Clear Sky Science · ru
Топологически-маскированное предсказание движения скелета и контрастивное обучение для самообучающегося распознавания человеческих действий
Научить компьютеры читать язык тела
От видеодомофонов до умных реабилитационных инструментов — многим современным системам нужно понимать, что люди делают, просто наблюдая за их движениями. Но обучение компьютеров распознаванию человеческих действий обычно требует огромных, тщательно размеченных наборов данных, где каждый взмах, удар или рукопожатие аннотированы вручную. В этом исследовании предложен способ, позволяющий машинам учиться по сырым данным о движении, используя только движущийся скелет тела — без меток, без лиц и без полноцветного видео — что делает распознавание действий точнее, конфиденциальнее и гораздо менее зависимым от дорогой человеческой разметки.
Почему достаточно только скелета
Вместо анализа полноценных видеокадров метод работает с 3D-данными скелета: координатами ключевых суставов, таких как плечи, локти, бедра и колени во времени. Такое минималистичное представление тела имеет несколько преимуществ. Оно в значительной степени обходится без проблем конфиденциальности, потому что лица и одежда удалены, и при этом достаточно компактно для эффективной обработки, даже при длинных записях. Скелет устойчив к загроможденному фону и изменениям освещения, которые могут сбивать с толку обычные видео-системы. Однако большинство существующих подходов на основе скелета все же сильно зависят от размеченных примеров и испытывают трудности с полным улавливанием того, как суставы взаимодействуют в сложных, скоординированных действиях.
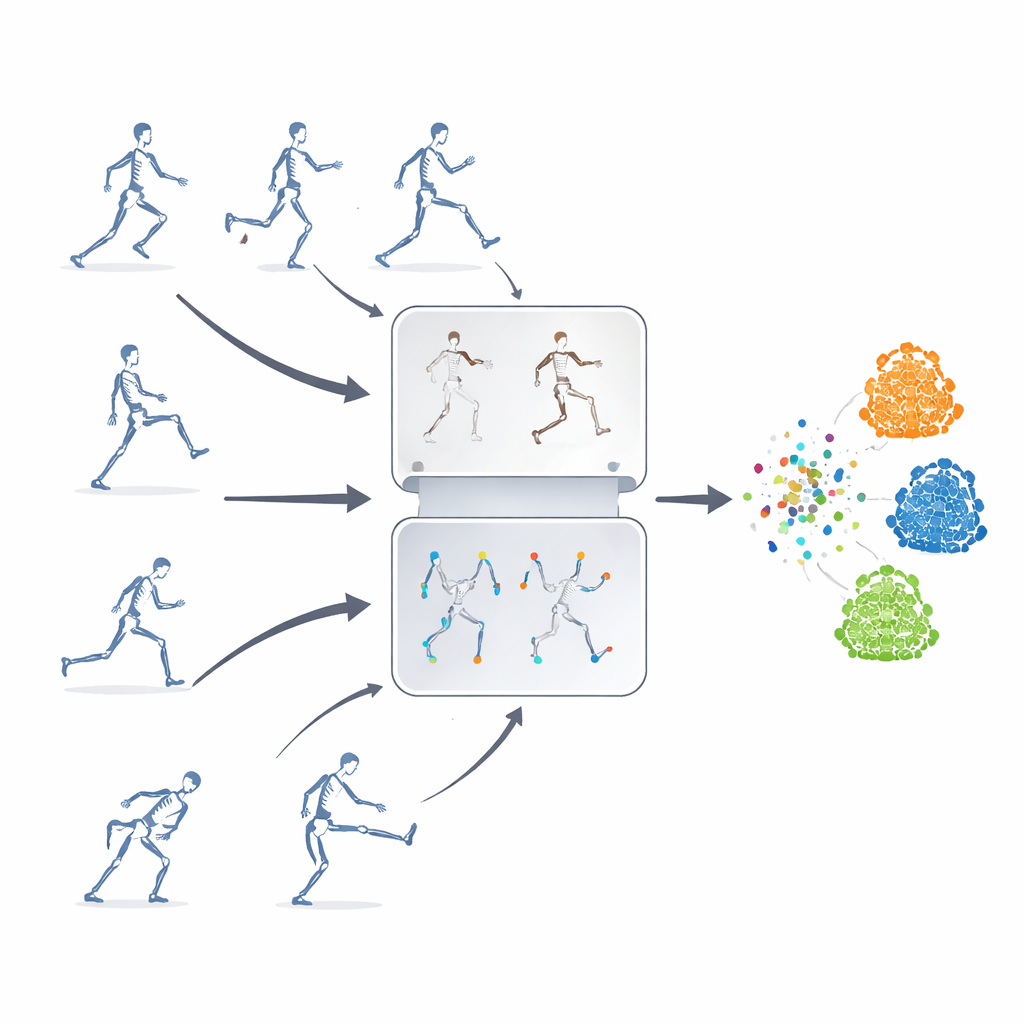
Обучение без меток
Авторы предлагают фреймворк самообучения, то есть систему, которая учится на немаркированных последовательностях скелета. Ключевая идея — объединить две мощные стратегии, которые обычно используются по отдельности. Первая — «маскированное предсказание», при котором части данных скелета целенаправленно