Clear Sky Science · ru
KM-DBSCAN: усовершенствованная система обнаружения границ на основе плотности и центроидов для сокращения данных в пользу «зелёного» ИИ
Почему уменьшение ИИ может сделать его экологичнее
Искусственный интеллект имеет скрытую цену: электричество. Обучение современных моделей машинного обучения часто требует обработки миллионов данных на энергоёмком оборудовании, что в свою очередь порождает выбросы углерода. В этой статье предлагается KM-DBSCAN — новый способ уменьшить объёмы данных перед обучением, не выбрасывая при этом информацию, действительно важную для моделей. Сохраняя только наиболее информативные примеры, метод ускоряет обучение, сокращает потребление энергии и при этом обеспечивает точные прогнозы для задач от распознавания рукописных цифр до раннего выявления рака кожи.
Слишком много данных, слишком много энергии
В течение многих лет господствовало мнение, что больше данных почти всегда даёт лучшие модели. Хотя это может повысить точность, это также означает более длительное обучение, более мощные машины и более высокие счета за электричество. Исследователи начали различать «красный ИИ», который стремится к максимальной точности любой ценой, и «зелёный ИИ», который пытается сбалансировать качество и экологический след. Одно многообещающее направление в сторону более экологичного ИИ — сокращение данных: вместо того чтобы кормить модель всеми доступными примерами, выделить куда меньший набор случаев, который всё ещё хорошо определяет задачу, особенно трудные пограничные случаи, определяющие решения классификатора.
Сочетание двух простых идей в один умный фильтр
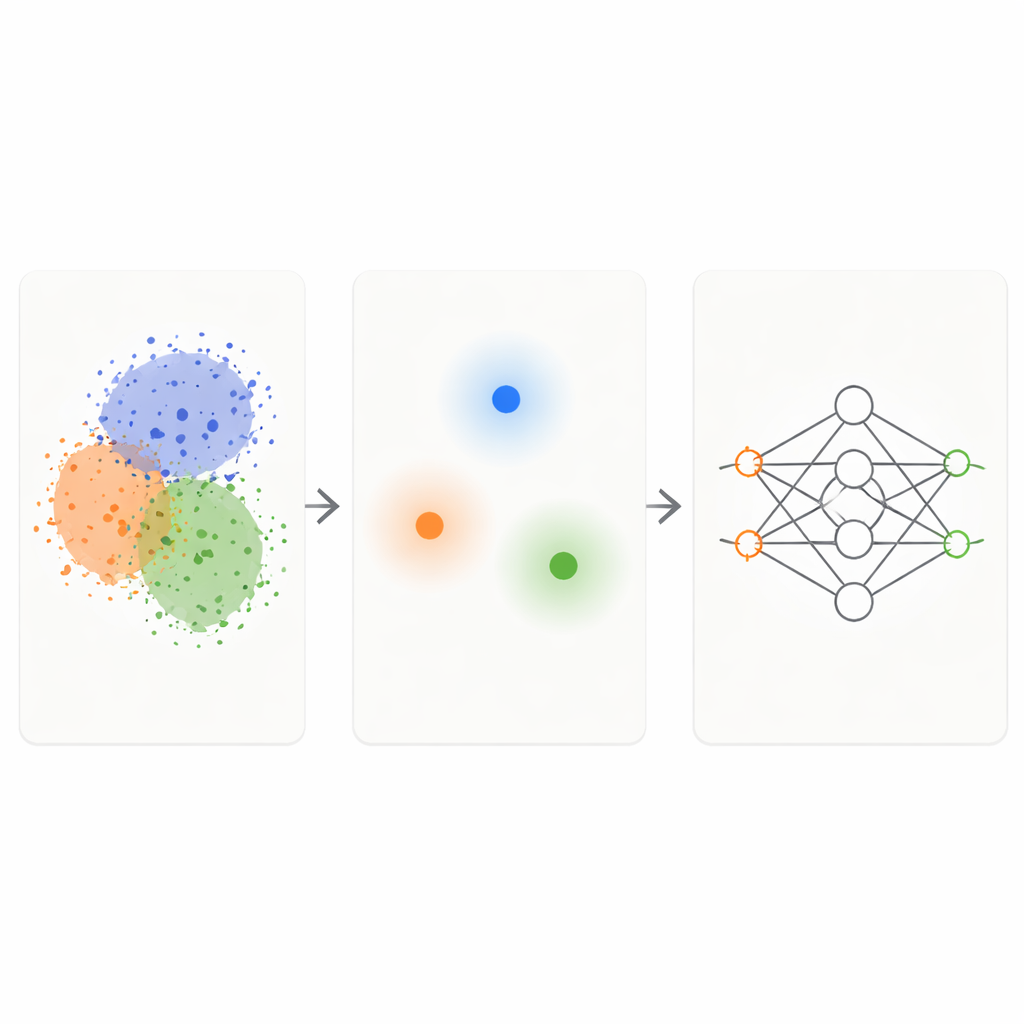
Фреймворк KM-DBSCAN объединяет две хорошо известные техники кластеризации, чтобы выступать в роли интеллектуального фильтра для исходных данных. Сначала быстрый метод K-Means группирует точки в компактные кластеры и заменяет каждую группу представительным центром, или центроидом. Это уменьшает задачу с тысяч или миллионов точек до нескольких сотен репрезентативных. Затем на этих центроидах применяется метод, основанный на плотности (DBSCAN), чтобы определить, какие области лежат на границах между кластерами, а какие — плотные однородные внутренние области или изолированный шум. Работая на уровне центроидов, DBSCAN становится гораздо быстрее и менее чувствительным к тонким настройкам параметров, чем при применении ко всем исходным точкам.

Оставляя только сложные, информативные случаи
