Clear Sky Science · ru
Использование большой языковой модели для улучшения рассуждений другой большой языковой модели с помощью обновляемого вознаграждения GRPO
Обучение машин продуманному мышлению
Многие современные языковые модели умеют вести диалог, переводить и отвечать на вопросы, но им по-прежнему сложно показывать ход рассуждений так, как это сделал бы хороший ученик по математике или внимательный аналитик. В этой работе исследуется, как одна система искусственного интеллекта может улучшать навыки рассуждения другой и как сделать это без ручной подготовки огромных специализированных наборов данных. Для читателей, интересующихся тем, как ИИ может стать более надежным в таких областях, как финансы, медицина или научные исследования, работа предлагает практическую методику, позволяющую моделям яснее и последовательнее объяснять свои ответы.
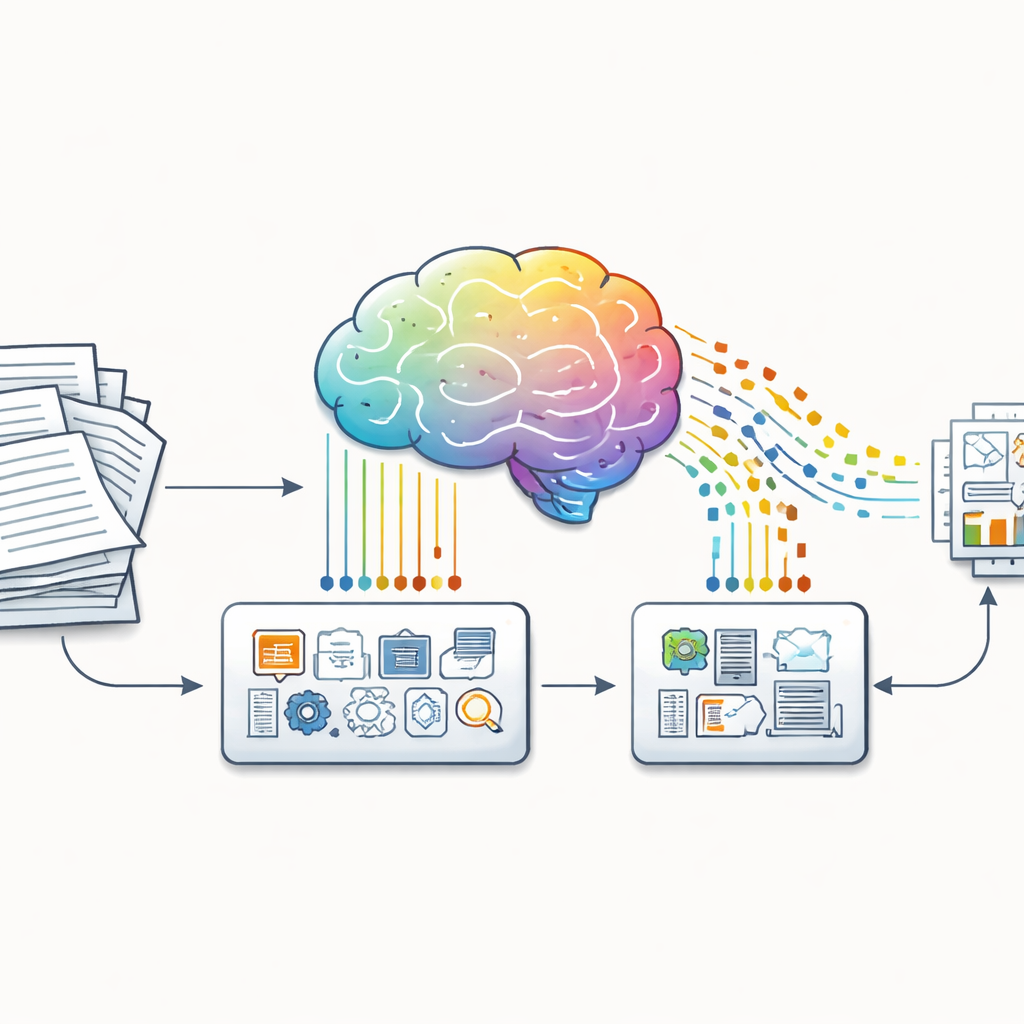
От сырых документов к учебным примерам
Авторы исходят из простого наблюдения: большая часть реальной информации хранится в неаккуратных формах — отчётах, посланиях акционерам или веб-страницах — а не в удобном формате «вопрос–ответ». Чтобы преодолеть этот разрыв, они представляют два программных инструмента: Huggify-Data и CoT Data Generator. Эти инструменты берут неструктурированный текст и автоматически превращают его в пары «вопрос–ответ», а затем просят мощную языковую модель заполнить недостающие шаги рассуждения между ними. В результате для каждого примера получается структурированный триплет: вопрос, цепочка рассуждений и ответ. Важно, что этот конвейер можно направить практически на любую предметную область — от школьной математики до корпоративных финансов — что делает возможным создание тренировочных данных, ориентированных на рассуждение, без армий человеческих аннотаторов.