скрываются, и модель должна угадать пропущенное движение по оставшемуся контексту. Вторая — «контрастивное обучение», когда модели показывают несколько искажённых версий одного и того же действия и учат распознавать, что эти вариации представляют одно и то же базовое движение. Сочетая эти подходы, система осваивает как тонкие детали движения суставов, так и общее смысловое значение действия.
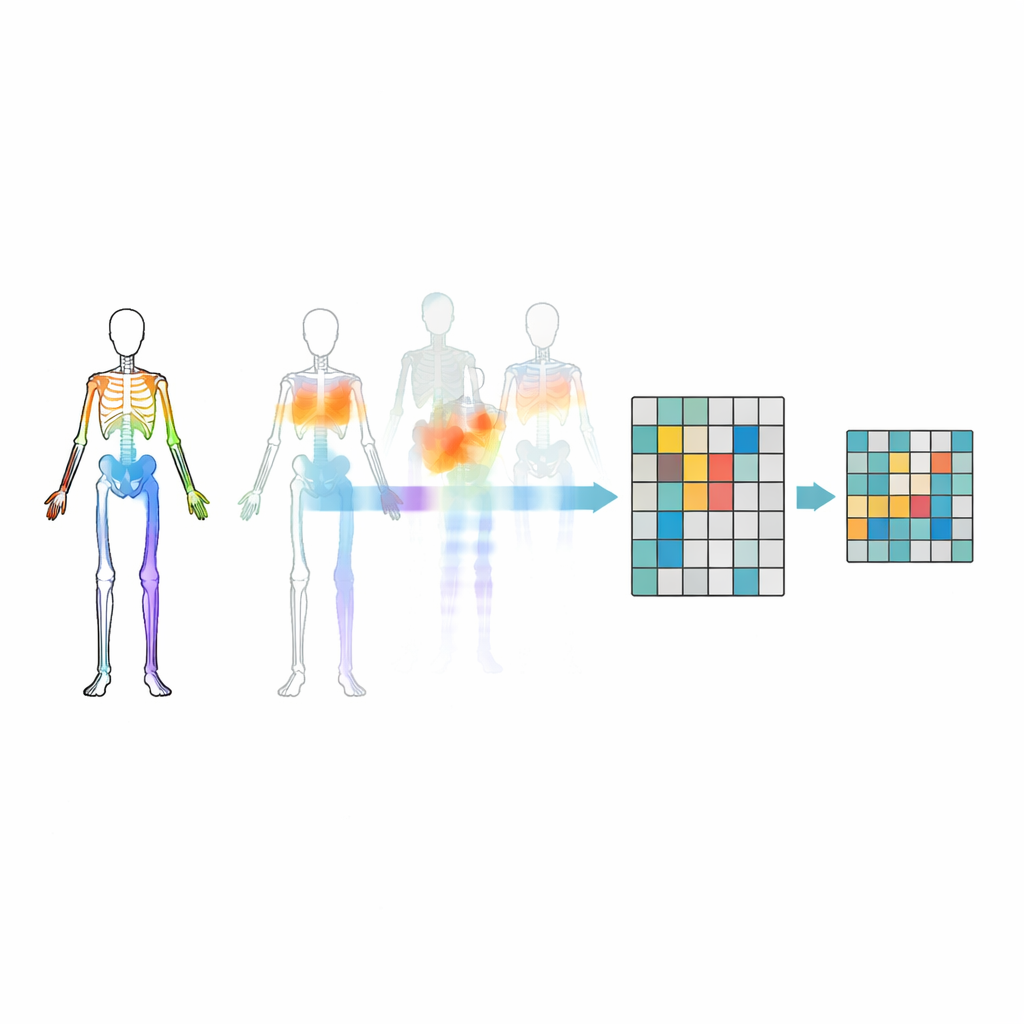
Скрывать правильные суставы
Просто случайно маскировать суставы недостаточно — модель может игнорировать важные взаимосвязи между частями тела или зацикливаться на наиболее заметном движении. Чтобы избежать этого, исследователи вводят стратегию маскирования, основанную на движении и топологии. Они группируют суставы в осмысленные области тела, такие как руки, ноги и корпус, затем измеряют, насколько сильно каждая область движется во времени. Решения о маскировании руководствуются как структурой тела, так и интенсивностью движения каждой области, так что иногда скрываются наиболее активные части и модель вынуждена восстанавливать их по остальной части тела. Такое целенаправленное скрытие помогает системе изучать, как суставы взаимодействуют во время действий, а не просто запоминать несколько эффектных движений.
Растянуть действие множеством способов
Для обучения контрастивной части системы одна и та же исходная последовательность скелета преобразуется во множество различных «видов». Некоторые изменения мягкие — например, обрезка временного окна или небольшая деформация траектории — в то время как другие более экстремальны, включая зеркальные отражения, повороты и сильный шум. Эти многоуровневые аугментации демонстрируют модели богатое разнообразие шаблонов движения, поощряя её фокусироваться на основной структуре действия, а не на поверхностных деталях. Одновременно модуль подавления признаков, управляемый траекторией, отслеживает, на каких признаках движения модель опирается сильнее всего, и намеренно их подавляет во время обучения. Временно лишая её привычных подсказок, система вынуждена находить запасные признаки и вырабатывать более общие, переносимые представления.
