Clear Sky Science · ru
Де-ново генерация и in silico скрининг кандидатов антидиабетических пептидов с помощью глубокого обучения и внимания с объединением физико-химических признаков
Почему более умный дизайн пептидов важен при диабете
Диабет затрагивает сотни миллионов людей по всему миру, и существующие препараты не работают идеально для всех. Многие методы со временем теряют эффективность или вызывают побочные эффекты. Обещающим новым вариантом являются небольшие белки — антидиабетические пептиды, которые способны тонко регулировать уровень сахара в крови. Проблема в том, что поиск новых пептидных лекарств в лаборатории медленный и дорогой. В этом исследовании представлен компьютерный конвейер, который может придумывать и отбирать большое количество потенциальных антидиабетических пептидов, указывая исследователям наиболее перспективные кандидаты для реального тестирования.
От известных диабетических пептидов к чистым исходным данным
Исследователи начали с составления высококачественной коллекции пептидов, экспериментально показавших влияние на уровень сахара, в основном через гормоны вроде GLP-1 или ферменты типа DPP-IV. Эти примеры составили «положительный» набор. Затем они собрали соответствующий «отрицательный» набор пептидов без зарегистрированной антидиабетической активности, тщательно подобранный так, чтобы по длине, составу и базовой химии он напоминал положительные образцы. Чтобы не вводить модель в заблуждение почти идентичными последовательностями, они использовали инструменты сравнения последовательностей, чтобы убедиться, что близкородственные пептиды никогда не попадали одновременно в тренировочную и тестовую группы. Такое разделение с учётом гомологии гарантировало, что систему будут оценивать по способности распознавать действительно новые закономерности, а не по способности запоминать старые.
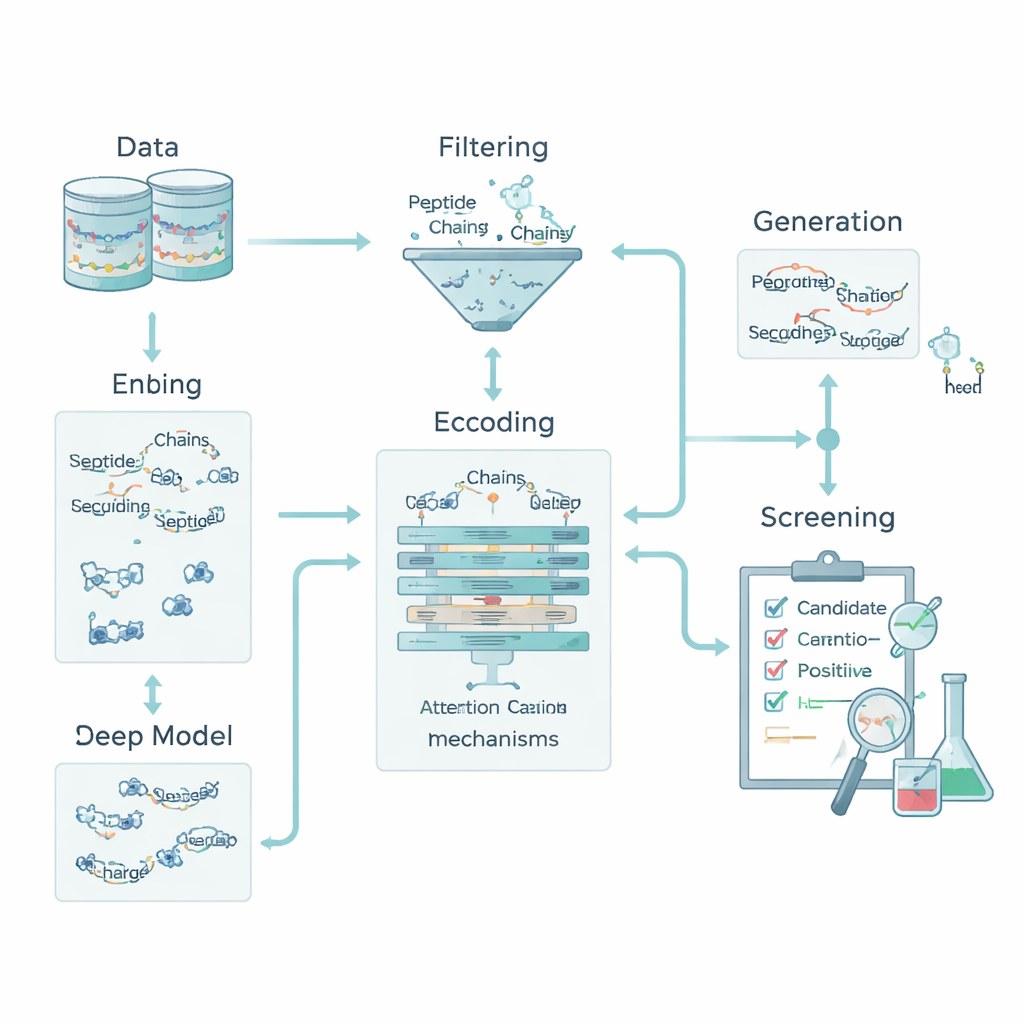
Кодирование химии, чтобы машины «читали» пептиды
