединяет слои информации — типы пород, разломы, спутниковые снимки и химический состав донных отложений — в карту вероятностей, которая направляет полевые работы и бурение. На ранних стадиях проекта, однако, известно лишь несколько месторождений, и многие участки вообще не отбирались проб. Стандартные инструменты машинного обучения хорошо работают на больших, хорошо размеченных наборах данных; столкнувшись с всего несколькими десятками положительных примеров, они могут стать нестабильными и чрезмерно уверенными, выдавая числовые оценки, которые выглядят точными, но слабо связаны с реальностью.
Преобразование редких подсказок в практичные сигналы
Авторы работали в районе свинцово‑цинкового месторождения Дехак в центральном Иране, где минерализация связана с определёнными известняковыми слоями, разломами и зонами химической изменённости. Они создали цифровые карты пород‑хозяев, плотности трещиноватости и альтерации на основе геологических съёмок и спутниковых снимков и выделили геохимические аномалии из 624 проб наносов. Из этого богатого, но неравномерного набора данных они выделили всего 108 размеченных точек: 27 с известными месторождениями и 81 без. Чтобы избежать подавления редких примеров руд меньшинством отрицательных классов, использовали приём, создающий реалистичные синтетические точки месторождений путём интерполяции между существующими — выравнивая классы только в тренировочных данных. Это обеспечило более сбалансированный набор примеров при сохранении отдельных валидационных и тестовых выборок, отражающих реальную редкость. 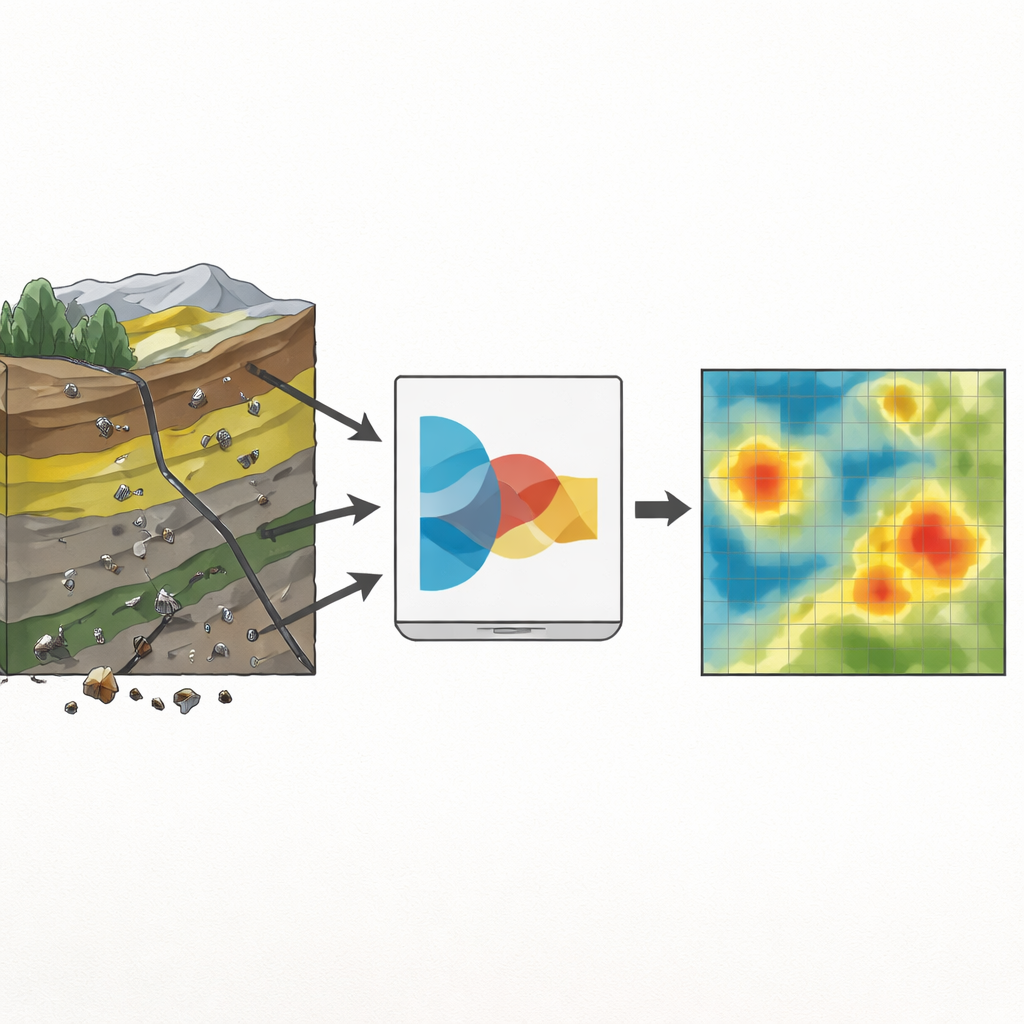
Сборка команд моделей вместо ставить на одну
Вместо опоры на один алгоритм, исследование сочетало методы с разными сильными сторонами. Один ансамбль объединял метод опорных векторов, который проводит максимально резкую границу между классами, с простым вероятностным методом, называемым гауссовским наивным байесом. Другой смешивал два дерево‑ориентированных метода — LightGBM и AdaBoost — которые хорошо улавливают сложные закономерности при большом числе переменных. В обоих случаях финальное предсказание было усреднением оценок вероятности компонентов — стратегия, часто уменьшающая резкие колебания в работе. Критично, что авторы сравнивали не только частоту правильных ответов моделей, но и то, насколько хорошо предсказанные вероятности соответствуют наблюдаемой реальности — свойство, известное как калибровка.
