Clear Sky Science · ru
Оценка производительности больших видео‑языковых моделей в качестве научно‑популярных видео о сухом глазе
Почему это важно для обычных зрителей
Приложения с короткими видео стремительно становятся первым источником советов по здоровью, включая проблемы с глазами, такие как сухой глаз, которым страдают сотни миллионов людей по всему миру. Но наряду с полезными роликами легко встретить материалы низкого качества или вводящие в заблуждение, и врачам трудно контролировать это. В этом исследовании поставлен вопрос: могут ли новые системы искусственного интеллекта, умеющие «смотреть» видео, помогать автоматически проверять качество таких роликов, и показано, почему на данный момент такие инструменты не готовы заменить экспертную оценку.
Сухой глаз и рост числа медицинских видео
Сухой глаз — это не просто мелкое неудобство; он может вызывать затуманивание зрения, боль и мешать работе и повседневной жизни. По мере того как состояние становится более распространённым, особенно среди пожилых людей и интенсивных пользователей экранов, многие ищут в интернете объяснения и советы по самообслуживанию. Платформы вроде TikTok полны коротких роликов о сухом глазе, но открытый характер сервисов означает, что любой может публиковать контент независимо от медицинского образования. Плохие или преувеличенные советы могут отсрочить правильное лечение или привести к опасным домашним методам, поэтому крайне необходимы надёжные способы проверки качества видео в масштабах.
Как исследователи тестировали AI‑рецензентов видео
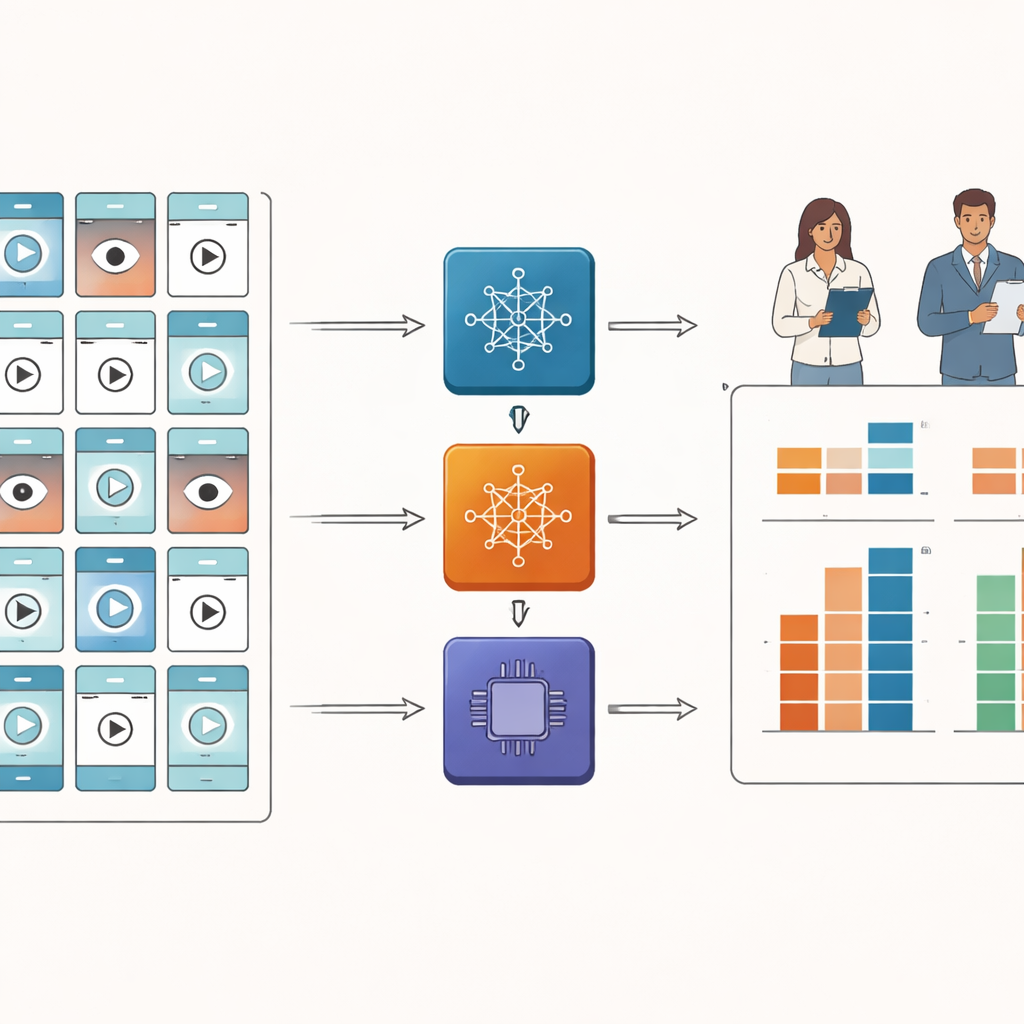
Команда собрала 185 видео на китайском языке о сухом глазе с TikTok, используя новый нейтральный аккаунт и строгие правила, чтобы оставить только оригинальные образовательные ролики. Два офтальмолога затем оценили каждое видео по трём устоявшимся инструментам, часто применяемым в исследованиях медицинского образования. Один инструмент оценивал, насколько видео понятны и насколько чётко в них предлагались конкретные шаги для зрителей. Второй давал общую оценку качества от плохого до отличного. Третий разбивал качество по аспектам, таким как плавность подачи информации, точность, как хорошо использовались дополнительные элементы вроде анимаций и насколько содержание соответствовало заголовку видео.
