Clear Sky Science · ru
Разбор адресов пациентов с помощью контрастного обучения с учётом графа знаний и локального ограниченного вывода LLM
Почему аккуратные адреса пациентов важны
За каждым визитом в больницу часто скрывается простая строка текста: домашний адрес пациента. Это далеко не просто канцелярская деталь — адреса служат основой для картирования распространения заболеваний, планирования экстренных служб и решений о размещении клиник и машин скорой помощи. Однако во многих медицинских системах адреса сохраняются как беспорядочный, непоследовательный текст, полный аббревиатур, опечаток и пропусков. В этой статье представлен AddrKG‑LLM — новый метод, который превращает такой неуклюжий адресный текст в чистые, надёжные записи, при этом сохраняя конфиденциальность чувствительных данных.
Проблема небрежно записанных домашних адресов
Когда адрес вводят свободно, люди опускают районы, меняют порядок слов или используют локальные прозвища, которые официальные карты не распознают. Старые компьютерные методы сравнивают строки посимвольно или как простые списки слов, и это работает лишь когда ввод уже аккуратен и полон. Новые глубокие модели лучше учитывают контекст, но все еще могут спотыкаться на нетипичных формулировках и требуют больших вычислительных ресурсов. В последнее время большие языковые модели продемонстрировали впечатляющую способность понимать и генерировать текст. Тем не менее при свободном ответе они склонны «галлюцинировать» — придумывать детали, которых нет в данных, — что недопустимо в здравоохранении, где записи должны быть точными и проверяемыми.
Двухэтапный путь от хаоса к порядку