Когда KM-DBSCAN определяет, где разные группы соприкасаются или перекрываются, он сохраняет только те точки данных, которые находятся близко к этим границам, и отбрасывает как глубоко внутренние точки, так и явные выбросы. Внутренние точки в значительной степени избыточны: они все выглядят похоже и посылают модели одинаковую информацию о своём классе. Граничные точки, напротив, указывают модели, где один класс заканчивается и начинается другой. На синтетических учебных наборах такая стратегия восстанавливает те же границы решений, которые классификатор выучивает по полным данным, даже когда большинство точек удалено. На реальных наборах данных, таких как Banana, USPS digits, набор доходов Adult, данные о ДТП, разновидности сухих бобов и изображения меланомы, сокращённые множества сохраняют ключевую структуру задачи, оставаясь при этом на порядок меньше.
Скорость, экономия углерода и реальные применения
Авторы проверили KM-DBSCAN в качестве предобработки для нескольких популярных моделей, включая опорные векторные машины, многослойные перцептроны и сверточные нейронные сети. Во многих случаях обучение на сокращённых данных оказалось в десятки и тысячи раз быстрее при почти той же точности — а иногда даже с небольшим улучшением. Например, в распознавании рукописных цифр метод сократил обучающий набор до всего 1,4% от исходного объёма и при этом слегка повысил точность, делая обучение в 284 раза быстрее. В задаче прогнозирования дохода с несбалансированными классами был достигнут ускорение в 6907 раз, используя лишь около 3% данных с минимальной потерей точности. В эксперименте по обнаружению меланомы глубокая нейросеть достигла более 90% точности, обучаясь на менее чем трети исходного набора изображений кожи, при этом выбросы углерода были снижены более чем на 70%.
Что это значит для повседневного ИИ
Для неспециалистов ключевое послание в том, что умный отбор может превзойти простое увеличение объёма. KM-DBSCAN показывает: тщательный выбор примеров, которые видит модель — с фокусом на наиболее информативных пограничных случаях — может резко сократить время вычислений и потребление энергии, сохранив надёжность прогнозов. Такой подход органично вписывается в более широкую инициативу по созданию «зелёного» ИИ, где качество данных и продуманная архитектура конвейеров обучения важны не меньше, чем размер модели. При широком применении такие фильтры, учитывающие структуру данных, могут сделать анализ медицинских изображений, системы безопасности дорожного движения и другие области более устойчивыми, предоставив мощные инструменты ИИ организациям, не располагающим массивными вычислительными ресурсами.
Цитирование: AboElsaad, M.Y., Farouk, M. & Khater, H.A. KM-DBSCAN: an enhanced density and centroid based border detection framework for data reduction towards green AI. Sci Rep 16, 10349 (2026). https://doi.org/10.1038/s41598-026-40062-z
Ключевые слова: зелёный ИИ, сокращение данных, кластеризация, эффективность машинного обучения, обнаружение меланомы