Clear Sky Science · ru
CGDFNet: двухветвивая сеть для семантической сегментации в реальном времени с контекстно‑руководимой фьюзией деталей
Обучение автомобилей видеть всю улицу
Современные автомобили и роботы все чаще полагаются на камеры, чтобы понимать окружающий мир — распознавать дороги, тротуары, людей, транспорт и знаки в реальном времени. В этой работе представлен CGDFNet, новая система компьютерного зрения, спроектированная для такого «понимания сцены» быстрее и точнее, особенно на оживленных городских улицах. Обучаясь одновременно сохранять как тонкие детали (например, столбы светофоров или колеса велосипедов), так и общую картину (дороги и здания), CGDFNet стремится сделать автоматизированное вождение и другие задачи визуального восприятия в реальном времени безопаснее и надежнее.
Почему пиксельное зрение настолько требовательно
В семантической сегментации компьютер присваивает категорию каждому пикселю изображения: дорога, автомобиль, пешеход, небо и т. д. Это гораздо более требовательно, чем простое обведение машины рамкой, поскольку системе нужно точно проследить границы объектов и мелкие формы. Существуют методы с высокой точностью, но они, как правило, медленные и энергоемкие, что плохо подходит для систем реального времени в автомобилях, дронах или носимых устройствах. С другой стороны, легковесные методы, работающие быстро, часто жертвуют деталями или теряют общую структуру сцены, испытывая трудности с мелкими объектами, тонкими структурами или плотными городскими сценами.
Два пути: для деталей и для контекста
CGDFNet решает эту проблему с помощью двухветвевой архитектуры: одна ветвь фокусируется на четких деталях, другая — на широком контексте. На базе эффективного бэкбона нижние слои направляют информацию в «ветвь деталей», которая сохраняет более высокое разрешение для удержания краев и текстур. Глубокие слои питают «ветвь контекста», рассматривающую сцену более сжато — это хорошо для понимания общей структуры и взаимосвязей между объектами. В отличие от предыдущих двухветвевых схем, которые в основном держат потоки раздельными и затем грубо складывают результаты, CGDFNet поощряет обмен информацией между ветвями на протяжении всей обработки, так что тонкие детали постоянно соотносятся с тем, что сеть знает об общей сцене.