Исследователи разработали AddrKG‑LLM как двухступенчатый конвейер, который добавляет структуру и ограничители вокруг языковой модели, вместо того чтобы полагаться на неё в одиночку. Сначала входящие адреса пациентов очищают от сильно идентифицирующих деталей, таких как номера домов и комнат и контактные телефоны, что помогает защитить приватность. Оставшийся текст преобразуют в плотное числовое представление, фиксирующее его смысл. Параллельно строят граф знаний — сетевую карту, кодирующую официальные связи между городами, районами, улицами и жилыми сообществами. С помощью приёма, называемого контрастным обучением, систему обучают так, чтобы адреса, относящиеся к одной и той же реальной местности, располагались близко в этом общем пространстве, тогда как несвязанные места отталкивались дальше друг от друга. Это позволяет системе быстро извлекать короткий список вероятных кандидатов на адрес для каждой новой записи пациента.
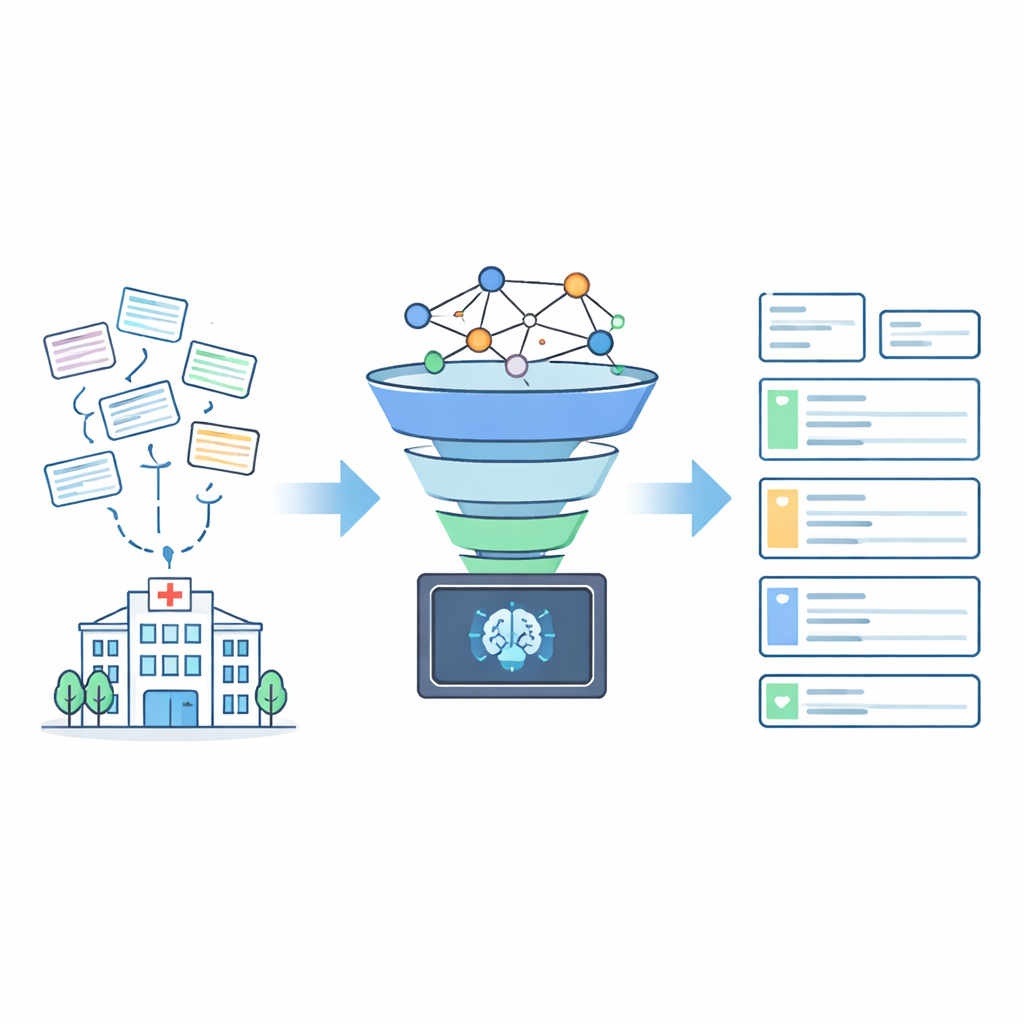
Держать ИИ на коротком поводке
На втором этапе большая языковая модель работает внутри тщательно огороженного пространства поиска. Вместо того чтобы придумывать адрес «с нуля», модель получает исходный очищенный текст и небольшой набор кандидатов сообществ, предложенных графом знаний. В подсказке явно указывается, что модель должна выбирать только из этих кандидатов и выводить результаты в фиксированной JSON‑структуре с отдельными полями для города, района, улицы или посёлка и сообщества. Если ни один из кандидатов не подходит — например, когда истинное сообщество вообще не было извлечено — модель просят вернуть пустые значения, а не угадывать. Такое поведение «с отказом по умолчанию» резко снижает риск появления звучащих правдоподобно, но неверных записей в медицинских картотеках.
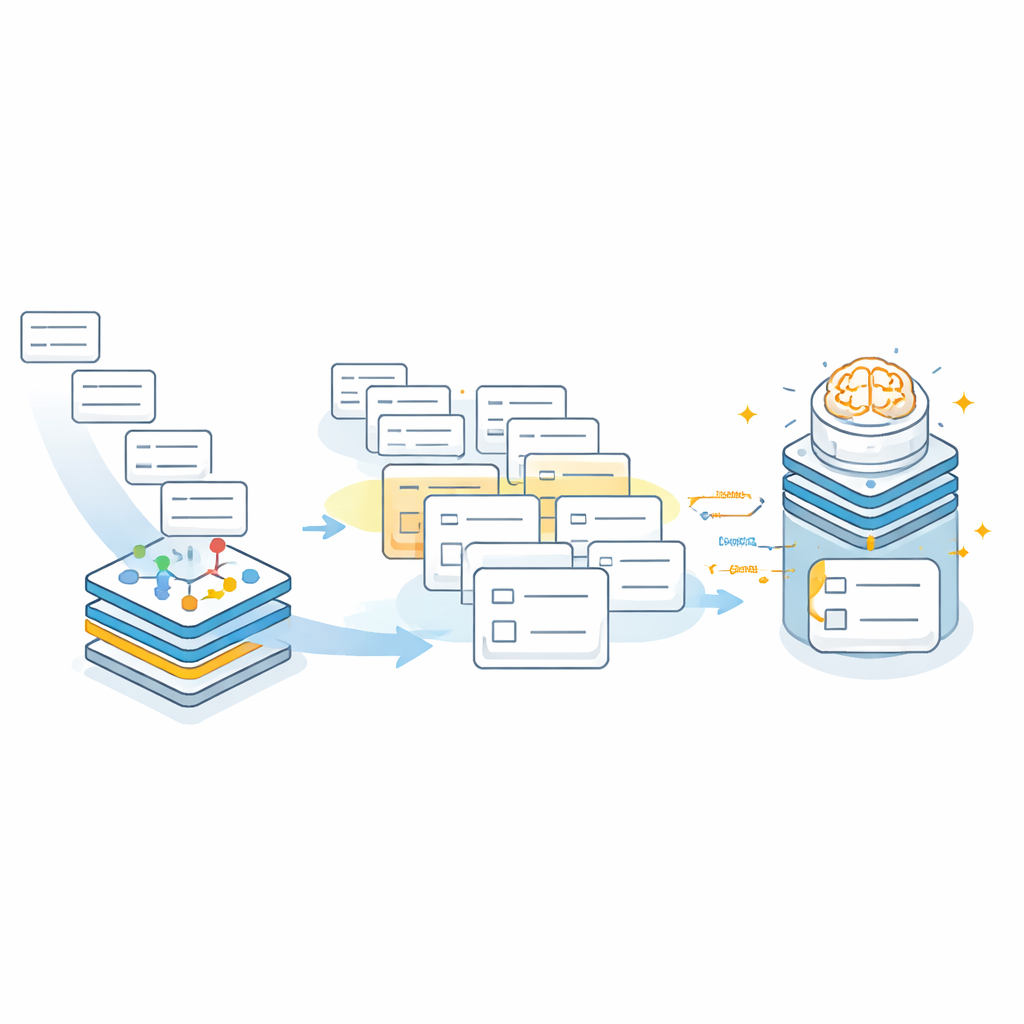
Как это работает на практике?
Команда протестировала AddrKG‑LLM на десяти тысячах де‑идентифицированных реальных адресов из больниц, отражающих реальные шумы: аббревиатуры, пропущенные районы, варианты написания и даже полностью неверные записи. Они сравнили свою систему с классическими инструментами сопоставления