Clear Sky Science · ru
Автоматическое обнаружение конусных фоторецепторов с использованием синтетических данных и глубокого обучения на изображениях конфокального адаптивного оптического оптического сканирующего офтальмоскопа
Более четкое представление о живом глазе
Возможность видеть светочувствительные клетки глаза поштучно может изменить способы выявления и наблюдения заболеваний, ведущих к слепоте. Сегодня эксперты вынуждены вручную отмечать эти клетки на сильно увеличенных изображениях сетчатки — процесс медленный, субъективный и трудный для масштабирования на тысячи пациентов. В этом исследовании показано, как компьютерные модели, обученные на реалистичных «фейковых» изображениях глаза, могут автоматически находить эти клетки, открывая путь к более быстрым и надежным обследованиям и лучшей оценке новых методов лечения.
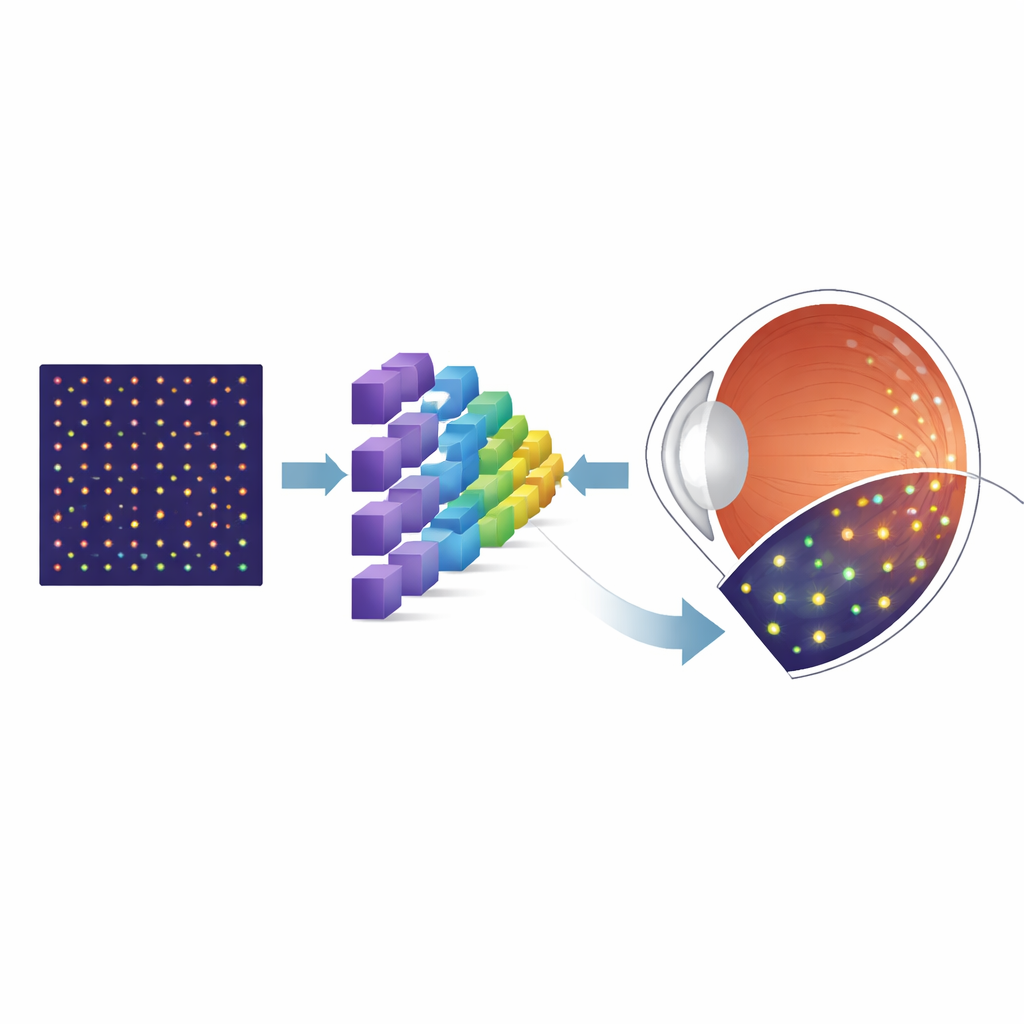
Почему важны крошечные клетки
Задняя часть глаза покрыта фоторецепторами — специализированными клетками, которые превращают свет в сигналы, которые наш мозг воспринимает как зрение. Конусные фоторецепторы особенно важны для острого центрального зрения и восприятия цвета, и их утрата является характерным признаком многих заболеваний сетчатки. Мощная технология визуализации, называемая адаптивной оптической сканирующей лазерной офтальмоскопией (AOSLO), позволяет получать детализированные снимки этих клеток у живых людей. Однако прежде чем врачи и исследователи смогут измерять плотность конусов или отслеживать изменения со временем, им необходимо точно определить местоположение каждой отдельной клетки на изображении. Ручное разметка занимает много времени и может различаться у разных людей, что ограничивает её применимость в рутинных клиниках и крупных испытаниях.
