Clear Sky Science · ru
R-GAT: классификация документов о раке с использованием графовой остаточной сети в условиях ограниченных данных
Почему важно сортировать статьи по онкологии
Каждый день учёные публикуют сотни новых исследований по раку — от ранней диагностики до перспективных лекарств. Большая часть этих работ сначала появляется в виде коротких аннотаций — абстрактов. Врачи, исследователи и политики не в состоянии прочитать их все, но пропуск важной статьи может замедлить прогресс. В этом исследовании рассматривается простой, но важный вопрос: можно ли создать быструю и лёгкую компьютерную систему, которая автоматически сортирует аннотации, связанные с онкологией, по типам рака, даже когда доступно лишь небольшое количество размеченных данных и ограничены вычислительные ресурсы?
Более умный способ читать исследования по раку
Авторы сосредоточились на четырёх типах аннотаций из базы PubMed: о раке щитовидной железы, раке толстой кишки, раке лёгкого и более общих биомедицинских темах. Они составили тщательно проверенную коллекцию из 1 875 недавних аннотаций, примерно одинакового размера в каждом из четырёх классов. Такое выравнивание помогает избежать смещения в пользу какого‑то одного типа рака. Перед обучением модели тексты были очищены: слова разбили на токены, исправили орфографию, объединили родственные формы слов и удалили неинформативные термины. Очищенные аннотации затем преобразовали в числовые представления с помощью нескольких стандартных методов, чтобы можно было честно сравнить разные типы моделей.
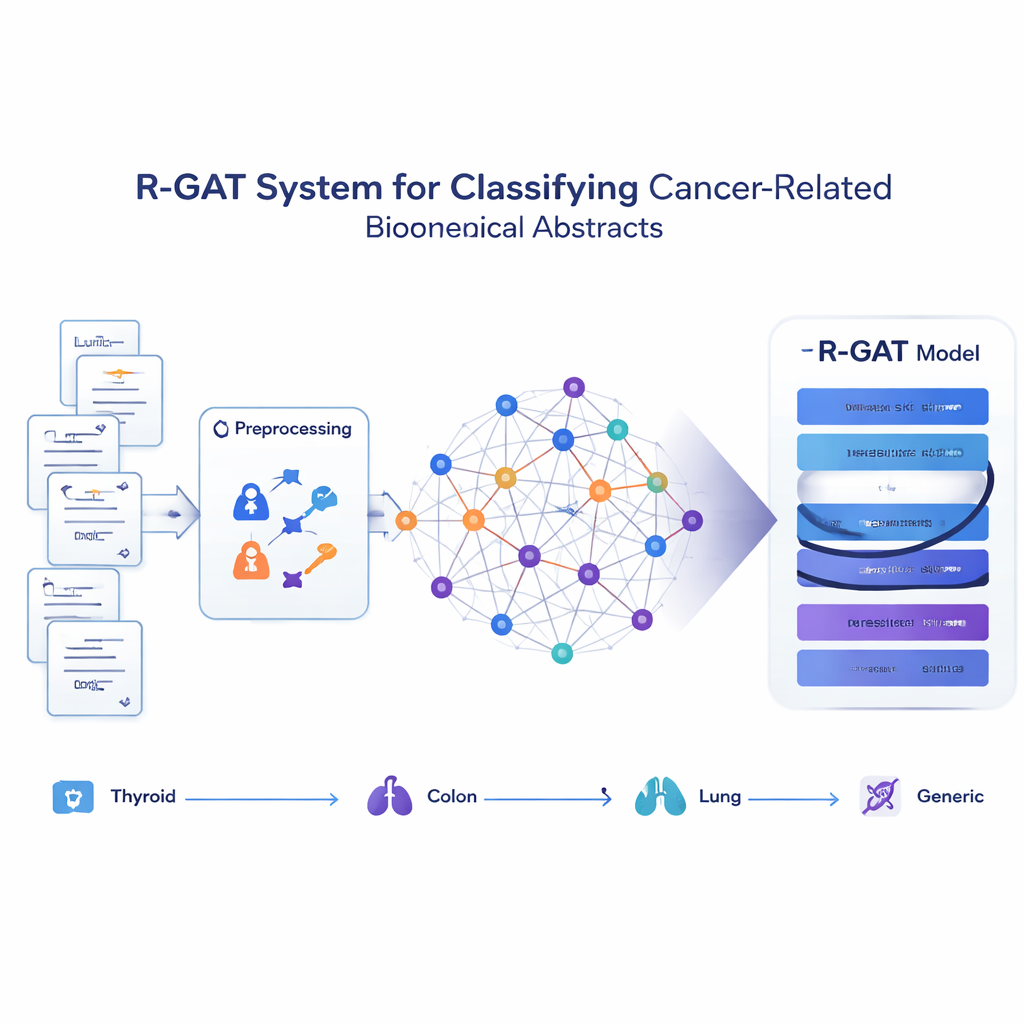
Преобразование статей в сеть идей
