Clear Sky Science · ru
Усиление разреженности источникового сигнала на основе алгоритма локальной синхронной экстракции максимумов для оценки смешанной матрицы в UBSS
Распутывание скрытых сигналов
Многие технологии, на которые мы полагаемся — беспроводные сети, радары, медицинские сканеры и даже умные микрофоны — должны выделять слабые сигналы, которые бесповоротно смешаны. Представьте, что вы пытаетесь следить за несколькими разговорами одновременно в шумном кафе, имея лишь два уха. В статье предлагается новый способ «распутывать» такие перекрывающиеся сигналы, когда датчиков меньше, чем источников — особенно сложная задача. За счёт более чёткого представления сигналов во времени и частоте и улучшения методов группировки связанных данных авторы показывают, что можно разделять смеси точнее и надёжнее, даже в зашумлённых реальных условиях. 
Почему смешанные сигналы так трудно разделить
Во многих системах несколько независимых сигналов проходят по одному каналу и захватываются небольшим числом приёмников. Такая ситуация, называемая недоопределённым слепым разложением источников, означает, что неизвестных сигналов больше, чем измерений. Классические методы разложения обычно предполагают обратное, поэтому здесь они не работают. Один современный приём — использовать разреженность: в подходящем представлении каждый источник активен лишь в нескольких моментах времени или на отдельных частотах. Если в большинстве моментов доминирует не более одного источника, облако наблюдаемых данных естественно образует кластеры, направления которых кодируют, как каждый источник смешивается в приёмниках. Точное обнаружение этих кластеров, однако, зависит от наличия представления, в котором энергия каждого источника сосредоточена, а не размыта.
Уточнение картины сигнала
Чтобы выявить разреженность, инженеры часто переводят сигналы в временно-частотную картину, показывающую, какие тоны присутствуют в какие моменты. Простой коротковременный преобразователь Фурье делает это, сдвигая окно по времени и беря много небольших спектров, но он размывает энергию и не может одновременно дать точную временную локализацию и точную частоту. Более продвинутые варианты, такие как синхросжимание и синхроэкстракция, пытаются подтянуть растёкшуюся энергию к гребню, соответствующему мгновенной частоте сигнала. Эти методы улучшают фокусировку, но остаются уязвимыми к шуму: когда случайные помехи сжимаются вдоль тех же гребней, что и сигнал, в результате получается яркая, но расплывчатая полоса, скрывающая тонкую структуру.
Поиск локальных пиков для усиления разреженности
Опираясь на эти идеи, авторы вводят алгоритм локальной синхроэкстракции максимумов (Local Maximum Synchroextracting Transform, LMSET). Вместо того чтобы перемещать всю соседнюю энергию к частотному гребню, LMSET сканирует временно-частотную плоскость и для каждого момента фиксируется на локальных пиках вдоль оси частоты. Сохраняются и переназначаются только коэффициенты вокруг этих локальных максимумов, а остальные подавляются. Это простое изменение даёт представление, в котором энергия каждого компонентного сигнала концентрируется в тонкие, чистые кривые с гораздо меньшим числом разбросанных точек. По симуляциям с многокомпонентными тестовыми сигналами LMSET даёт наименьшую энтропию Реньи — стандартную меру концентрации — превосходя как традиционные, так и современные методы в широком диапазоне уровней шума. Проще говоря, LMSET даёт более чёткое представление о том, где каждый сигнал располагается во времени и частоте.
Более умная группировка для вывода скрытого смешения
Острота картины — лишь половина успеха; следующий шаг — сгруппировать полученные точки, чтобы оценить неизвестную матрицу смешения, описывающую вклад каждого источника в каждый приёмник. Многие подходы опираются на нечеткий C-means, популярный метод кластеризации, который часто «застревает» в плохих решениях из‑за сильной чувствительности к начальному приближению и выбросам. Чтобы преодолеть эти недостатки, авторы сочетают LMSET с новой, более устойчивой схемой кластеризации. Сначала они используют PID-основанный поисковый алгоритм, вдохновлённый теорией управления, чтобы исследовать всё пространство возможных центров кластеров и избежать плохих стартовых позиций. Затем вводят булев механизм взвешивания, чтобы приуменьшать влияние выбросов, и применяют стратегию на основе информационной энтропии, снижающую чувствительность к начальным условиям. В совокупности эти шаги позволяют кластеризации более последовательно сходиться к истинным направлениям скрытых источников.
