Clear Sky Science · ru
Эффективная по данным 3D медицинская модель «видение—язык», использующая только 2D-энкодер
Более умная поддержка на основе 3D-сканов
Когда врачи читают КТ или МРТ, они смотрят не на отдельные снимки, а мысленно собирают сотни срезов, чтобы понять проблему в трёх измерениях. Научив компьютеры делать то же самое, можно было бы ускорить и унифицировать постановку диагноза и получить более понятные отчёты для пациентов. Но современные системы искусственного интеллекта, работающие с 3D-исследованиями, крайне «прожорливы» к данным: им нужны огромные, тщательно размеченные наборы данных, которых во многих больницах просто нет. В этой работе предложен способ получить понимание на уровне 3D, используя уже развитые 2D-технологии, что обещает мощные инструменты, которые проще и дешевле строить и внедрять.
Почему 3D-сканы трудны для ИИ
Современные системы «видение–язык» уже умеют анализировать 2D-медицинское изображение и отвечать на вопросы или составлять отчёт понятным языком. Расширение этой возможности на 3D-объёмы позволило бы ИИ рассуждать о целых органах и тонких поражениях, которые становятся очевидными только при просмотре множества срезов вместе. Проблема в том, что большинство текущих 3D-систем опираются на специальные 3D-энкодеры, обученные с нуля на гигантских коллекциях размеченных сканов. Такие наборы данных редки, дороги в аннотации и часто сосредоточены в богатых научных центрах, что ограничивает круг тех, кто может ими воспользоваться. В то же время простая обработка каждого среза как отдельного 2D-изображения теряет естественную непрерывность между срезами и захлёстывает модель повторяющейся информацией.
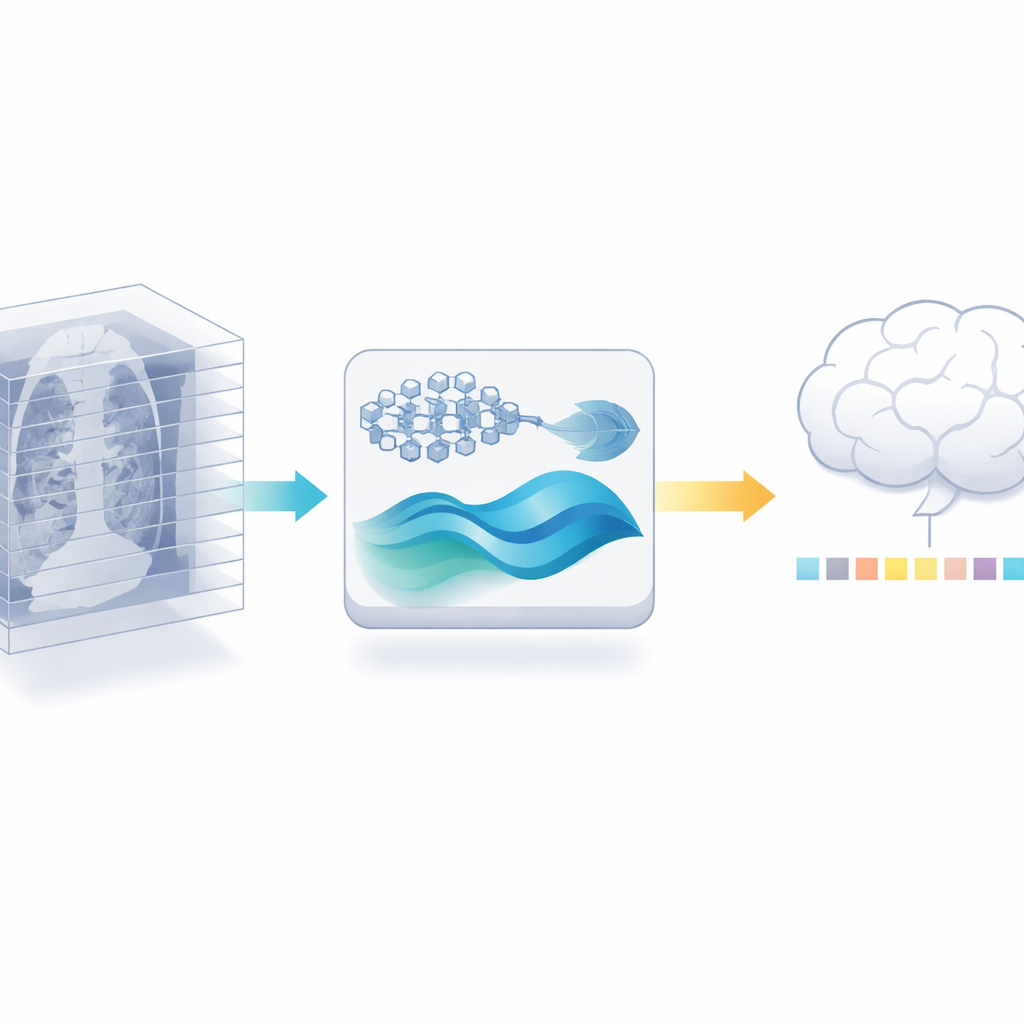
Переработка 2D-эксперта для 3D-задач