Настройка ради доверия, а не только ради балла
Выбор параметров модели — насколько сильно она наказывает ошибки, сколько деревьев строит и так далее — может радикально изменить её поведение. Команда протестировала три распространённые стратегии настройки: Grid Search, который систематически перебирает фиксированный набор опций; Random Search, который случайно выбирает комбинации; и байесовскую оптимизацию, которая использует предыдущие испытания для предсказания перспективных вариантов. Формально байесовская оптимизация дала наивысший показатель дискриминации (ROC–AUC 0,95) для ансамбля на основе метода опорных векторов. Однако при анализе кривых калибровки, сравнивающих предсказанные вероятности с фактическими исходами, версии обоих ансамблей, настроенные Grid Search, показали более плавные и стабильные результаты, особенно в диапазоне средних вероятностей, где обычно устанавливают пороги для разведки. 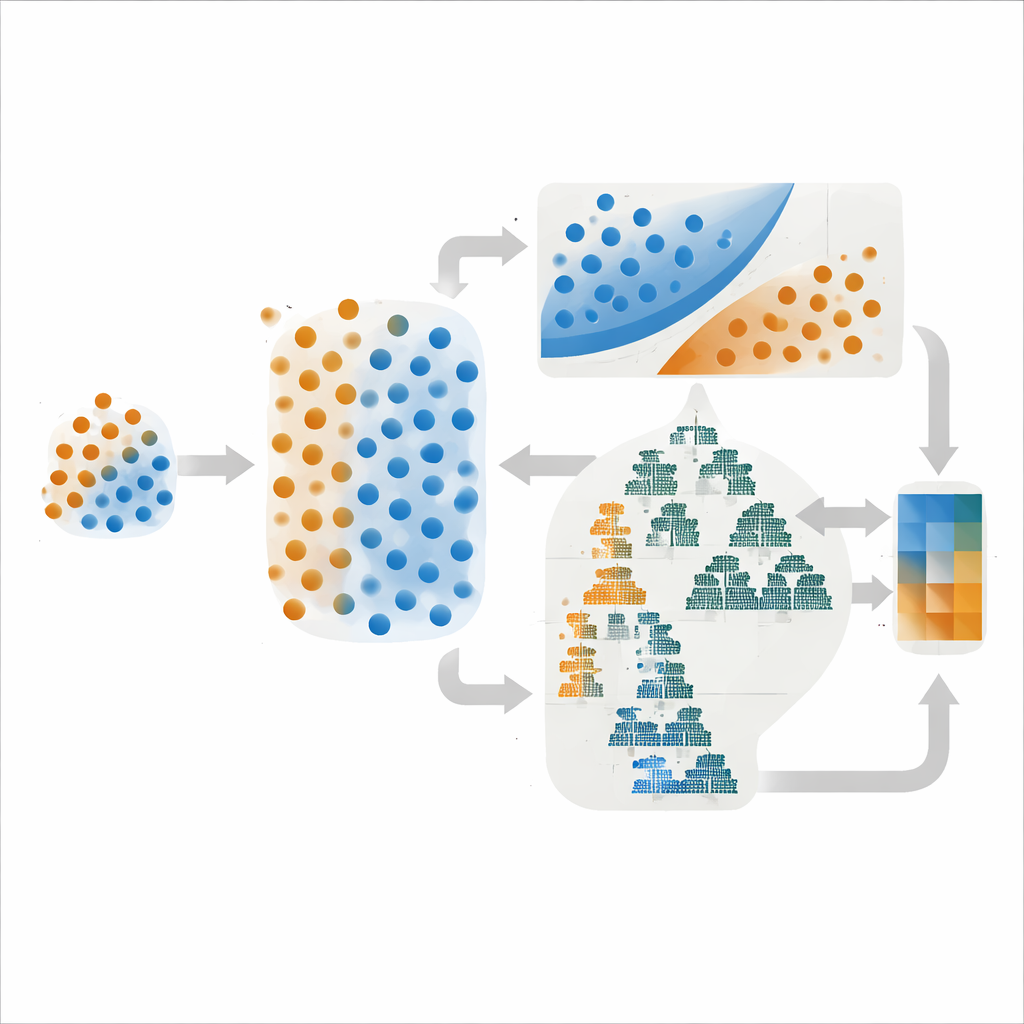
От чисел к полевым решениям
Для ранней разведки, где каждая скважина обходится дорого, авторы утверждают, что правильно ведущее себя распределение вероятностей важнее, чем выигрыш в точности. Их наиболее практическая рекомендация — более простой ансамбль «опорные векторы + байес», настроенный с помощью Grid Search. Он обеспечивает высокую дискриминацию, при этом даёт наиболее надёжную связь между значениями вероятностей и реальными показателями обнаружений, что позволяет геологам устанавливать пороги в соответствии с их уровнем риска. По мере развития проектов и накопления данных можно вводить более сложные деревообразные модели, такие как ансамбль LightGBM, для уточнения предсказаний, но всегда с вниманием к калибровке. Так машинное обучение перестаёт быть чёрным ящиком и превращается в прозрачного партнёра при принятии решений с учётом риска о том, где искать следующий поколение минеральных ресурсов.
Цитирование: Amirajlo, P., Hassani, H., Pour, A.B. et al. Ensemble machine learning strategies for mineral prospectivity mapping under data scarcity. Sci Rep 16, 9171 (2026). https://doi.org/10.1038/s41598-026-40125-1
Ключевые слова: картирование перспективности минералов, ансамблевое машинное обучение, недостаток данных, калибровка модели, разведка полезных ископаемых