Как одна модель обучает другую
После создания триплетов «вопрос–рассуждение–ответ» их используют для обучения более компактной «студенческой» модели мыслить в той же структурированной манере. У студента просят не только дать итоговый ответ, но и сформулировать чётко отделённое объяснение, а затем вывод. Обучение ведётся с помощью метода, называемого Group Relative Policy Optimization, который сравнивает несколько кандидатных ответов на один и тот же вопрос и подталкивает модель к более удачным. В статье этот метод дополняется дополнительным членом вознаграждения, который проверяет, следует ли вывод модели желаемому формату, вплоть до степени соответствия хорошо оформленному эталонному примеру. Это вознаграждение мягко штрафует спутанные или неполные объяснения, стимулируя модель к аккуратным, интерпретируемым ответам.
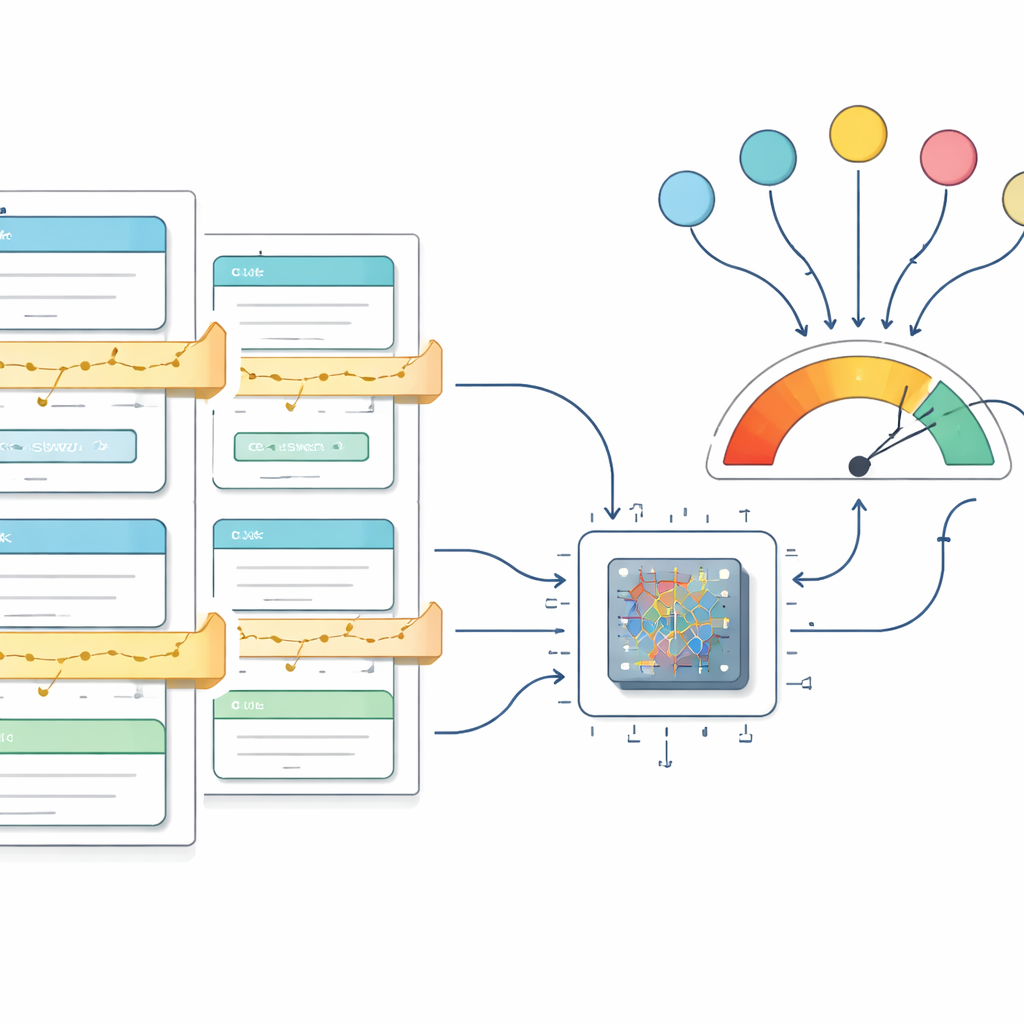
Испытание подхода на практике
Чтобы проверить работоспособность фреймворка, авторы применяют его к двум принципиально разным наборам данных. Первый, GSM8K, состоит из текстовых задач начальной школы, требующих многошаговых арифметических рассуждений. Второй набор собран из ежегодных писем Уоррена Баффетта акционерам, где цель — зафиксировать развернутые рассуждения об инвестициях и корпоративных решениях. В обоих случаях конвейер превращает необработанный текст в структурированные тренировочные данные и дообучает модель среднего размера под названием Qwen 2.5. В процессе обучения простое правило начисления очков вознаграждает корректные, хорошо оформленные ответы; по мере обучения среднее вознаграждение неуклонно растёт и стабилизируется на теоретическом максимуме, что показывает: модель в значительной степени овладела целевым поведением на тренировочных данных.
Насколько хорошо работает улучшенная модель