Насколько хорошо это работает?
Фреймворк протестирован на трёх крупных публичных бенчмарках 3D-человеческих действий, охватывающих повседневные поведения, медицинские движения и взаимодействия между людьми. Несмотря на то, что он использует только данные скелетных суставов и относительно лёгкую рекуррентную нейросеть, метод сопоставим с лучшими современными системами или превосходит их, даже если те опираются на более сложные входы или архитектуры. Он особенно хорошо проявляет себя при дефиците разметки или при частичной окклюзии частей тела — условиях, которые часто возникают в реальных средах. Хотя способность к переносу знаний между очень разными наборами данных всё ещё требует улучшения, подход заметно сокращает разрыв между обучением с метками и без меток для распознавания действий.
Что это значит для реальных систем
Для неспециалиста главное в том, что эта работа показывает: компьютеры могут гораздо лучше «читать» язык тела людей, не получая явных указаний о значении каждого движения. За счёт умного скрытия и искажения данных скелета во время обучения модель выучивает устойчивые закономерности движения, которые сохраняются при плохом освещении, визуальном шуме или отсутствии некоторых суставов, и делает это с гораздо меньшим объёмом человеко-генерируемых меток. Это открывает дорогу более приватным, масштабируемым и адаптируемым системам распознавания действий для приложений от домашнего мониторинга и спортивного тренинга до медицинской реабилитации и взаимодействия человека с роботом.
Цитирование: Hui, Y., Li, F., Hu, X. et al. Skeleton motion topology-masked prediction and contrastive learning for self-supervised human action recognition. Sci Rep 16, 8100 (2026). https://doi.org/10.1038/s41598-026-39330-9
Ключевые слова: распознавание действий человека, 3D-данные скелета, самообучение, контрастивное обучение, анализ движения