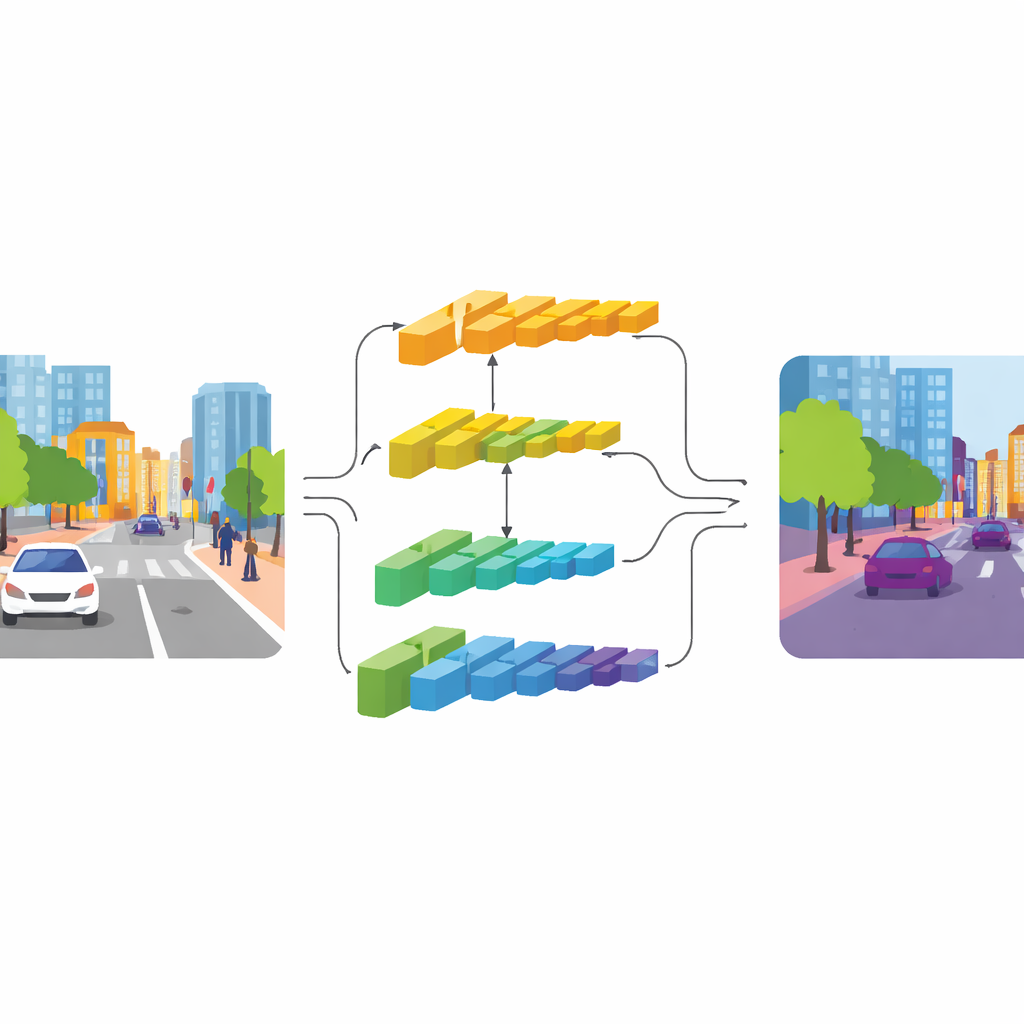
Направляя детали через смысл
Два ключевых компонента усиливают это взаимодействие. В ветви контекста Модуль семантического уточнения (Semantic Refinement Module) учится выделять наиболее информативные области и каналы в своих признаковых картах. Он делает это, сочетая локальные сигналы (какие части сцены активны рядом друг с другом) и глобальные сигналы (что сеть видит по всему изображению), так что представление содержит и суседные детали, и смысл на уровне сцены. В ветви деталей Модуль контекстно‑управляемых деталей (Context‑Guided Detail Module) использует эту семантическую информацию, чтобы направлять внимание на контуры и тонкие структуры, которые имеют значение — например очертания автобуса или раму велосипеда. Он опирается на особый тип свертки, более чувствительный к изменениям между соседними пикселями, что естественным образом усиливает контуры и мелкие объекты без существенного увеличения числа параметров.
Смешивание информации в частотном мире
Отличительная особенность CGDFNet — способ объединения двух ветвей. Вместо простого сложения карт в пространственной области авторы разработали Модуль адаптивной фьюзии в частотной области (Fourier‑Domain Adaptive Fusion Module). Этот модуль временно преобразует объединенные признаки в частотную область, где паттерны представлены в виде медленных, широких вариаций и быстрых, резких изменений. Адаптивный механизм затворов затем учится, какие частотные компоненты усиливать из ветви деталей, а какие — из ветви контекста. После такого взвешивания признаки преобразуются обратно, что дает представление, более эффективно объединяющее резкие края и согласованную глобальную структуру, чем традиционные фьюзии, работающие только в пространственной области.