Эффективность измеряется с помощью «средней точности по токенам», которая, в общих чертах, показывает, какая доля мелких фрагментов текста (токенов) в выводе модели совпадает с ожидаемой. Хотя это отличается от привычной оценки «всё или ничего» для тестовых ответов, метрика хорошо подходит для оценки того, соблюдается ли требуемая структура объяснений и ответов. На GSM8K лучшая модель достигает 98,2% точности по токенам, а на письмах Баффетта — 98,5%. Эти показатели выше, чем у широко известных систем, таких как GPT‑4 и Claude 3.5 Sonnet по той же метрике, при этом используется всего 3‑миллиардная модель, которую можно обучить менее чем за два дня на арендованном оборудовании. Авторы также приводят детали о вычислительных затратах и конфигурациях железа, а также публикуют весь код, модели и наборы данных для ознакомления и дальнейшей работы.
Что это означает для повседневного использования ИИ
Для неспециалистов главный вывод таков: ИИ можно научить не просто отвечать, а отвечать дисциплинированно и легко для понимания, используя данные, автоматически извлечённые из обычных документов. Комбинируя модель‑учителя с богатым рассуждением, гибкий конвейер обработки данных и схему вознаграждения, ценящую и правильность, и ясность, авторы показывают, как формировать из компактных моделей более надёжных решателей задач. Хотя они отмечают ограничения — например, потребность в более строгих тестах на подлинное понимание и безопасность — предложенный фреймворк указывает на будущее, в котором организации смогут превращать свои текстовые архивы в адаптированные и прозрачные ИИ‑ассистенты для образования, финансов и других сфер.
Цитирование: Yin, Y. Use large language model to enhance reasoning of another large language model through reward updated GRPO. Sci Rep 16, 8360 (2026). https://doi.org/10.1038/s41598-026-39296-8
Ключевые слова: большие языковые модели, пошаговое рассуждение, оптимизация вознаграждения, курирование данных, отраслевой искусственный интеллект