Что показали тесты
Авторы проверяют полный конвейер — LMSET вместе с улучшенной кластеризацией — на смесях цифровых модулированных коммуникационных сигналов, включая QAM, QPSK и FSK, в тихой и зашумлённой средах. Они сравнивают оценённые матрицы смешения с истинными, используя угловую погрешность и нормализованную среднеквадратичную ошибку. Повсеместно использование LMSET вместо традиционного преобразования снижает ошибки, потому что точки данных формируют более плотные и отчётливые кластеры. Среди методов кластеризации предложенный PID-оптимизированный робастный нечеткий C-means показывает наименьшие средние угловые отклонения и лучшие показатели ошибок. В целом комбинированный метод улучшает точность оценки матрицы смешения почти на 20 процентов по сравнению с традиционными подходами и сохраняет высокую эффективность даже при больших уровнях шума. 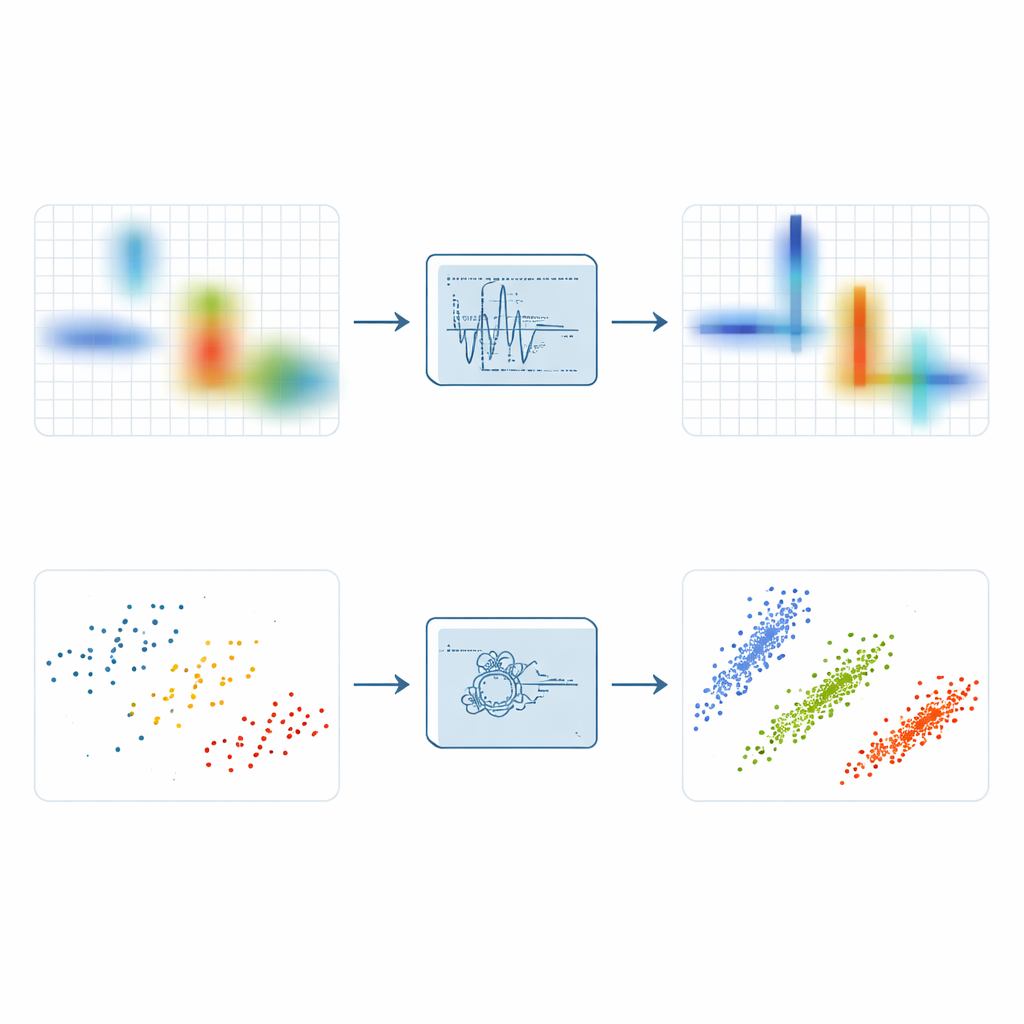
Почему это важно за пределами теории
Для неспециалистов ключевая мысль такова: авторы предложили лучший способ смотреть на переплетённые сигналы и группировать их, чтобы каждый исходный поток можно было восстановить более чисто. Сосредоточившись на локальных пиках во временно-частотном ландшафте и сочетая это представление с более тщательной стратегией кластеризации, их метод делает «задачу кафе» — много голосов и слишком мало ушей — более решаемой. Это достижение может принести пользу приложениям от спутниковых каналов, где нужно разделять перекрывающиеся передачи, до медицинских систем, которым требуется выделить слабые биологические сигналы, скрытые в шуме, обеспечивая более ясную информацию при тех же ограниченных измерениях.
Цитирование: Li, X., Li, Z., Yao, R. et al. Source signal sparsity enhancement based on local maximum synchronous extraction transform algorithm for mixed matrix estimation in UBSS. Sci Rep 16, 9378 (2026). https://doi.org/10.1038/s41598-026-40055-y
Ключевые слова: слепое разложение источников, разреженность сигнала, временнo–частотный анализ, алгоритмы кластеризации, беспроводная связь