Авторы предлагают другой путь: вместо обучения нового 3D-энкодера они повторно используют мощную 2D-модель медицинских изображений, уже обученную на миллионах размеченных изображений из медицинской литературы. Сначала они разрезают каждый 3D-скан на отдельные срезы и позволяют этой 2D-модели извлечь детальные признаки с каждого снимка. Затем они аккуратно сокращают избыточность: поскольку соседние срезы часто выглядят практически одинаково, проверка на сходство позволяет отбросить многие почти дубликаты и при этом сохранить наиболее информативные виды. Этот шаг сам по себе уменьшает объём данных для последующих этапов, не требуя дополнительных размеченных сканов.
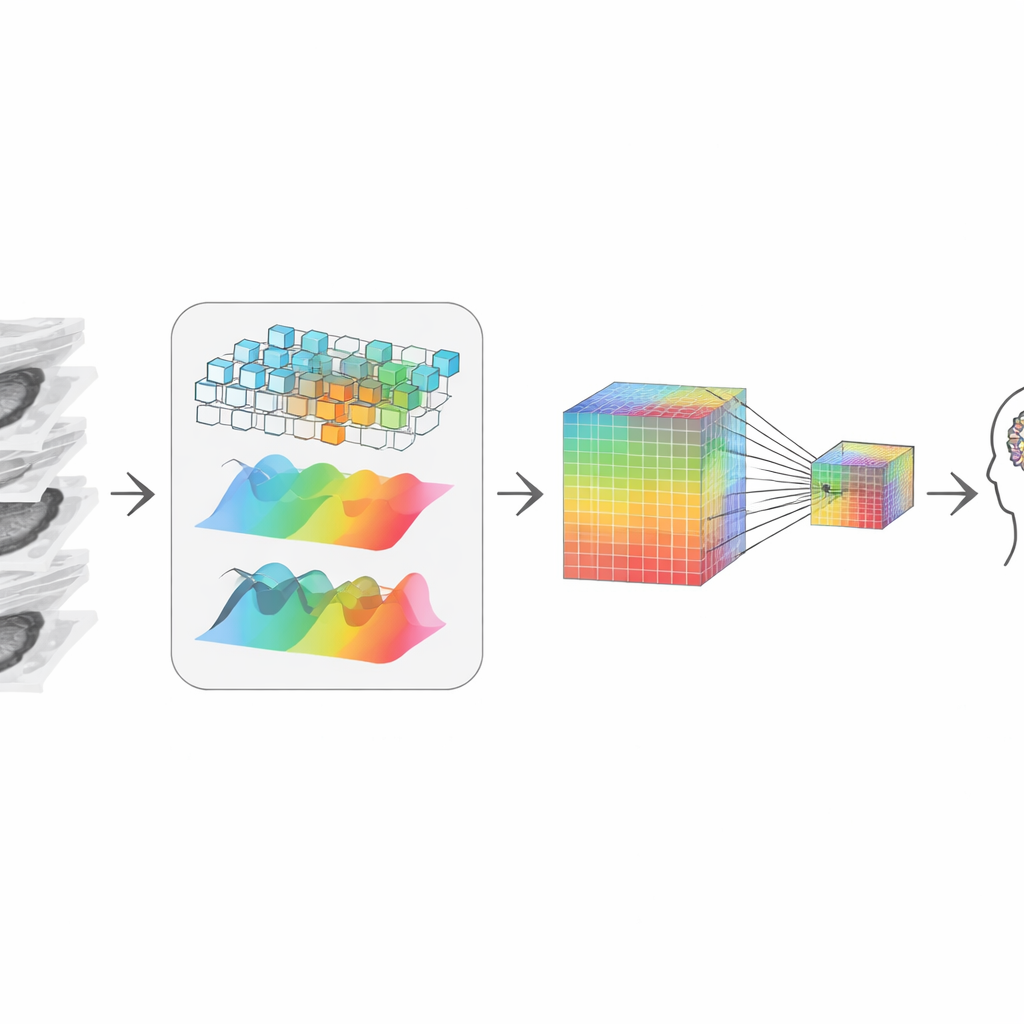
Воссоздание 3D-истории из фрагментов
После отсева система должна «сшить» оставшиеся срезы в связную 3D-картину. Авторы делают это, сочетая два дополняющих друг друга представления данных. Один путь фокусируется на локальных формах и границах, словно лупа, проходящая через объём, чувствительная к чётким контурам и текстурам. Другой путь переводит данные в частотное представление, лучше улавливающее широкие закономерности и дальнодействующую структуру между срезами — как растёт опухоль или как в целом сформирован орган. Адаптивный шаг слияния обучается тому, сколько доверять каждому виду в каждой точке, давая представление, которое учитывает и мелкие детали, и глобальный контекст, несмотря на исходную 2D-природу срезов.
Сохранение крошечных указаний при сжатии
Чтобы взаимодействовать с большой языковой моделью — той частью, которая отвечает на вопросы и пишет отчёты — визуальная информация должна быть сжата в умеренное число токенов, или «визуальных слов». Простейшее ужатие размоет крошечные, но критически важные сигналы, такие как мелкие кальцинаты или едва заметные изменения текстуры, важные для диагноза. Чтобы этого избежать, авторы создают двухдорожечное представление: одна дорожка хранит высокоразрешённую версию, богатую деталями, а вторая — меньшую, более экономичную. Механизм внимания позволяет каждой точке в компактной версии избирательно «обращаться» к большой версии и подтягивать самые резкие доступные детали. В результате получается компактное визуальное резюме, которое по-прежнему несёт подсказки, важные радиологу, и затем передаётся языковой модели для рассуждения.