Вместо того чтобы рассматривать каждую аннотацию как отдельную строку слов, предложенный метод, названный R-GAT (Residual Graph Attention Network — остаточная графовая сеть внимания), представляет всю коллекцию как сеть. В этой сети каждая аннотация — узел, а связи отражают, насколько похожи по содержанию два абстракта. Если две статьи обсуждают близкие темы, связь между ними сильная; если нет — слабая или отсутствует. Это позволяет модели рассматривать аннотацию в контексте её соседей, имитируя то, как человек может лучше понять одно исследование, зная, что говорится в родственных работах.
Как новая модель учится у соседей
R-GAT опирается на две ключевые идеи современной искусственной интеллекта: механизм внимания и остаточные соединения. Механизм внимания позволяет модели фокусироваться на наиболее релевантных соседних аннотациях в графе, а не относиться ко всем соседям одинаково. Несколько «голов» внимания одновременно ищут разные типы паттернов. Остаточные соединения служат как короткие пути, передающие информацию через более глубокие слои сети, помогая модели не терять важные сигналы в процессе обучения. После обработки графа через несколько слоёв внимания и этих обходных путей система сворачивает информацию из всей сети в компактное представление, которое подаётся в финальный классификатор для предсказания одного из четырёх категорий для каждой аннотации.
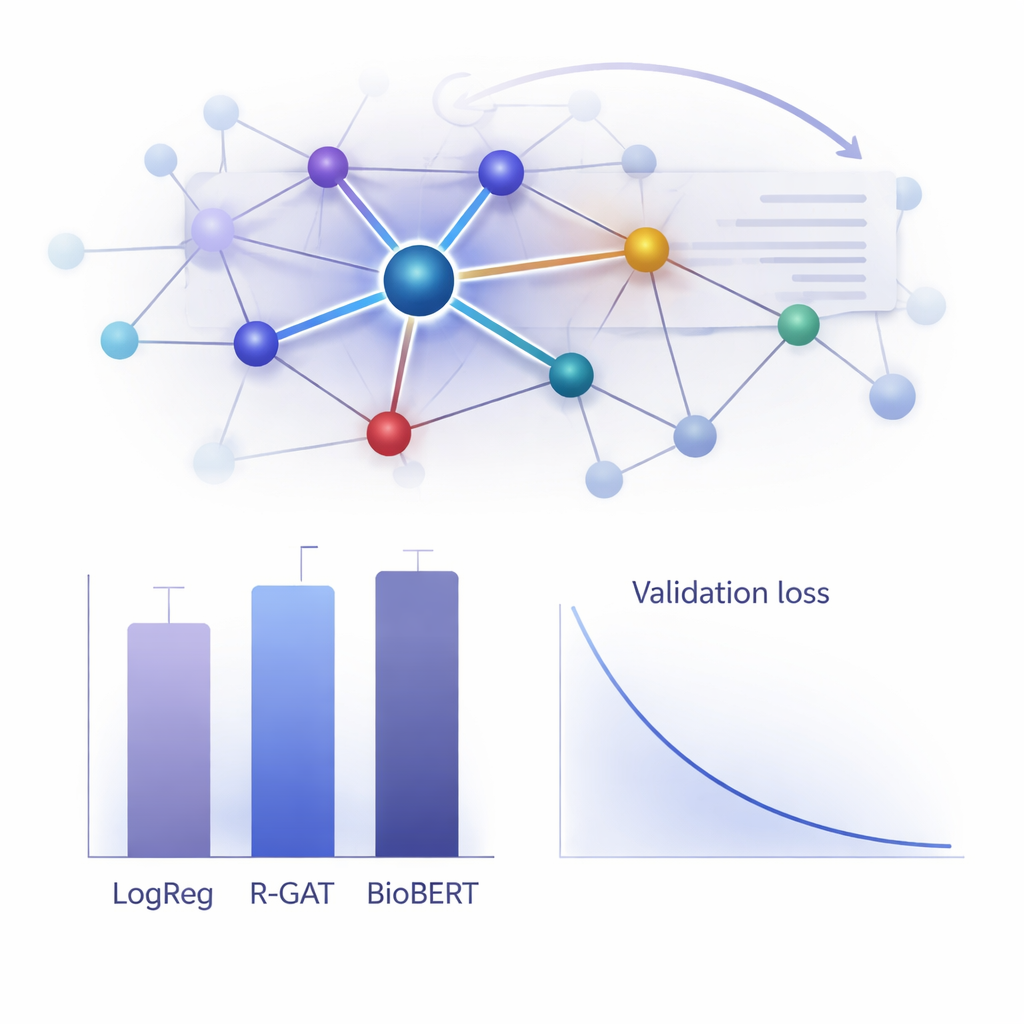
Насколько это работает на практике?
Чтобы оценить полезность R-GAT, авторы сравнили его с широким спектром альтернатив — от классических линейных моделей до современных трансформеров уровня BioBERT, которые популярны, но вычислительно затратны. Удивительно, но простая логистическая регрессия на счётных признаках слов получила наибольший сырый результат на этом конкретном наборе данных, а BioBERT тоже показал очень хорошие результаты — однако у обеих моделей есть недостатки, включая зависимость от