Испытание «видео‑грамотных» AI‑моделей
Затем исследователи пропустили те же видео через три продвинутые «большие видео‑языковые модели» — AI‑системы, разработанные для посимвольного/покадрового анализа визуальной информации и ответов на вопросы о том, что они видят. Они подготовили подробные инструкции, чтобы каждая модель как можно точнее имитировала врачебные инструменты оценки. Ключевой вопрос заключался в том, будут ли AI и человеческие эксперты ставить похожие оценки. Для измерения этого команда использовала стандартную статистику надёжности, показывающую, насколько близки соглашения между двумя «судьями», не только по тенденциям, но и по абсолютным значениям.
Что AI сделал правильно — и что нет
Человеческие рецензенты в основном соглашались друг с другом, что говорит о стабильности и надёжности их оценок. Напротив, три AI‑системы показали низкое согласие с экспертами в большинстве областей. Ни одна из моделей не смогла надёжно соответствовать врачам по общей оценке качества видео или по детализированным характеристикам, таким как соответствие заголовка содержанию. Одна модель склонялась к более высоким оценкам, чем эксперты, другая — к более низким, а только одна иногда оказывалась между ними. Единственным относительным достижением была «практичность» — насколько ясно в видео говорилось, что нужно сделать — где две модели достигли среднего уровня согласия, но всё ещё не на том уровне, который был бы достаточен для принятия решений в реальном мире.
Почему современный AI отстаёт
Авторы предлагают несколько причин этому разрыву. Тестируемые AI‑системы в основном обучались на бытовых сценах и общих видео‑задачах, а не на структурированном медицинском образовании. Многие научно‑популярные ролики опираются в большой степени на устные объяснения, субтитры, диаграммы и метафоры, а не на эффектные движущиеся изображения; однако модели в этом исследовании анализировали только визуальные кадры и не слушали аудио и не читали заголовки или другие описательные данные, которыми люди пользуются при оценке релевантности и точности. В результате значительные части смысла не доходили до AI, особенно когда ключевые детали были произнесены, а не показаны. Фигуральный язык, распространённый в китайских образовательных видео, также может сбивать с толку системы, склонные к буквальной интерпретации высказываний.
Что это значит для пациентов и платформ
Эта работа даёт раннюю дорожную карту, но не готовую сетку безопасности. Она показывает, что в принципе знакомые чек‑листы качества медицинской информации можно перевести в инструкции для AI‑моделей, которые «смотрят» видео. Одновременно исследование ясно показывает, что современные универсальные системы ещё недостаточно надёжны, чтобы оценивать медицинские видео или контролировать дезинформацию без участия человека. Выпустив свою оценочную рамку и аннотированный набор видео, авторы надеются стимулировать создание более специализированных моделей, которые смогут объединять визуальный ряд, звук и дополнительный контекст и работать для разных заболеваний и языков. Пока же зрителям следует рассматривать короткие медицинские видео как отправную точку, а не как медицинский совет, а платформам не стоит полагаться только на AI в вопросах проверки достоверности информации.
Цитирование: Zhou, S., Huang, M., Wei, J. et al. Benchmark evaluation of video large language models in quality assessment of science popularization videos for dry eye. Sci Rep 16, 8756 (2026). https://doi.org/10.1038/s41598-026-39444-0
Ключевые слова: сухой глаз, медицинские видео, искусственный интеллект, дезинформация, TikTok