Доказательство в реальных медицинских задачах
Для проверки конструкции исследователи оценили её на публичных 3D-бенчмарках, которые ставят две основные задачи: может ли система составлять точные радиологические описания 3D-сканов и может ли она отвечать на вопросы о том, что видно на них? Их подход, несмотря на отсутствие обучения специфическому 3D-энкодеру, превзошёл несколько сильных 3D-ориентированных моделей в обеих задачах. Он генерировал более точные, клинически насыщенные отчёты и давал более точные ответы на вопросы, включая сложные о конкретном органе, патологии или локализации. Система также работала быстрее, требовала гораздо меньше 3D-данных для обучения и хорошо обобщалась на разные типы сканов, такие как МРТ и ПЭТ.
Что это значит для будущей помощи в медицине
Проще говоря, эта работа показывает, что не обязательно начинать с нуля и использовать «прожорливые» 3D-модели, чтобы получить качественную помощь ИИ при анализе объёмных исследований. За счёт умного повторного использования сильного 2D-эксперта, тщательного отбора информативных срезов и восстановления 3D-картины с сохранением мелких деталей, авторы достигают передовых результатов при значительно меньших затратах данных и вычислений. При широком распространении такой подход мог бы сделать продвинутую ИИ-помощь — более точные отчёты, понятные объяснения и надёжную сортировку случаев — доступной для больниц и клиник, лишённых массивных наборов данных, приближая сложный анализ изображений к повседневной клинической практике.
Цитирование: Lian, Y., Xie, Y., Jiang, Y. et al. A data-efficient 3D medical vision-language model using only a 2D encoder. Sci Rep 16, 8809 (2026). https://doi.org/10.1038/s41598-026-39526-z
Ключевые слова: 3D медицинская визуализация, модели видение–язык, радиологический ИИ, обучение с экономией данных, анализ КТ и МРТ