От правил, созданных вручную, к обучению на данных
Ранние компьютерные программы пытались автоматизировать обнаружение конусов, следуя фиксированным правилам: например, искать яркие точки определенного размера или расстояния друг от друга. Эти методы на основе правил могли хорошо работать на чистых изображениях здоровых глаз, но часто испытывали трудности, когда изображения были шумными, слегка размытыми или получены у пациентов с заболеваниями. Глубокое обучение предлагает иной подход. Вместо ручной разработки правил нейронная сеть учится распознавать закономерности непосредственно по примерам. Загвоздка в том, что такие модели обычно требуют огромного числа изображений с точной разметкой экспертами — именно таких данных в AOSLO немного и их получение дорогостояще.
Создание виртуальной тренировочной площадки
Чтобы обойти нехватку размеченных реальных изображений, исследователи обратились к симулятору под названием ERICA, который может генерировать реалистичные AOSLO-подобные изображения мозаики конусов вместе с идеальной «эталонной» информацией о положении каждой клетки. Они создали большие наборы таких синтетических изображений, охватывающие разные участки сетчатки, систематически варьируя ключевые дефекты, влияющие на реальные снимки — например, случайный шум и тонкое оптическое размытие. Затем они обучили специализированную архитектуру нейронной сети, известную как U-Net, преобразовывать входное изображение в карту вероятностей, показывающую, где с наибольшей вероятностью расположены конусы. После первоначального обучения на синтетических данных команда дообучила модель на гораздо меньшей коллекции реальных AOSLO-изображений из хорошо известного публичного набора, а затем протестировала её на независимых изображениях из другой лаборатории, чтобы проверить обобщаемость.

Насколько хорошо компьютер соответствует экспертам-человекам
Команда сравнила автоматизированный метод с кропотливой ручной разметкой и с двумя ведущими алгоритмами обнаружения конусов. Используя стандартную меру совпадения между предсказанными и ручными метками конусов, новый U-Net соответствовал или почти соответствовал результатам как экспертных градеров, так и конкурирующих автоматических методов на публичном наборе данных. Важный итог: при тестировании на отдельном наборе изображений, снятых на разных расстояниях от центра зрения и собранных на другом приборе, модель по-прежнему показывала высокую производительность. Это указывает на то, что интенсивное обучение на синтетических данных, охватывающих широкий диапазон визуальных условий, помогло сети выучить признаки, переносимые на реальные изображения, а не переобучиться под одну конкретную камеру или группу пациентов.
Что это может означать для будущей офтальмологии
Для неспециалистов основной вывод таков: компьютерная программа, в основном обученная на «виртуальных» изображениях глаза, теперь может находить настоящие конусные клетки на высокоразрешающих снимках сетчатки примерно с той же надежностью, что и человеческие эксперты. Ускоряя, делая более объективным и легче применимым в разных сканерах и клиниках процесс обнаружения конусов, этот подход может помочь превратить детализированную визуализацию сетчатки в рутинный инструмент для отслеживания заболеваний на уровне отдельных клеток. В долгосрочной перспективе аналогичные методы, основанные на синтетических данных, могут быть расширены для обнаружения других типов клеток и моделирования их утраты при заболеваниях, поддерживая более раннюю диагностику, лучшее наблюдение за прогрессированием и более точную оценку новых методов лечения, направленных на сохранение зрения.
Цитирование: Shah, M., Young, L.K., Downes, S.M. et al. Automated cone photoreceptor detection using synthetic data and deep learning in confocal adaptive optics scanning laser ophthalmoscope images. Sci Rep 16, 8313 (2026). https://doi.org/10.1038/s41598-026-39570-9
Ключевые слова: изображение сетчатки, конусные фоторецепторы, глубокое обучение, синтетические данные, адаптивная оптика