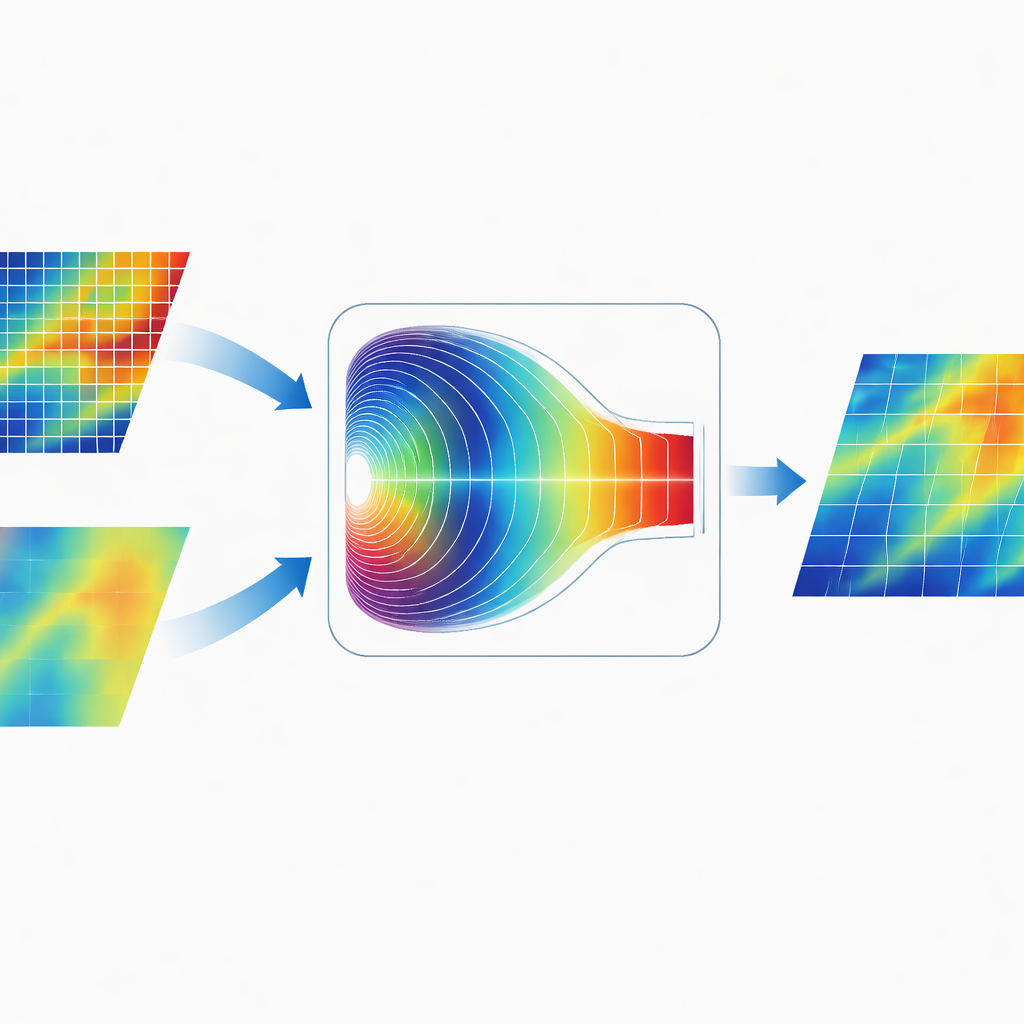
Результаты на реальных улицах
Авторы протестировали CGDFNet на двух широко используемых бенчмарках городских сцен: Cityscapes, собранном в европейских городах, и CamVid, захваченном с водительской перспективы в Великобритании. CGDFNet обрабатывал крупные изображения в режиме реального времени — примерно 88 кадров в секунду на Cityscapes и около 129 кадров в секунду на CamVid — при этом достигая точности сегментации, сопоставимой или превосходящей многие современные системы. Он показал особенно хорошие результаты по категориям, которые обычно трудно сегментировать, таким как заборы, дорожные знаки, автобусы и велосипеды, где сохранение точных границ и мелких структур критично.
Что это значит для повседневных технологий
Практически CGDFNet демонстрирует, что возможно создать системы зрения, одновременно достаточно быстрые для работы в реальном времени и достаточно тщательные, чтобы сохранять мелкие, важные для безопасности детали в сложных городских сценах. Сочетая ветвь, ориентированную на детали, ветвь, ориентированную на контекст, и интеллектуальный шаг фьюзии в частотной области, сеть сохраняет сбалансированное видение улицы: она знает, где что находится и где начинается и заканчивается каждый объект. Хотя остаются задачи — например, тесные скопления людей или плохая погода — этот подход предлагает перспективную схему для будущих решений на устройстве: от самоуправляемых автомобилей до умных уличных камер и вспомогательных роботов.
Цитирование: Zhao, S., Fu, W., Gao, J. et al. CGDFNet: a dual-branch real-time semantic segmentation network with context-guided detail fusion. Sci Rep 16, 9191 (2026). https://doi.org/10.1038/s41598-026-39370-1
Ключевые слова: семантическая сегментация в реальном времени, зрение для автономного вождения, двухветвивая нейросеть, фьюзия признаков в частотной области, понимание городских сцен