строк, моделями маркировки последовательностей на основе глубокого обучения, общими языковыми моделями, используемыми в свободной форме, и коммерческим сервисом стандартизации адресов. По строгим метрикам, требующим корректности всех полей адреса одновременно, AddrKG‑LLM превзошёл все эти базовые методы, увеличив общую точность более чем на двенадцать процентных пунктов по сравнению с сильной моделью на основе BERT. Преимущества были особенно заметны для сокращённых и частично неполных адресов, где иерархия графа знаний помогает заполнять пропуски. Авторы также исследовали, как меняется производительность при использовании моделей разных размеров и при разном числе извлекаемых кандидатов, показывая, как больницы могут настраивать компромисс между скоростью и точностью под свои нужды.
Что это значит для повседневной помощи
Для неспециалистов ключевое сообщение такое: AddrKG‑LLM предлагает способ привести в порядок жизненно важные, но неаккуратные адресные данные пациентов, сохраняя при этом контроль в руках людей. Совмещая карту‑подобный граф знаний с ограниченной языковой моделью, работающей полностью на серверах больницы, этот подход даёт более точные и согласованные адреса, не отправляя чувствительные данные в облачные сервисы и не позволяя ИИ импровизировать. В результате получается практичный инструмент, который может усилить эпиднадзор, улучшить планирование ресурсов и поддержать более безопасную и эффективную работу больниц — просто за счёт того, что каждый пациент оказывается надёжно отображён на карте.
Цитирование: Li, J., Pan, X. & Jia, Y. Patient address parsing via KG-aware contrastive learning and constrained on-prem LLM inference. Sci Rep 16, 8003 (2026). https://doi.org/10.1038/s41598-026-39348-z
Ключевые слова: разбор адресов пациентов, качество медицинских данных, граф знаний, большая языковая модель, медицинская информатика