выбранных признаков или необходимость значительных вычислительных ресурсов. R-GAT достиг макро F1‑метрики около 0,96, близко к лучшим моделям, при этом демонстрируя очень стабильные результаты на разных разбиениях на обучающую и тестовую выборки. Тщательные тесты, в которых удаляли либо механизм внимания, либо остаточные соединения, показали явное падение качества, что подтверждает важность обеих составляющих для устойчивости модели при ограниченных данных.
Что это значит для будущих исследований рака
Для неспециалиста основная мысль проста: R-GAT — практичный инструмент, который помогает сортировать научные статьи по типу рака с высокой и стабильной точностью, не требуя гигантских наборов данных или дорогого оборудования. Он не заменяет самые мощные языковые модели на рынке, но предлагает надёжный компромисс — особенно полезный для больниц, исследовательских групп или органов общественного здравоохранения, которым нужны воспроизводимые результаты при жёстких ограничениях по данным и бюджету. Публикуя как модель, так и тщательно подобранный набор данных в открытом доступе, авторы также предоставляют эталон, который другие могут использовать для создания и тестирования улучшенных систем. В долгосрочной перспективе такие инструменты могут значительно упростить экспертам отслеживание литературы по раку и превращение новых открытий в более качественное лечение.
Цитирование: Hossain, E., Nuzhat, T., Masum, S. et al. R-GAT: cancer document classification leveraging graph-based residual network for scenarios with limited data. Sci Rep 16, 6582 (2026). https://doi.org/10.1038/s41598-026-39894-6
Ключевые слова: информатика рака, горное извлечение биомедицинских текстов, классификация документов, графовые нейронные сети, обучение при ограниченных данных