Для компьютера пептид — это просто строка букв, обозначающих аминокислоты. Чтобы связать эти буквы с биологией, команда преобразовала каждую аминокислоту в пять базовых химических признаков: гидрофобность (насколько она отталкивает воду), электрический заряд, склонность к образованию водородных связей, массу и наличие ароматического кольца. Это превратило каждый пептид в небольшое «изображение», которое фиксирует и порядок, и химию. Кроме того, они добавили дескрипторы для всего пептида — общий заряд, среднюю гидрофобность и индекс Богмана (Boman index), связанный со склонностью пептида связываться с другими белками. В совокупности эти признаки позволили модели учитывать как локальные паттерны — короткие мотивы аминокислот, так и глобальные свойства, влияющие на поведение пептида в организме.
Двигатель глубокого обучения, который объясняет свои решения
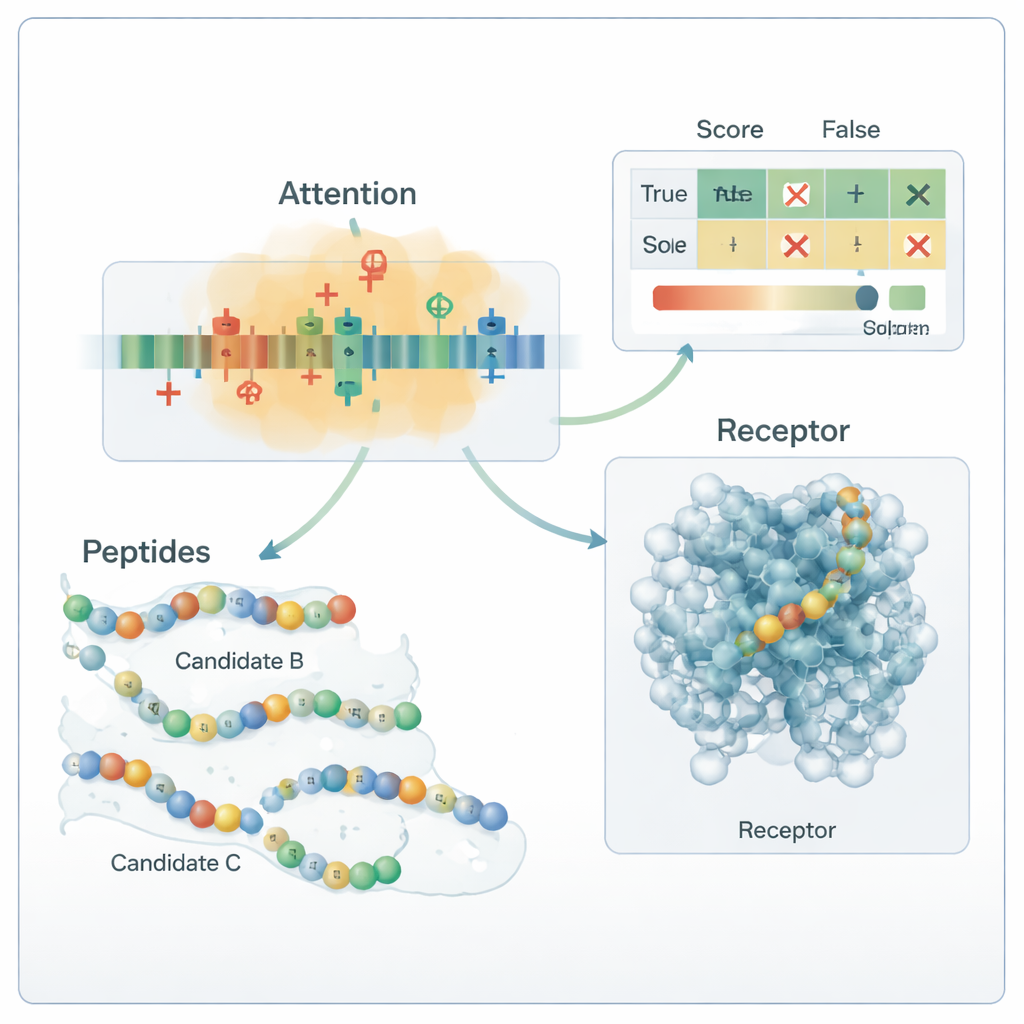
Ядро конвейера — гибридная модель глубокого обучения. Свёрточная нейронная сеть (CNN) сканирует пептид в поисках коротких мотивов, характерных для активных пептидов, подобно фильтрам в системах распознавания изображений. Поверх этого слой внимания (attention) обучается определять, какие позиции в последовательности важны, улавливая длинно-дистанционные связи между удалёнными остатками. Выход этого последовательностного блока объединяется с глобальными химическими дескрипторами и подаётся в несколько стандартных классификаторов машинного обучения — опорные векторы (SVM), деревья решений, k-ближайших соседей и градиентный бустинг. Специализированный метод оптимизации, названный OptimizedTPE, автоматически подбирает их гиперпараметры, балансируя точность и риск переобучения. Механизм внимания также даёт покомпонентные «карты значимости», помогая учёным увидеть, какие участки пептида влияют на решения модели.
Генерация новых кандидатов с одновременным исключением утечки данных
Чтобы преодолеть малоразмерность известных антидиабетических пептидов, команда добавила стадию генерации, которая используется только в процессе обучения. Они применили сочетание стратегий — управляемые мутации, рекомбинацию мотивов и вариационный автоэнкодер — чтобы предложить новые последовательности, похожие на активные, но не копирующие их. Эти кандидаты затем проходили через строгие «ворота дескрипторов», контролирующие реалистичные заряд, размер и склонность к связыванию, а также внешние инструменты, оценивающие сходство с известными биологически активными пептидами. Только последовательности, прошедшие эти фильтры и остающиеся явно отличными от любых тестовых пептидов, сохранялись как слабомаркированные положительные примеры для обучения; ни один из них никогда не использовался для оценки модели. Такой подход расширил тренировочный набор, сохранив чистоту и отсутствие смещения в тестовой выборке.
Насколько хорошо работает система и что это означает
При проверке на полностью независимой панели из 180 экспериментально изученных пептидов, собранных из недавней литературы, фреймворк правильно классифицировал примерно 99 из 100 последовательностей, с точностью и полнотой около 0,99. На практике это означает, что он редко пропускает настоящий антидиабетический пептид и редко помечает неактивный пептид как перспективный. Анализы карт внимания и тесты с мутациями показали, что модель усвоила химически осмысленные правила: она сильно полагается на положительно заряженные и определённые гидрофобные остатки, известные своей важностью для связывания мишеней, связанных с диабетом. Молекулярные докинг-симуляции дополнительно показали, что некоторые из вновь сгенерированных пептидов могут образовывать правдоподобные контакты с человеческим рецептором GLP-1. Хотя эти прогнозы всё ещё требуют лабораторного подтверждения, исследование демонстрирует воспроизводимый, биологически обоснованный способ исследовать огромное пространство возможных пептидных лекарств и приоритизировать немногих кандидатов, которые с наибольшей вероятностью помогут в управлении диабетом.
Цитирование: Asl, Z.R., Rezaee, K., Ansari, M. et al. De novo generation and in silico screening of anti-diabetic peptide candidates via a deep learning–attention framework with physicochemical feature fusion. Sci Rep 16, 6580 (2026). https://doi.org/10.1038/s41598-026-39985-4
Ключевые слова: антидиабетические пептиды, глубокое обучение, поиск лекарств, дизайн пептидов, рецептор GLP-1